You Can Learn Tokenization End-to-End with Reinforcement Learning
作者: Sam Dauncey, Roger Wattenhofer
分类: cs.LG, cs.AI
发布日期: 2026-02-15
💡 一句话要点
提出基于强化学习的端到端分词方法,提升大语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 分词 大语言模型 端到端学习 score function估计
📋 核心要点
- 现有大语言模型的分词步骤通常是硬编码的,阻碍了模型端到端训练的实现。
- 利用强化学习中的score function估计学习token边界,直接优化离散token边界的划分。
- 实验表明,该方法在1亿参数规模下,优于先前的straight-through估计方法。
📝 摘要(中文)
本文提出了一种基于强化学习的端到端分词方法,旨在解决大语言模型(LLMs)训练流程中分词步骤的硬编码问题。尽管架构上越来越趋向端到端,但分词仍然是一个独立的压缩步骤。先前的工作尝试使用启发式方法或straight-through估计将分词步骤融入LLM架构,但效果有限。本文利用score function估计学习token边界,该方法具有更强的理论保证,因为它直接优化离散token边界的划分以最小化损失。研究发现,强化学习中的时间折扣等技术对于降低score function的方差至关重要。实验结果表明,该方法在1亿参数规模下,在质量和数量上均优于先前的straight-through估计方法。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)训练流程中tokenization(分词)步骤的硬编码问题。现有的分词方法通常是预定义的,与模型的训练过程分离,这限制了模型端到端优化的潜力。此外,现有的基于启发式或straight-through估计的分词方法在性能上存在局限性。
核心思路:论文的核心思路是利用强化学习直接学习token边界。通过将token边界的划分视为一个离散决策问题,并使用score function估计来优化这个决策过程,从而避免了将离散问题连续化的近似方法。这种方法能够更直接地优化token边界,并具有更强的理论保证。
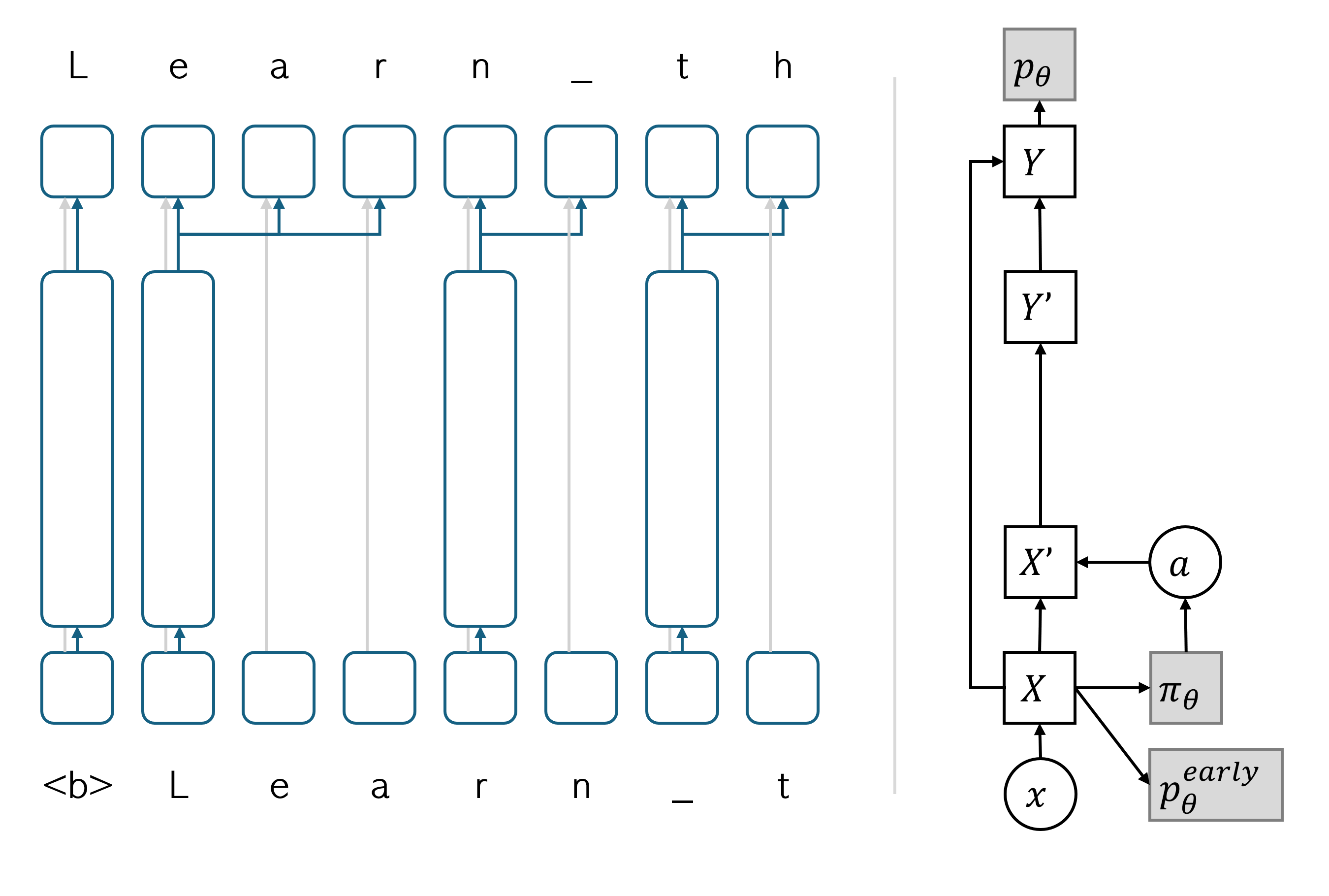
技术框架:整体框架包括一个强化学习环境,其中agent负责选择token边界,环境根据agent的选择给出奖励。具体来说,agent接收文本作为输入,并输出token边界的概率分布。然后,根据这个分布采样得到token边界。环境根据模型在下游任务上的表现(例如,语言建模的损失)来计算奖励。强化学习算法(例如,REINFORCE)用于更新agent的策略,使其能够选择更好的token边界。
关键创新:最重要的技术创新点在于使用score function估计来学习token边界。与现有的straight-through估计方法不同,score function估计直接优化离散token边界的划分,避免了将离散问题连续化的近似。此外,论文还发现,强化学习中的时间折扣技术对于降低score function的方差至关重要,从而使得该方法在实践中可行。
