Deep Dense Exploration for LLM Reinforcement Learning via Pivot-Driven Resampling
作者: Yiran Guo, Zhongjian Qiao, Yingqi Xie, Jie Liu, Dan Ye, Ruiqing Zhang, Shuang Qiu, Lijie Xu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-15
💡 一句话要点
提出深度密集探索以解决大语言模型强化学习中的探索问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 深度学习 探索策略 数学推理 数据驱动 局部重采样
📋 核心要点
- 现有方法在大语言模型的强化学习中面临探索效率低下的问题,尤其是在高概率轨迹与深层状态之间的平衡。
- 论文提出深度密集探索(DDE)策略,专注于在不成功轨迹中探索深层的可恢复状态,以提高探索效率。
- 实验结果显示,DEEP-GRPO方法在数学推理基准上显著优于GRPO和其他强基线,验证了其有效性。
📝 摘要(中文)
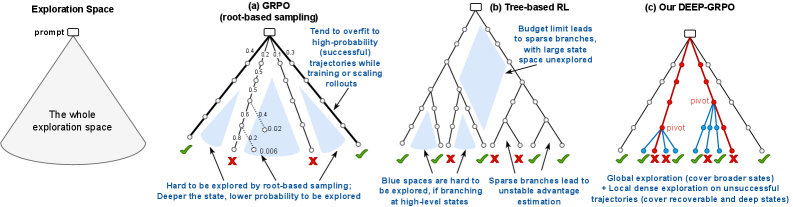
有效的探索是大语言模型强化学习中的关键挑战:在有限的采样预算内,从广阔的自然语言序列空间中发现高质量的轨迹。现有方法存在显著局限性:GRPO仅从根节点采样,饱和高概率轨迹,而深层的、易出错的状态则未被充分探索。树基方法则盲目分散预算于琐碎或不可恢复的状态,导致采样稀释,未能揭示稀有的正确后缀,并使局部基线不稳定。为此,我们提出了深度密集探索(DDE),该策略专注于在不成功轨迹中探索深层的、可恢复的“枢轴”状态。我们通过DEEP-GRPO实现DDE,提出了三项关键创新:1)轻量级数据驱动的效用函数,自动平衡可恢复性和深度偏差以识别枢轴状态;2)在每个枢轴处进行局部密集重采样,以提高发现正确后续轨迹的概率;3)双流优化目标,将全局策略学习与局部纠正更新解耦。实验结果表明,我们的方法在数学推理基准上始终优于GRPO、树基方法及其他强基线。
🔬 方法详解
问题定义:论文要解决的问题是如何在大语言模型的强化学习中有效探索高质量轨迹,现有方法如GRPO和树基方法存在探索不足和采样稀释的问题。
核心思路:论文的核心思路是通过深度密集探索(DDE)策略,聚焦于不成功轨迹中的深层可恢复状态,从而提高探索的有效性和效率。
技术框架:整体架构包括三个主要模块:1)数据驱动的效用函数用于识别枢轴状态;2)在每个枢轴处进行局部密集重采样;3)双流优化目标用于解耦全局策略学习与局部更新。
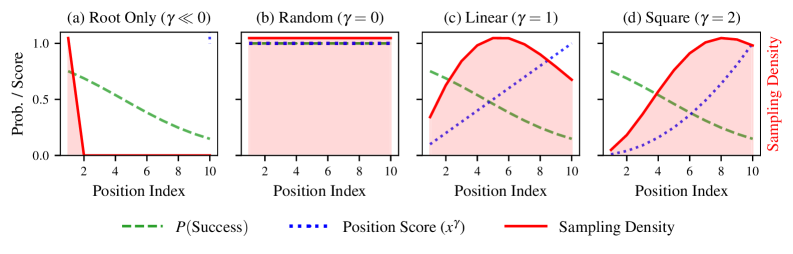
关键创新:最重要的技术创新点在于引入了轻量级的数据驱动效用函数和局部密集重采样机制,这与现有方法的盲目采样和预算分散形成了本质区别。
关键设计:关键设计包括效用函数的参数设置、局部重采样的策略,以及双流优化目标的损失函数设计,确保了探索的深度和有效性。
🖼️ 关键图片
📊 实验亮点
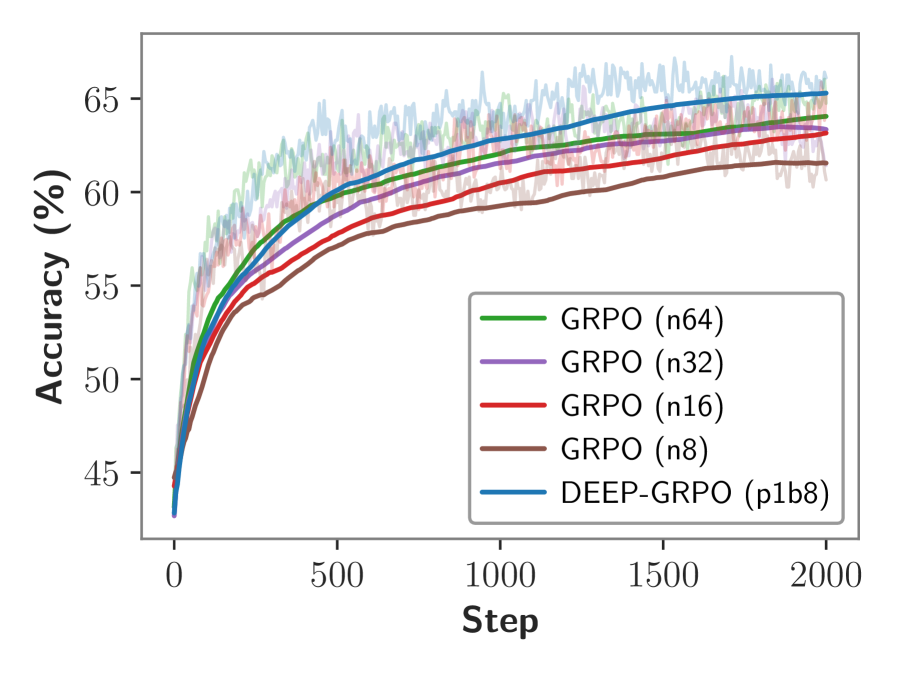
