QuRL: Efficient Reinforcement Learning with Quantized Rollout
作者: Yuhang Li, Reena Elangovan, Xin Dong, Priyadarshini Panda, Brucek Khailany
分类: cs.LG
发布日期: 2026-02-15
备注: Accepted to ICLR 2026
💡 一句话要点
QuRL:通过量化Rollout加速可验证奖励强化学习训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 量化 大型语言模型 Rollout加速 自适应裁剪范围
📋 核心要点
- 大型语言模型强化学习训练中,Rollout过程因自回归解码成为效率瓶颈,严重影响训练速度。
- QuRL通过量化Actor加速Rollout,并提出自适应裁剪范围(ACR)和不变缩放技术解决量化带来的训练问题。
- 实验表明,QuRL在DeepScaleR和DAPO上使用INT8和FP8量化,实现了20%到80%的Rollout加速。
📝 摘要(中文)
可验证奖励强化学习(RLVR)已成为训练推理大型语言模型(LLM)的一种趋势范式。然而,由于LLM的自回归解码特性,rollout过程成为RL训练的效率瓶颈,占据总训练时间的70%。本文提出了量化强化学习(QuRL),它使用量化的actor来加速rollout。QuRL面临两个挑战。首先,我们提出了自适应裁剪范围(ACR),它基于全精度actor和量化actor之间的策略比率动态调整裁剪比率,这对于缓解长期训练崩溃至关重要。其次,我们发现了权重更新问题,即RL步骤之间的权重变化非常小,使得量化操作难以有效地捕获它们。我们通过不变缩放技术来缓解这个问题,该技术减少了量化噪声并增加了权重更新。我们在DeepScaleR和DAPO上使用INT8和FP8量化实验评估了我们的方法,并在训练期间实现了20%到80%的rollout加速。
🔬 方法详解
问题定义:论文旨在解决大型语言模型强化学习训练中Rollout过程效率低下的问题。由于LLM的自回归特性,Rollout过程需要大量的计算资源和时间,成为训练的瓶颈。现有的方法没有充分利用量化技术来加速Rollout过程,并且在量化过程中容易出现训练崩溃和权重更新困难等问题。
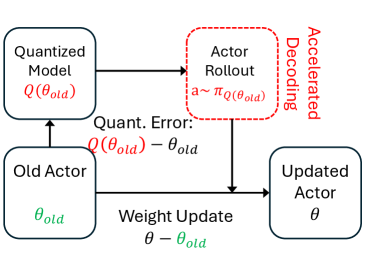
核心思路:论文的核心思路是通过量化Actor来加速Rollout过程。具体来说,使用低精度(如INT8或FP8)的量化Actor代替全精度Actor进行Rollout,从而减少计算量和内存占用,提高Rollout速度。为了解决量化带来的训练问题,论文提出了自适应裁剪范围(ACR)和不变缩放技术。
技术框架:QuRL的整体框架包括以下几个主要步骤:1) 使用全精度Actor进行策略学习;2) 将全精度Actor量化为低精度Actor;3) 使用量化的Actor进行Rollout,生成训练数据;4) 使用训练数据更新全精度Actor的策略。其中,ACR用于动态调整裁剪范围,防止训练崩溃;不变缩放技术用于减少量化噪声,提高权重更新效率。
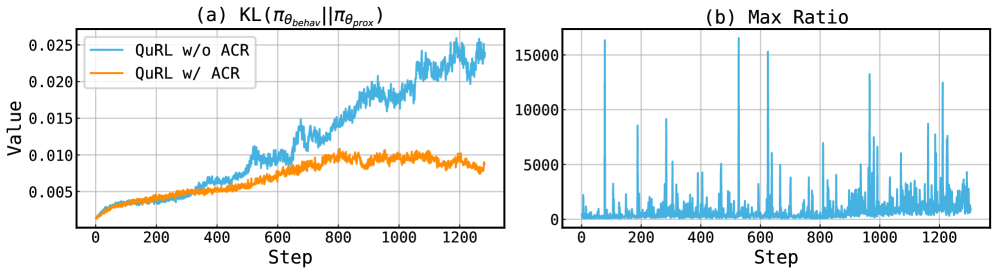
关键创新:论文的关键创新在于提出了自适应裁剪范围(ACR)和不变缩放技术。ACR能够根据全精度Actor和量化Actor之间的策略比率动态调整裁剪范围,从而缓解长期训练崩溃的问题。不变缩放技术能够减少量化噪声,增加权重更新的幅度,从而提高训练效率。与现有方法相比,QuRL能够在保证训练稳定性的前提下,显著提高Rollout速度。
关键设计:ACR的关键设计在于动态调整裁剪比例,公式为:clip_ratio = clip_range * policy_ratio,其中clip_range是预设的裁剪范围,policy_ratio是全精度Actor和量化Actor之间的策略比率。不变缩放技术的关键设计在于对权重进行缩放,公式为:weight_scaled = weight * scale,其中scale是一个常数,用于放大权重变化。损失函数采用标准的PPO损失函数,网络结构采用Transformer结构。
🖼️ 关键图片
📊 实验亮点
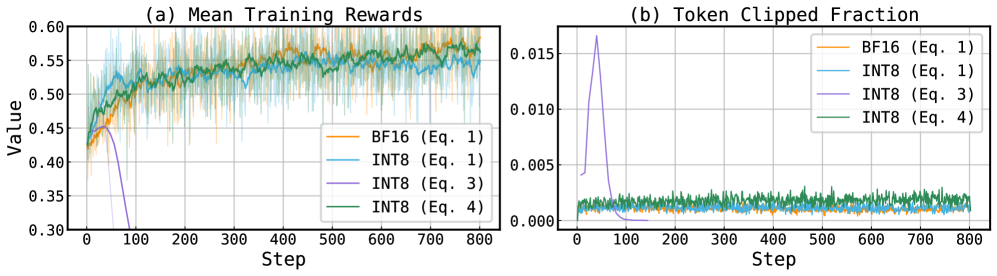
实验结果表明,QuRL在DeepScaleR和DAPO数据集上,使用INT8和FP8量化,实现了20%到80%的Rollout加速。与基线方法相比,QuRL在保证训练稳定性的前提下,显著提高了训练效率。此外,ACR和不变缩放技术有效地缓解了量化带来的训练问题,证明了QuRL的有效性。
🎯 应用场景
QuRL具有广泛的应用前景,尤其是在需要大规模强化学习训练的大型语言模型领域。该方法可以显著降低训练成本,缩短训练时间,加速LLM的开发和部署。此外,QuRL还可以应用于其他需要高效Rollout的强化学习任务,例如机器人控制、游戏AI等。未来,QuRL有望成为一种通用的强化学习加速技术。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) has become a trending paradigm for training reasoning large language models (LLMs). However, due to the autoregressive decoding nature of LLMs, the rollout process becomes the efficiency bottleneck of RL training, consisting of up to 70\% of the total training time. In this work, we propose Quantized Reinforcement Learning (QuRL) that uses a quantized actor for accelerating the rollout. We address two challenges in QuRL. First, we propose Adaptive Clipping Range (ACR) that dynamically adjusts the clipping ratio based on the policy ratio between the full-precision actor and the quantized actor, which is essential for mitigating long-term training collapse. Second, we identify the weight update problem, where weight changes between RL steps are extremely small, making it difficult for the quantization operation to capture them effectively. We mitigate this problem through the invariant scaling technique that reduces quantization noise and increases weight update. We evaluate our method with INT8 and FP8 quantization experiments on DeepScaleR and DAPO, and achieve 20% to 80% faster rollout during training.