A Theoretical Framework for LLM Fine-tuning Using Early Stopping for Non-random Initialization
作者: Zexuan Sun, Garvesh Raskutti
分类: stat.ML, cs.LG
发布日期: 2026-02-15
💡 一句话要点
针对非随机初始化,提出基于早停的LLM微调理论框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 微调 神经切核 早停 非随机初始化
📋 核心要点
- 现有LLM微调缺乏坚实的理论基础,无法解释为何少量epoch即可达到良好效果。
- 论文结合早停理论与注意力NTK,构建LLM微调的统计框架,解释微调的收敛性。
- 实验验证了理论框架的有效性,支持了关于收敛速度与核矩阵特征值衰减率关系的理论见解。
📝 摘要(中文)
在大语言模型(LLM)时代,微调预训练模型已变得普遍。然而,其理论基础仍然是一个开放的问题。一个核心问题是,为什么通常只需几个epoch的微调就足以在许多不同的任务上取得强大的性能。在这项工作中,我们通过开发一个统计框架来解决这个问题,该框架将严格的早停理论与基于注意力机制的LLM神经切核(NTK)相结合,为微调实践提供了新的理论见解。具体来说,我们正式将经典的NTK理论扩展到非随机(即预训练的)初始化,并为基于注意力的微调提供收敛保证。该理论提供的一个关键见解是,关于样本大小的收敛速度与NTK诱导的经验核矩阵的特征值衰减率密切相关。我们还展示了该框架如何用于解释LLM中多个任务的任务向量。最后,在真实世界数据集上使用现代语言模型进行的实验提供了支持我们理论见解的经验证据。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)微调的理论基础问题,特别是解释为什么通常只需要少量epoch的微调就能在各种任务上取得优异的性能。现有方法缺乏对微调过程的理论理解,无法解释预训练初始化对微调收敛速度的影响。
核心思路:论文的核心思路是将经典的神经切核(NTK)理论扩展到非随机初始化的情况,即预训练的LLM。通过结合早停理论,论文建立了一个统计框架,用于分析基于注意力机制的LLM微调过程的收敛性。核心在于将收敛速度与经验核矩阵的特征值衰减率联系起来,从而解释了微调的效率。
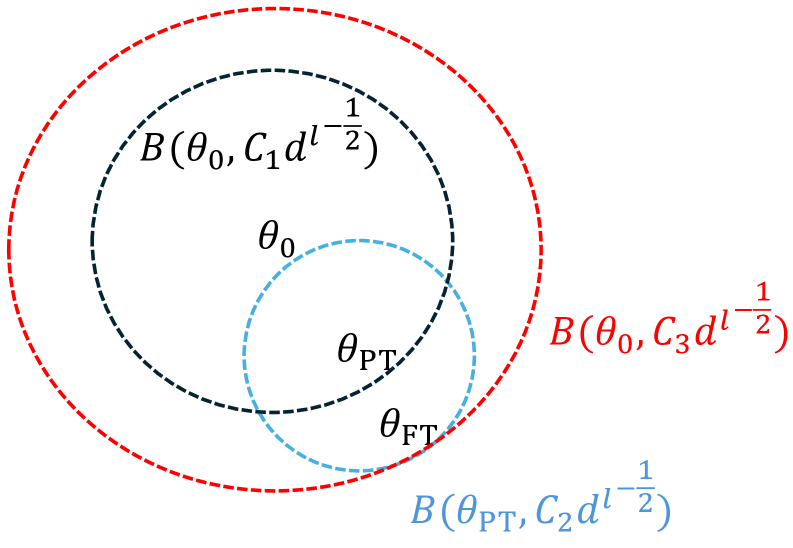
技术框架:该框架主要包含以下几个阶段:1) 将LLM的微调过程建模为基于注意力机制的NTK回归问题。2) 将经典的NTK理论扩展到非随机初始化,考虑预训练模型的影响。3) 利用早停理论,分析微调过程中的泛化误差,并确定最佳的停止时间。4) 通过分析经验核矩阵的特征值衰减率,建立收敛速度与样本大小之间的关系。
关键创新:论文最重要的技术创新在于将NTK理论扩展到非随机初始化,这使得该理论能够应用于预训练的LLM。此外,论文还建立了收敛速度与经验核矩阵特征值衰减率之间的联系,为理解微调过程提供了新的视角。
关键设计:论文的关键设计包括:1) 使用基于注意力机制的NTK来建模LLM的微调过程。2) 针对非随机初始化,修改了NTK的定义和收敛性分析。3) 利用早停理论,选择合适的微调epoch数,避免过拟合。4) 通过分析经验核矩阵的特征值衰减率,推导了收敛速度的理论上限。
🖼️ 关键图片
📊 实验亮点
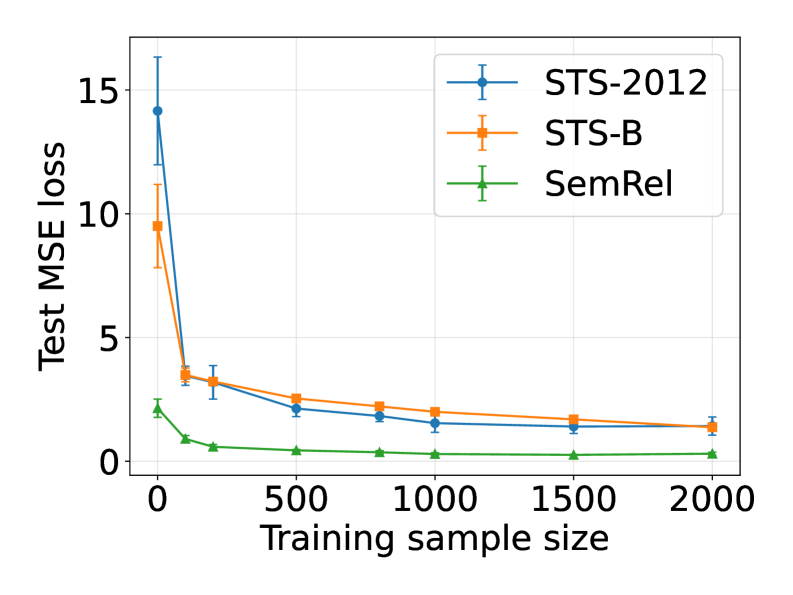
