Whom to Query for What: Adaptive Group Elicitation via Multi-Turn LLM Interactions
作者: Ruomeng Ding, Tianwei Gao, Thomas P. Zollo, Eitan Bachmat, Richard Zemel, Zhun Deng
分类: cs.LG, cs.AI, cs.CL, cs.SI
发布日期: 2026-02-15
💡 一句话要点
提出基于多轮LLM交互的自适应群体信息获取方法,解决预算约束下的群体属性推断问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应信息获取 群体属性推断 大型语言模型 图神经网络 多轮交互
📋 核心要点
- 现有群体信息获取方法在 respondent 选择上存在局限,无法有效处理数据缺失和预算约束问题。
- 该论文提出了一种自适应群体信息获取框架,利用 LLM 和图神经网络进行问题选择和 respondent 选择。
- 实验结果表明,该方法在真实数据集上,能够在有限预算下显著提升群体层面响应预测的准确性。
📝 摘要(中文)
为了在调查和其他集体评估中,以有限的提问成本和缺失数据为前提,获取信息以减少对潜在群体层面属性的不确定性,本文研究了自适应群体信息获取。现有方法通常优化提问内容,但 respondent 选择固定,且在响应不完整时无法利用群体结构。为此,本文提出了一个理论框架,结合了(i)基于LLM的期望信息增益目标,用于对候选问题进行评分,以及(ii)异构图神经网络传播,用于聚合观察到的响应和参与者属性,以填补缺失的响应并指导每轮 respondent 选择。该闭环程序在通过结构化相似性推断群体层面响应的同时,查询一小部分信息量大的个体。在三个真实世界的观点数据集上,该方法在受限预算下持续改进群体层面响应预测,在10%的 respondent 预算下,在CES数据集上实现了超过12%的相对增益。
🔬 方法详解
问题定义:论文旨在解决在预算有限和数据缺失的情况下,如何有效地从人群中获取信息,以准确推断群体的整体属性。现有方法的痛点在于,它们通常采用固定的 respondent 集合,无法根据已收集的信息动态调整提问对象,也难以有效利用人群的结构化信息来填补缺失数据,导致信息获取效率低下。
核心思路:论文的核心思路是构建一个自适应的提问框架,该框架能够根据已收集的 respondent 响应和人群的结构化信息,动态地选择最有价值的问题和 respondent。通过迭代地提问和推断,该框架能够在预算约束下最大化信息增益,从而更准确地推断群体的整体属性。
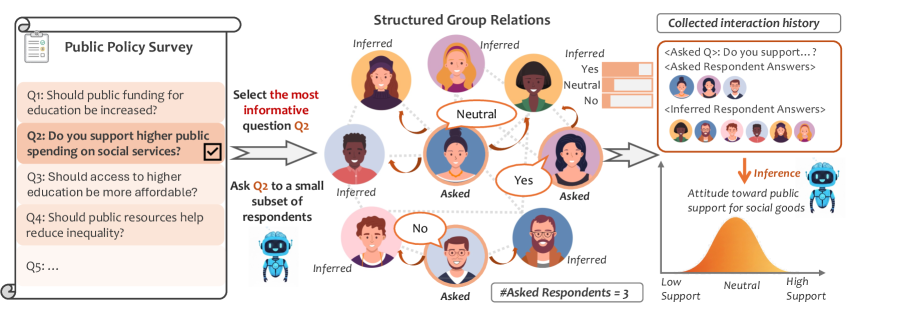
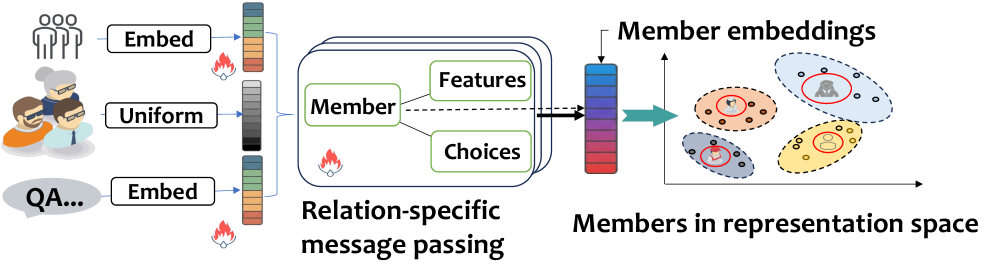
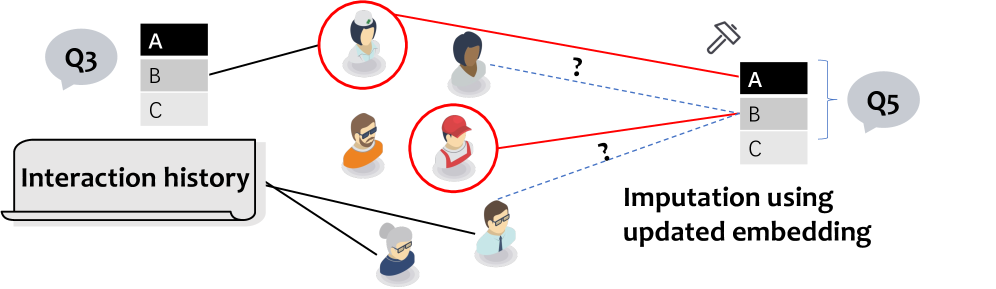
技术框架:整体框架是一个多轮迭代过程,主要包含以下模块:1) 问题选择:利用 LLM 对候选问题进行评分,选择期望信息增益最大的问题。2) Respondent 选择:利用异构图神经网络,根据已观察到的响应和参与者属性,预测缺失的响应,并选择信息量最大的 respondent。3) 响应收集:向选定的 respondent 提问,收集他们的响应。4) 信息聚合:将收集到的响应和参与者属性输入到图神经网络中,更新对群体属性的推断。
关键创新:该论文的关键创新在于将 LLM 和图神经网络相结合,实现自适应的问题和 respondent 选择。LLM 用于评估问题的价值,而图神经网络用于预测缺失的响应和选择信息量大的 respondent。这种结合使得该框架能够有效地利用人群的结构化信息,并在预算约束下最大化信息增益。
