Experiential Reinforcement Learning
作者: Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, Jieyu Zhao
分类: cs.LG, cs.AI
发布日期: 2026-02-15
备注: 26 pages, 9 tables, 7 figures
💡 一句话要点
提出经验强化学习(ERL),通过显式经验反思循环提升语言模型在稀疏奖励环境下的学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 经验反思 语言模型 稀疏奖励 智能体推理
📋 核心要点
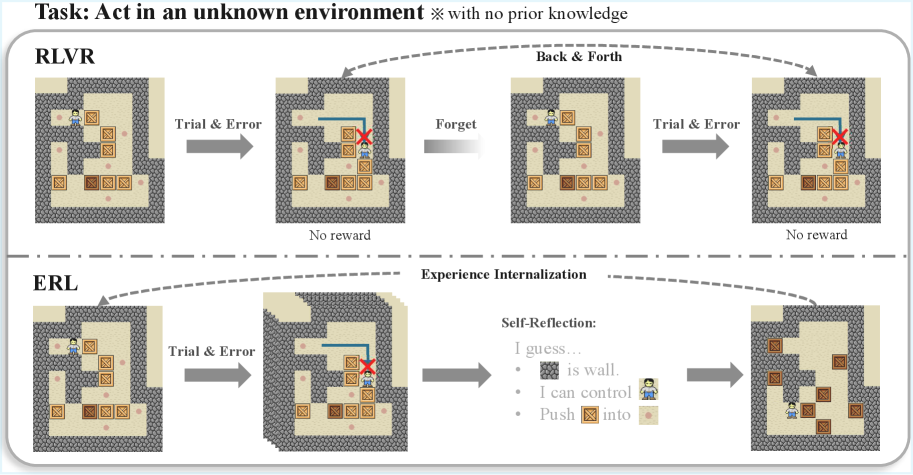
- 现有强化学习方法在稀疏和延迟奖励环境下,语言模型难以有效学习,无法明确将失败经验转化为行为改进。
- ERL通过引入经验-反思-巩固循环,使模型能够显式地反思经验,指导后续尝试,从而更有效地利用反馈。
- 实验表明,ERL在稀疏奖励控制环境和智能体推理任务中,显著提升了学习效率和最终性能,最高提升达81%。
📝 摘要(中文)
强化学习已成为语言模型(LMs)从环境奖励或反馈中学习的主要方法。然而,在实践中,环境反馈通常是稀疏且延迟的。从这种信号中学习具有挑战性,因为LMs必须隐式地推断观察到的失败应该如何转化为未来迭代中的行为改变。我们引入了经验强化学习(ERL),这是一种训练范式,它将显式的经验-反思-巩固循环嵌入到强化学习过程中。给定一个任务,模型生成一个初始尝试,接收环境反馈,并产生一个反思,该反思指导一个改进的第二次尝试,其成功被强化并内化到基础策略中。这个过程将反馈转化为结构化的行为修正,在不增加额外推理成本的情况下,提高探索和稳定优化,同时保留部署时的收益。在稀疏奖励控制环境和智能体推理基准测试中,ERL始终优于强大的强化学习基线,在复杂的多步骤环境中实现了高达+81%的收益,在使用工具的推理任务中实现了高达+11%的收益。这些结果表明,将显式的自我反思整合到策略训练中,为将反馈转化为持久的行为改进提供了一种实用的机制。
🔬 方法详解
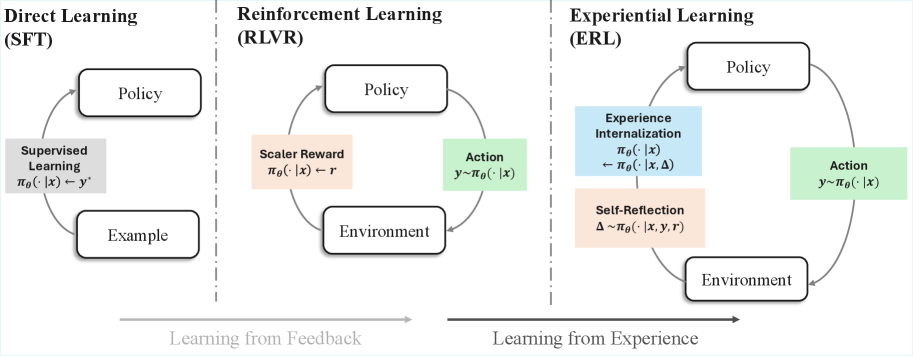