关键设计:论文使用了REINFORCE算法作为强化学习算法。为了降低方差,论文引入了时间折扣因子。具体来说,对于每个token边界,奖励会根据其在序列中的位置进行折扣。此外,论文还设计了一个合适的奖励函数,该函数基于模型在下游任务上的损失来计算。网络结构方面,agent可以使用Transformer或其他序列模型来预测token边界的概率分布。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在1亿参数规模下,在质量和数量上均优于先前的straight-through估计方法。具体来说,该方法在语言建模任务上取得了更低的困惑度,并且能够学习到更有效的token表示。这些结果表明,基于强化学习的端到端分词方法具有很大的潜力。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务,特别是需要高性能和高效率的大语言模型。通过端到端地学习tokenization,可以提高模型的压缩效率、泛化能力和下游任务的性能。此外,该方法还可以应用于资源受限的场景,例如移动设备或嵌入式系统,因为它可以减少模型的存储空间和计算复杂度。未来,该方法有望成为大语言模型训练的标准流程之一。
📄 摘要(原文)
Tokenization is a hardcoded compression step which remains in the training pipeline of Large Language Models (LLMs), despite a general trend towards architectures becoming increasingly end-to-end. Prior work has shown promising results at scale in bringing this compression step inside the LLMs' architecture with heuristics to draw token boundaries, and also attempts to learn these token boundaries with straight-through estimates, which treat the problem of drawing discrete token boundaries as a continuous one. We show that these token boundaries can instead be learned using score function estimates, which have tighter theoretical guarantees due to directly optimizing the problem of drawing discrete token boundaries to minimize loss. We observe that techniques from reinforcement learning, such as time discounting, are necessary to reduce the variance of this score function sufficiently to make it practicable. We demonstrate that the resultant method outperforms prior proposed straight-through estimates, both qualitatively and quantitatively at the $100$ million parameter scale.