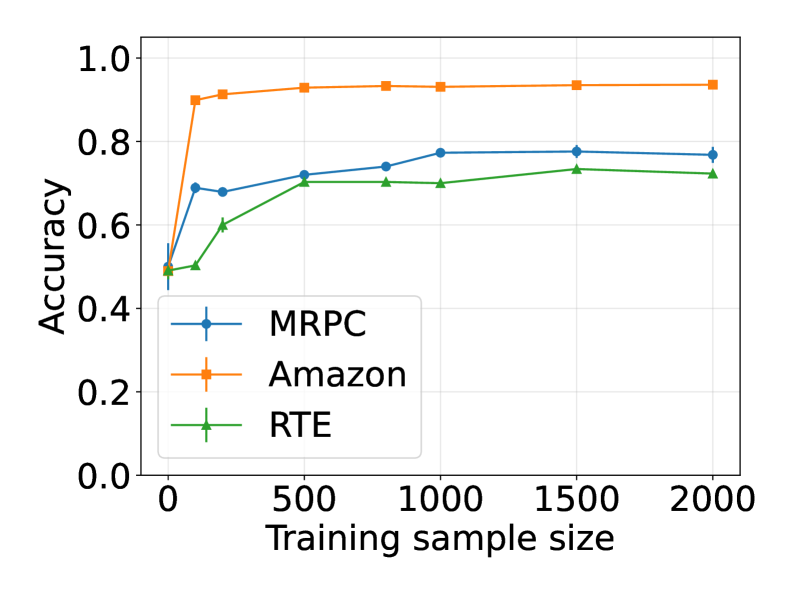
论文通过在真实世界数据集上使用现代语言模型进行实验,验证了理论框架的有效性。实验结果表明,收敛速度与经验核矩阵的特征值衰减率之间存在密切关系,这与理论预测相符。此外,实验还展示了该框架如何用于解释LLM中多个任务的任务向量,进一步验证了该理论的实用性。
🎯 应用场景
该研究成果可应用于指导LLM的微调实践,例如,根据任务的特点选择合适的预训练模型和微调策略,以及确定最佳的微调epoch数。此外,该理论框架还可以用于分析和比较不同微调算法的性能,并为开发更高效的微调算法提供理论指导。未来,该研究可以扩展到其他类型的预训练模型和任务。
📄 摘要(原文)
In the era of large language models (LLMs), fine-tuning pretrained models has become ubiquitous. Yet the theoretical underpinning remains an open question. A central question is why only a few epochs of fine-tuning are typically sufficient to achieve strong performance on many different tasks. In this work, we approach this question by developing a statistical framework, combining rigorous early stopping theory with the attention-based Neural Tangent Kernel (NTK) for LLMs, offering new theoretical insights on fine-tuning practices. Specifically, we formally extend classical NTK theory [Jacot et al., 2018] to non-random (i.e., pretrained) initializations and provide a convergence guarantee for attention-based fine-tuning. One key insight provided by the theory is that the convergence rate with respect to sample size is closely linked to the eigenvalue decay rate of the empirical kernel matrix induced by the NTK. We also demonstrate how the framework can be used to explain task vectors for multiple tasks in LLMs. Finally, experiments with modern language models on real-world datasets provide empirical evidence supporting our theoretical insights.