关键设计:在问题选择方面,论文使用 LLM 计算每个候选问题的期望信息增益,并选择增益最大的问题。在 respondent 选择方面,论文构建了一个异构图神经网络,该网络将参与者和问题作为节点,将响应和参与者属性作为边,利用图神经网络进行信息传播,预测缺失的响应,并根据预测结果选择信息量最大的 respondent。损失函数的设计目标是最小化预测响应与真实响应之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在三个真实世界的观点数据集上,能够在受限预算下持续改进群体层面响应预测。在10%的 respondent 预算下,该方法在CES数据集上实现了超过12%的相对增益。这表明该方法能够有效地利用人群的结构化信息,并在预算约束下最大化信息增益。
🎯 应用场景
该研究成果可应用于民意调查、市场调研、公共卫生监测等领域。通过自适应地选择提问对象和问题,可以在有限的预算下更准确地了解人群的观点和行为,为决策提供更可靠的依据。未来,该方法还可以扩展到其他领域,例如推荐系统和个性化学习,以提高信息获取的效率和准确性。
📄 摘要(原文)
Eliciting information to reduce uncertainty about latent group-level properties from surveys and other collective assessments requires allocating limited questioning effort under real costs and missing data. Although large language models enable adaptive, multi-turn interactions in natural language, most existing elicitation methods optimize what to ask with a fixed respondent pool, and do not adapt respondent selection or leverage population structure when responses are partial or incomplete. To address this gap, we study adaptive group elicitation, a multi-round setting where an agent adaptively selects both questions and respondents under explicit query and participation budgets. We propose a theoretically grounded framework that combines (i) an LLM-based expected information gain objective for scoring candidate questions with (ii) heterogeneous graph neural network propagation that aggregates observed responses and participant attributes to impute missing responses and guide per-round respondent selection. This closed-loop procedure queries a small, informative subset of individuals while inferring population-level responses via structured similarity. Across three real-world opinion datasets, our method consistently improves population-level response prediction under constrained budgets, including a >12% relative gain on CES at a 10% respondent budget.