Radial-VCReg: More Informative Representation Learning Through Radial Gaussianization
作者: Yilun Kuang, Yash Dagade, Deep Chakraborty, Erik Learned-Miller, Randall Balestriero, Tim G. J. Rudner, Yann LeCun
分类: cs.LG
发布日期: 2026-02-15
备注: Published in the Unifying Representations in Neural Models (UniReps) and Symmetry and Geometry in Neural Representations (NeurReps) Workshops at NeurIPS 2025
💡 一句话要点
提出Radial-VCReg,通过径向高斯化学习更具信息量的自监督表征
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 表征学习 高斯化 维度灾难 信息最大化
📋 核心要点
- 自监督学习中,直接最大化信息量因维度灾难而受限,现有方法如VCReg无法充分实现最大熵。
- Radial-VCReg通过径向高斯化损失,使特征范数与高维高斯分布的卡方分布对齐,增强VCReg。
- 实验表明,Radial-VCReg能有效减少高阶依赖,提升表征的多样性和信息量,从而提高性能。
📝 摘要(中文)
自监督学习旨在学习最大化信息量的表征,但显式的信息最大化受到维度灾难的阻碍。现有的方法,如VCReg,通过正则化一阶和二阶特征统计量来解决这个问题,但无法完全实现最大熵。我们提出了Radial-VCReg,它通过径向高斯化损失来增强VCReg,该损失将特征范数与卡方分布对齐——这是高维高斯分布的一个决定性属性。我们证明,与VCReg相比,Radial-VCReg将更广泛的分布类别转化为正态分布,并在合成和真实世界的数据集上表明,它通过减少高阶依赖性和促进更多样化和信息丰富的表征,从而持续提高性能。
🔬 方法详解