问题定义:现有强化学习方法在处理稀疏奖励和延迟反馈时面临挑战。语言模型需要隐式地推断失败的原因,并将这些信息转化为未来行为的改进,这通常效率低下且不稳定。现有的方法缺乏一种明确的机制来反思过去的经验并从中学习。
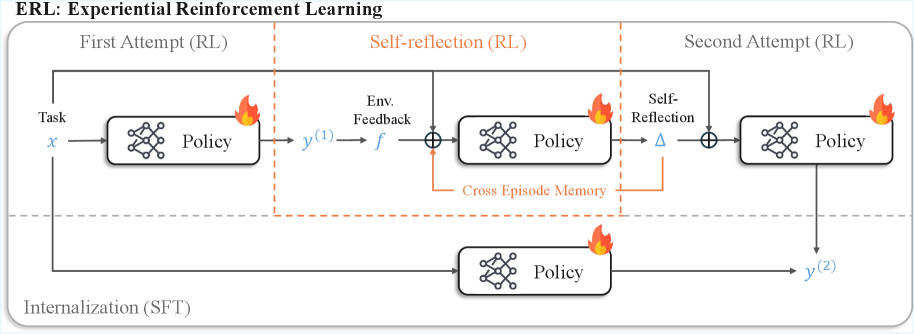
核心思路:ERL的核心思想是将一个显式的经验-反思-巩固循环引入到强化学习过程中。模型首先进行一次尝试,然后接收环境反馈,并基于此反馈生成一个反思。这个反思被用来指导第二次尝试,如果第二次尝试成功,则将其结果巩固到基础策略中。这种显式的反思过程使得模型能够更有效地利用反馈,并更稳定地改进其行为。
技术框架:ERL的整体框架包含三个主要阶段:经验生成、反思和巩固。在经验生成阶段,模型根据当前策略生成一个初始尝试。在反思阶段,模型接收环境反馈,并使用一个反思模块来生成一个反思,该反思描述了初始尝试的成功或失败,并提出了改进建议。在巩固阶段,模型使用反思来指导第二次尝试,如果第二次尝试成功,则使用强化学习算法来更新基础策略。
关键创新:ERL最重要的创新点在于引入了显式的反思过程。与传统的强化学习方法相比,ERL允许模型明确地反思过去的经验,并将这些经验转化为结构化的行为改进。这种显式的反思过程提高了学习效率和稳定性,并使得模型能够更好地利用稀疏奖励和延迟反馈。
关键设计:ERL的关键设计包括反思模块的设计和巩固策略的设计。反思模块可以使用各种技术来实现,例如语言模型或神经网络。巩固策略可以使用各种强化学习算法来实现,例如策略梯度或Q学习。论文中具体使用了何种反思模块和巩固策略未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ERL在稀疏奖励控制环境中,相比于基线方法,性能提升高达81%。在工具使用推理任务中,ERL也取得了显著的提升,性能提升高达11%。这些结果表明,ERL能够有效地利用稀疏反馈,并显著提高语言模型在复杂任务中的学习效率和最终性能。
🎯 应用场景
ERL具有广泛的应用前景,可以应用于各种需要从稀疏和延迟反馈中学习的任务,例如机器人控制、游戏AI和自然语言处理。该方法可以帮助智能体更有效地探索环境,并更稳定地改进其行为,从而提高其在复杂任务中的性能。尤其在需要智能体进行复杂推理和规划的任务中,ERL能够提供更强的学习能力。
📄 摘要(原文)
Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.