KernelBlaster: Continual Cross-Task CUDA Optimization via Memory-Augmented In-Context Reinforcement Learning
作者: Kris Shengjun Dong, Sahil Modi, Dima Nikiforov, Sana Damani, Edward Lin, Siva Kumar Sastry Hari, Christos Kozyrakis
分类: cs.LG, cs.AI
发布日期: 2026-02-15
备注: 15 pages, 33 pages with appendix
💡 一句话要点
KernelBlaster:通过内存增强的上下文强化学习实现CUDA跨任务持续优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CUDA优化 强化学习 大型语言模型 代码生成 GPU架构 持续学习 知识库
📋 核心要点
- 现有CUDA优化方法难以跨多代GPU架构实现最佳性能,传统编译器启发式固定,LLM微调成本高昂,Agent工作流知识聚合能力有限。
- KernelBlaster提出内存增强的上下文强化学习框架,构建持久CUDA知识库,使Agent能从经验学习,系统性地进行CUDA优化决策。
- 实验表明,KernelBlaster在KernelBench上相比PyTorch基线实现了显著的性能提升,几何平均加速分别达到1.43x、2.50x和1.50x。
📝 摘要(中文)
在多个GPU架构上优化CUDA代码极具挑战,因为达到最佳性能需要在日益复杂的、特定于硬件的优化空间中进行广泛探索。传统编译器受限于固定的启发式方法,而微调大型语言模型(LLM)的成本可能很高。然而,用于CUDA代码优化的Agent工作流在聚合先前探索的知识方面能力有限,导致有偏采样和次优解决方案。我们提出了KernelBlaster,一个内存增强的上下文强化学习(MAIC-RL)框架,旨在提高基于LLM的GPU编码Agent的CUDA优化搜索能力。KernelBlaster通过将知识积累到可检索的持久CUDA知识库中,使Agent能够从经验中学习,并对未来的任务做出系统性的知情决策。我们提出了一种新颖的、基于profile引导的、基于文本梯度的Agent流程,用于CUDA生成和优化,以在多个GPU架构上实现高性能。KernelBlaster引导LLM Agent系统地探索超出简单重写的高潜力优化策略。与PyTorch基线相比,我们的方法在KernelBench Levels 1、2和3上分别实现了1.43倍、2.50倍和1.50倍的几何平均加速。我们将KernelBlaster作为开源Agent框架发布,并附带测试工具、验证组件和可复现的评估流程。
🔬 方法详解
问题定义:论文旨在解决CUDA代码在不同GPU架构上的优化问题。现有方法,如传统编译器和直接微调LLM,无法有效地探索复杂的优化空间。传统编译器依赖固定的启发式规则,缺乏适应性;而微调LLM成本高昂,且难以泛化到新的架构。此外,现有的基于Agent的工作流在利用历史经验方面存在不足,导致采样偏差和次优结果。
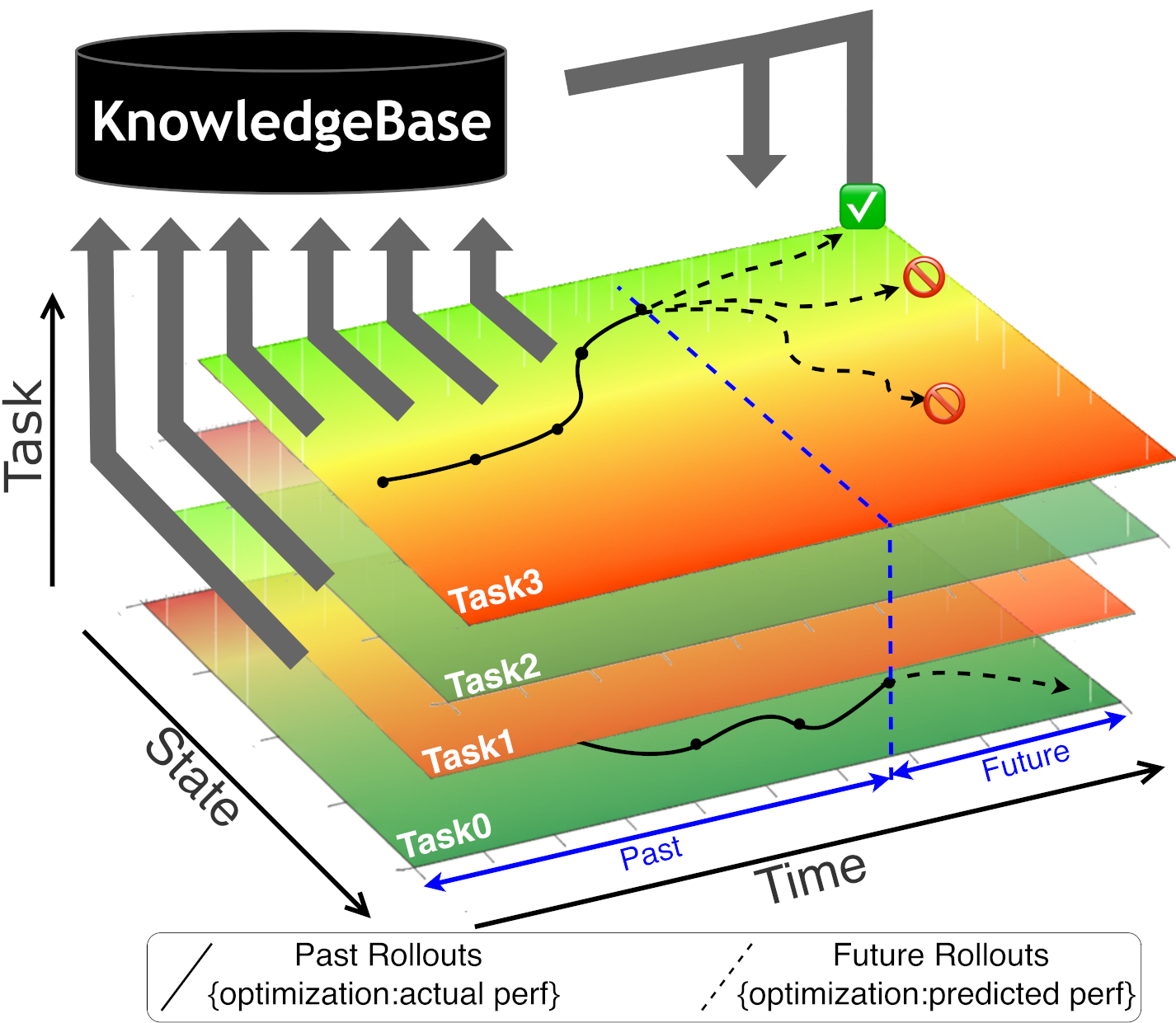
核心思路:KernelBlaster的核心思路是利用内存增强的上下文强化学习(MAIC-RL)框架,构建一个持久的CUDA知识库。Agent通过与环境交互,不断积累CUDA优化经验,并将这些经验存储在知识库中。在面对新的CUDA优化任务时,Agent可以从知识库中检索相关信息,从而做出更明智的决策,避免重复探索,提高优化效率。
技术框架:KernelBlaster框架包含以下主要模块:1) Agent:基于LLM的智能体,负责生成和优化CUDA代码。2) Persistent CUDA Knowledge Base:持久CUDA知识库,用于存储Agent的优化经验。3) Profile-Guided Textual-Gradient-Based Agentic Flow:基于profile引导和文本梯度的Agent流程,用于指导Agent进行CUDA代码生成和优化。该流程利用性能profile信息和文本梯度信息,帮助Agent识别潜在的优化机会。4) Environment:CUDA代码执行环境,用于评估Agent生成的代码的性能。
关键创新:KernelBlaster的关键创新在于将内存增强的上下文强化学习应用于CUDA代码优化。通过构建持久的CUDA知识库,Agent可以有效地利用历史经验,避免重复探索,提高优化效率。此外,基于profile引导和文本梯度的Agent流程能够更有效地指导Agent进行CUDA代码生成和优化。