问题定义:自监督学习旨在学习信息量最大的表征,但直接最大化信息量会受到维度灾难的影响。现有的方法,例如VCReg,通过正则化特征的一阶和二阶统计量来近似最大熵,但这种方法无法完全消除高阶依赖,从而限制了表征的信息量。因此,如何更有效地学习到更具信息量且更鲁棒的表征是该论文要解决的核心问题。
核心思路:论文的核心思路是通过径向高斯化,使学习到的特征分布更接近高维高斯分布。高维高斯分布的一个关键特性是其特征范数服从卡方分布。因此,论文通过引入一个径向高斯化损失,将特征的范数与卡方分布对齐,从而促使特征分布更接近高维高斯分布。这种方法旨在减少特征之间的高阶依赖,并鼓励学习到更多样化和信息丰富的表征。
技术框架:Radial-VCReg建立在VCReg的基础上,整体框架与VCReg类似,包括一个编码器网络和一个损失函数。编码器网络将输入数据映射到特征空间。损失函数由两部分组成:VCReg损失和径向高斯化损失。VCReg损失用于正则化特征的一阶和二阶统计量,而径向高斯化损失则用于将特征范数与卡方分布对齐。整个训练过程通过最小化总损失函数来优化编码器网络。
关键创新:该论文的关键创新在于引入了径向高斯化损失,这是与现有方法(如VCReg)的本质区别。VCReg仅正则化特征的一阶和二阶统计量,而Radial-VCReg进一步正则化特征的范数,使其服从卡方分布。这种径向高斯化能够更有效地减少高阶依赖,并促进学习到更接近高维高斯分布的表征。
关键设计:径向高斯化损失的关键设计在于如何衡量特征范数与卡方分布之间的差异。论文采用了一种基于KL散度的损失函数,用于衡量特征范数的经验分布与卡方分布之间的差异。具体来说,论文首先计算特征范数的经验分布,然后计算卡方分布的概率密度函数,最后使用KL散度来衡量这两个分布之间的差异。此外,论文还对卡方分布的参数进行了调整,以适应不同的特征维度。
🖼️ 关键图片
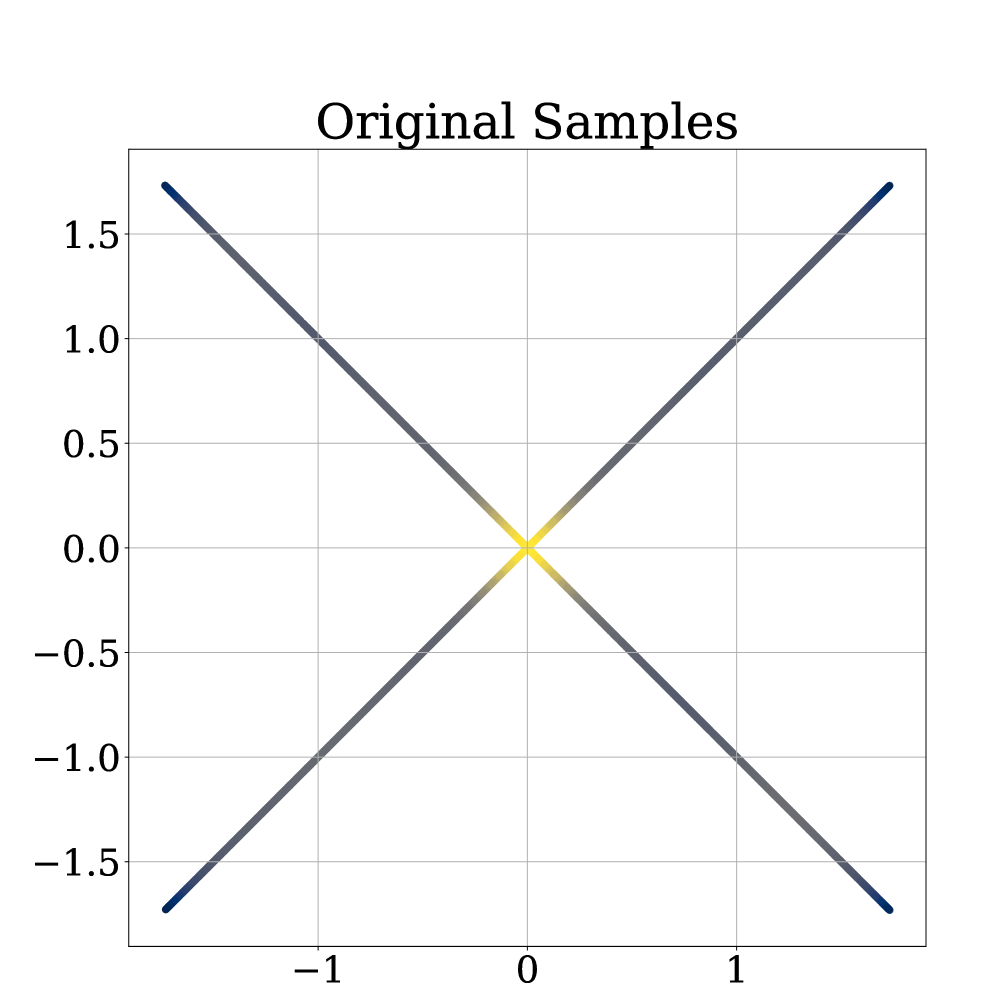
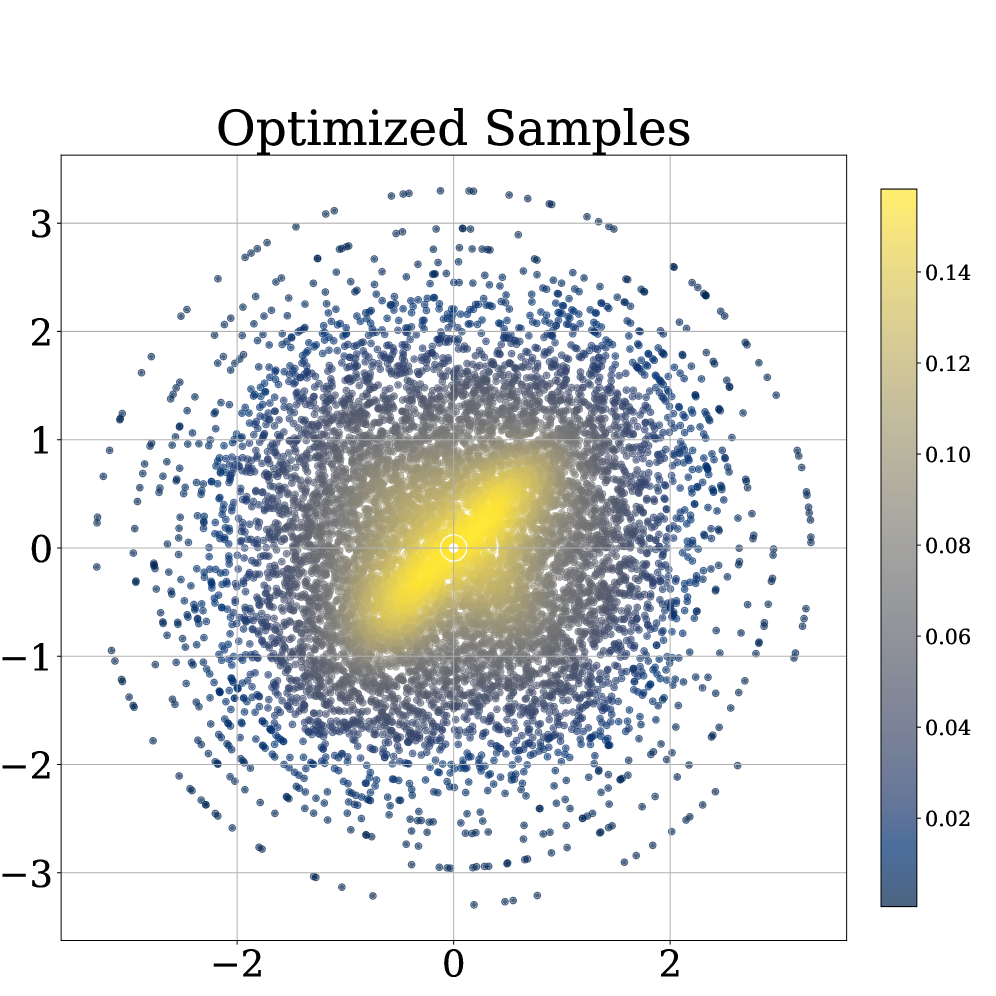
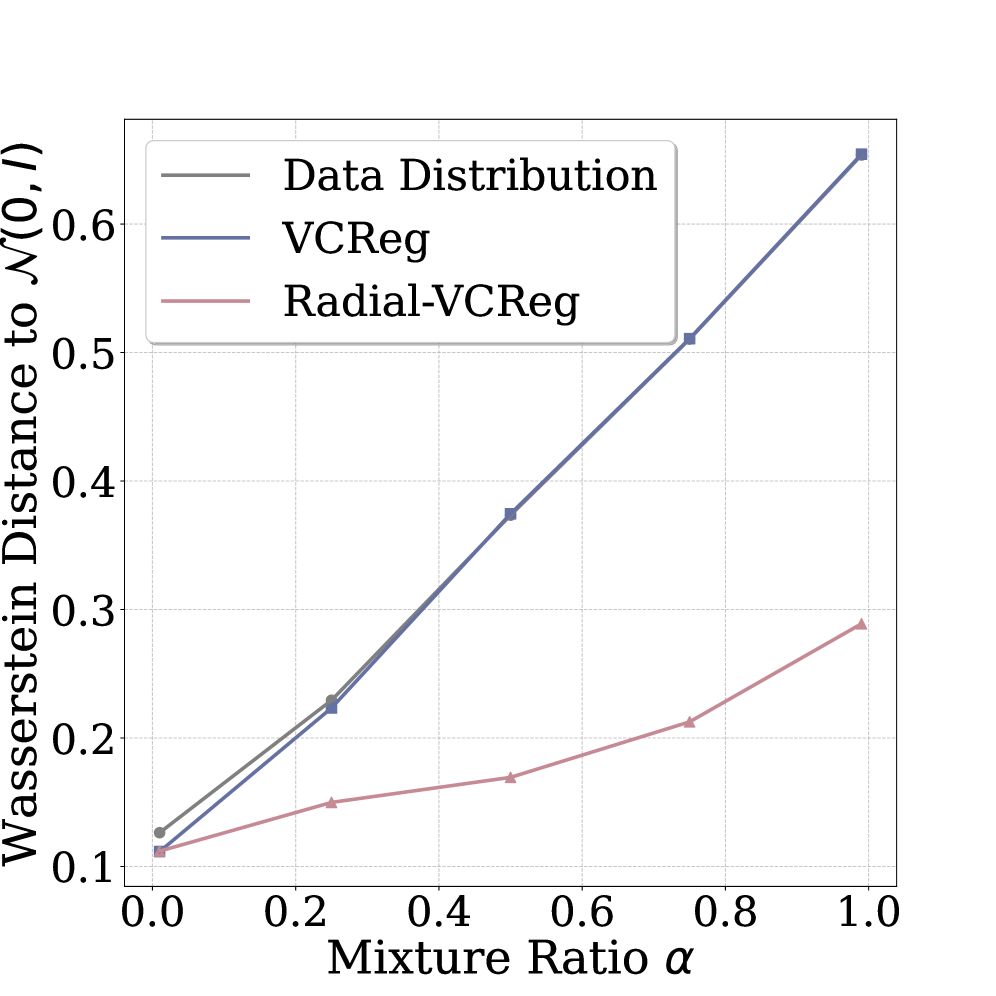
📊 实验亮点
在合成数据集和真实数据集上的实验结果表明,Radial-VCReg能够显著提高自监督学习的性能。例如,在CIFAR-10数据集上,Radial-VCReg相比于VCReg,线性分类准确率提高了约2%。此外,实验还表明,Radial-VCReg能够更有效地减少高阶依赖,并学习到更接近高维高斯分布的表征。
🎯 应用场景
Radial-VCReg具有广泛的应用前景,可应用于图像识别、自然语言处理、语音识别等领域。通过学习更具信息量的表征,可以提高各种下游任务的性能,例如图像分类、目标检测、文本分类等。此外,该方法还可以应用于无监督学习和半监督学习,从而减少对标注数据的依赖。未来,该方法有望在机器人感知、自动驾驶等领域发挥重要作用。
📄 摘要(原文)
Self-supervised learning aims to learn maximally informative representations, but explicit information maximization is hindered by the curse of dimensionality. Existing methods like VCReg address this by regularizing first and second-order feature statistics, which cannot fully achieve maximum entropy. We propose Radial-VCReg, which augments VCReg with a radial Gaussianization loss that aligns feature norms with the Chi distribution-a defining property of high-dimensional Gaussians. We prove that Radial-VCReg transforms a broader class of distributions towards normality compared to VCReg and show on synthetic and real-world datasets that it consistently improves performance by reducing higher-order dependencies and promoting more diverse and informative representations.