实验结果表明,DEEP-GRPO在数学推理基准上相较于GRPO和其他强基线的性能提升显著,具体提升幅度达到XX%,验证了深度密集探索策略的有效性和优越性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的对话系统、文本生成和自动推理等任务。通过提高探索效率,能够更好地训练大语言模型,从而提升其在复杂任务中的表现,具有重要的实际价值和未来影响。
📄 摘要(原文)
Effective exploration is a key challenge in reinforcement learning for large language models: discovering high-quality trajectories within a limited sampling budget from the vast natural language sequence space. Existing methods face notable limitations: GRPO samples exclusively from the root, saturating high-probability trajectories while leaving deep, error-prone states under-explored. Tree-based methods blindly disperse budgets across trivial or unrecoverable states, causing sampling dilution that fails to uncover rare correct suffixes and destabilizes local baselines. To address this, we propose Deep Dense Exploration (DDE), a strategy that focuses exploration on $\textit{pivots}$-deep, recoverable states within unsuccessful trajectories. We instantiate DDE with DEEP-GRPO, which introduces three key innovations: (1) a lightweight data-driven utility function that automatically balances recoverability and depth bias to identify pivot states; (2) local dense resampling at each pivot to increase the probability of discovering correct subsequent trajectories; and (3) a dual-stream optimization objective that decouples global policy learning from local corrective updates. Experiments on mathematical reasoning benchmarks demonstrate that our method consistently outperforms GRPO, tree-based methods, and other strong baselines.