Multi-Agent Debate: A Unified Agentic Framework for Tabular Anomaly Detection
作者: Pinqiao Wang, Sheng Li
分类: cs.LG, cs.AI
发布日期: 2026-02-15
💡 一句话要点
提出MAD多智能体辩论框架,用于提升表格异常检测的鲁棒性和可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格异常检测 多智能体系统 辩论框架 鲁棒性 可解释性 大型语言模型 异构模型集成
📋 核心要点
- 现有表格异常检测方法依赖单一模型或静态集成,难以应对数据分布变化和模型分歧。
- MAD框架将异构模型的分歧作为重要信号,通过智能体辩论和协调机制提升检测性能。
- 实验表明,MAD在多种表格异常检测基准上表现出更强的鲁棒性,并提供可解释的辩论过程。
📝 摘要(中文)
表格异常检测通常由单一检测器或静态集成方法处理。然而,在表格数据上表现优异的模型通常来自异构模型族(例如,树集成、深度表格网络和表格基础模型),这些模型在分布偏移、缺失值和罕见异常情况下经常存在分歧。我们提出了MAD,一个多智能体辩论框架,将这种分歧视为首要信号,并通过数学上合理的协调层来解决它。每个智能体都是一个基于机器学习的检测器,产生归一化的异常分数、置信度和结构化证据,并由基于大型语言模型的评论员增强。协调器将这些消息转换为有界的每个智能体损失,并通过指数梯度规则更新智能体的影响力,从而产生最终的辩论异常分数和可审计的辩论轨迹。MAD是一个统一的智能体框架,可以通过限制消息空间和综合算子来恢复现有的方法,例如混合专家门控和专家建议学习聚合。我们建立了综合损失的遗憾保证,并展示了如何使用共形校准来包装辩论分数,以在可交换性下控制假阳性。在各种表格异常基准上的实验表明,与基线相比,MAD具有更高的鲁棒性,并能提供更清晰的模型分歧轨迹。
🔬 方法详解
问题定义:表格异常检测旨在识别表格数据中与正常模式显著不同的数据点。现有方法,如单一检测器或静态集成,在面对数据分布偏移、缺失值以及罕见异常时,由于异构模型间存在分歧,表现出局限性。这些分歧没有被有效利用,导致鲁棒性不足。
核心思路:MAD的核心思路是将多个异构的异常检测模型视为独立的智能体,通过辩论的方式来解决它们之间的分歧。每个智能体提供异常评分、置信度和证据,并通过协调机制进行信息交换和学习,最终达成一致的异常检测结果。这种方法充分利用了不同模型的优势,提高了整体的鲁棒性和准确性。
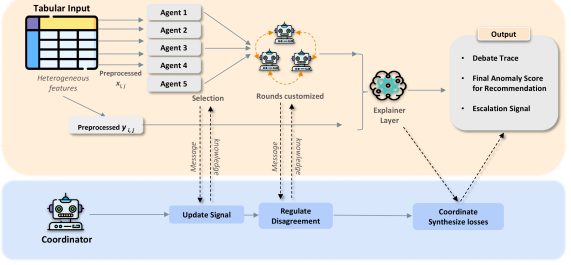
技术框架:MAD框架包含以下几个主要模块:1) 智能体 (Agent):每个智能体是一个基于机器学习的异常检测器,负责生成归一化的异常分数、置信度和结构化证据。2) 评论员 (Critic):基于大型语言模型(LLM),用于评估智能体提供的证据,并提供反馈。3) 协调器 (Coordinator):负责将智能体的消息转换为有界的损失函数,并使用指数梯度规则更新智能体的影响力。4) 辩论轨迹 (Debate Trace):记录智能体之间的辩论过程,提供可审计的决策依据。
关键创新:MAD的关键创新在于将多智能体辩论的思想引入表格异常检测领域,并设计了一个统一的框架来处理异构模型之间的分歧。通过协调机制和损失函数的设计,MAD能够有效地学习不同智能体的优势,并生成更准确和鲁棒的异常检测结果。此外,MAD框架具有可解释性,能够提供辩论轨迹,帮助用户理解模型的决策过程。
关键设计:MAD的关键设计包括:1) 智能体消息格式:每个智能体需要提供归一化的异常分数、置信度和结构化证据,以便协调器进行处理。2) 协调器损失函数:协调器使用有界的损失函数来评估每个智能体的表现,并根据指数梯度规则更新智能体的影响力。3) 辩论轨迹生成:MAD记录智能体之间的消息传递和影响力变化,生成可审计的辩论轨迹。4) 共形校准:使用共形校准方法来包装辩论分数,以控制假阳性率。
🖼️ 关键图片
📊 实验亮点
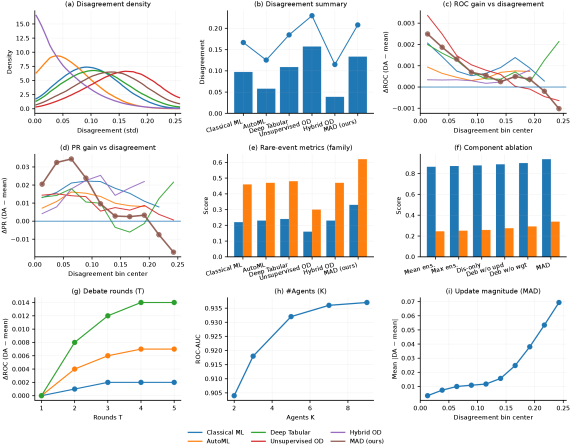
实验结果表明,MAD在多个表格异常检测基准数据集上优于现有基线方法,包括单一检测器和静态集成方法。MAD在鲁棒性方面表现出显著提升,尤其是在数据分布偏移和缺失值的情况下。此外,MAD提供的辩论轨迹能够清晰地展示模型之间的分歧和决策过程,提高了模型的可解释性。
🎯 应用场景
MAD框架可应用于金融欺诈检测、网络安全异常检测、工业设备故障诊断等领域。通过提升表格异常检测的鲁棒性和可解释性,MAD能够帮助用户更准确地识别异常事件,降低风险,并为决策提供更可靠的依据。未来,MAD有望与其他技术结合,例如可信AI和联邦学习,进一步拓展其应用范围。
📄 摘要(原文)
Tabular anomaly detection is often handled by single detectors or static ensembles, even though strong performance on tabular data typically comes from heterogeneous model families (e.g., tree ensembles, deep tabular networks, and tabular foundation models) that frequently disagree under distribution shift, missingness, and rare-anomaly regimes. We propose MAD, a Multi-Agent Debating framework that treats this disagreement as a first-class signal and resolves it through a mathematically grounded coordination layer. Each agent is a machine learning (ML)-based detector that produces a normalized anomaly score, confidence, and structured evidence, augmented by a large language model (LLM)-based critic. A coordinator converts these messages into bounded per-agent losses and updates agent influence via an exponentiated-gradient rule, yielding both a final debated anomaly score and an auditable debate trace. MAD is a unified agentic framework that can recover existing approaches, such as mixture-of-experts gating and learning-with-expert-advice aggregation, by restricting the message space and synthesis operator. We establish regret guarantees for the synthesized losses and show how conformal calibration can wrap the debated score to control false positives under exchangeability. Experiments on diverse tabular anomaly benchmarks show improved robustness over baselines and clearer traces of model disagreement