关键设计:KernelBlaster的关键设计包括:1) 知识库的构建:知识库存储Agent的优化经验,包括CUDA代码片段、性能指标和优化策略。2) 检索机制:Agent使用相似度匹配算法从知识库中检索相关信息。3) 奖励函数:奖励函数用于评估Agent生成的代码的性能,并指导Agent进行优化。4) 文本梯度计算:利用文本梯度信息,帮助Agent识别潜在的优化机会。
🖼️ 关键图片

📊 实验亮点
KernelBlaster在KernelBench数据集上进行了评估,结果表明,与PyTorch基线相比,KernelBlaster在KernelBench Levels 1、2和3上分别实现了1.43倍、2.50倍和1.50倍的几何平均加速。这些结果表明,KernelBlaster能够有效地优化CUDA代码,并在多个GPU架构上实现高性能。
🎯 应用场景
KernelBlaster可应用于各种需要高性能CUDA代码的领域,如深度学习、科学计算、图像处理等。通过自动优化CUDA代码,KernelBlaster可以显著提高应用程序的性能,降低开发成本,并加速新算法的部署。未来,该技术有望扩展到其他编程语言和硬件平台,实现更广泛的自动化代码优化。
📄 摘要(原文)
Optimizing CUDA code across multiple generations of GPU architectures is challenging, as achieving peak performance requires an extensive exploration of an increasingly complex, hardware-specific optimization space. Traditional compilers are constrained by fixed heuristics, whereas finetuning Large Language Models (LLMs) can be expensive. However, agentic workflows for CUDA code optimization have limited ability to aggregate knowledge from prior exploration, leading to biased sampling and suboptimal solutions. We propose KernelBlaster, a Memory-Augmented In-context Reinforcement Learning (MAIC-RL) framework designed to improve CUDA optimization search capabilities of LLM-based GPU coding agents. KernelBlaster enables agents to learn from experience and make systematically informed decisions on future tasks by accumulating knowledge into a retrievable Persistent CUDA Knowledge Base. We propose a novel profile-guided, textual-gradient-based agentic flow for CUDA generation and optimization to achieve high performance across generations of GPU architectures. KernelBlaster guides LLM agents to systematically explore high-potential optimization strategies beyond naive rewrites. Compared to the PyTorch baseline, our method achieves geometric mean speedups of 1.43x, 2.50x, and 1.50x on KernelBench Levels 1, 2, and 3, respectively. We release KernelBlaster as an open-source agentic framework, accompanied by a test harness, verification components, and a reproducible evaluation pipeline.