Mean Flow Policy with Instantaneous Velocity Constraint for One-step Action Generation
作者: Guojian Zhan, Letian Tao, Pengcheng Wang, Yixiao Wang, Yiheng Li, Yuxin Chen, Masayoshi Tomizuka, Shengbo Eben Li
分类: cs.LG, cs.AI
发布日期: 2026-02-14
备注: ICLR Oral Presentation
💡 一句话要点
提出基于瞬时速度约束的平均流策略,用于机器人操作任务中的单步动作生成。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 策略函数 流模型 机器人操作 瞬时速度约束
📋 核心要点
- 强化学习中策略函数的表达性和效率至关重要,但现有基于流的策略在表达性和计算负担之间存在权衡。
- 论文提出平均速度策略(MVP),通过建模平均速度场实现快速单步动作生成,并引入瞬时速度约束(IVC)提高表达性。
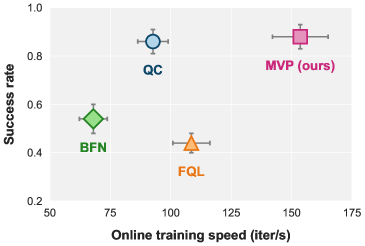
- 实验表明,MVP在机器人操作任务中取得了领先的成功率,并在训练和推理速度上优于现有方法。
📝 摘要(中文)
本文提出了一种新的生成策略函数——平均速度策略(MVP),它通过建模平均速度场来实现最快的单步动作生成。为了确保策略的高表达性,在训练过程中对平均速度场引入了瞬时速度约束(IVC)。理论证明,这种设计明确地充当了关键的边界条件,从而提高了学习精度并增强了策略的表达性。实验结果表明,MVP在Robomimic和OGBench的多个具有挑战性的机器人操作任务中实现了最先进的成功率。与现有的基于流的策略基线相比,MVP在训练和推理速度方面也实现了显著的提升。
🔬 方法详解
问题定义:现有基于流的策略函数在强化学习中建模复杂动作分布时,需要在表达能力和计算负担之间进行权衡。增加流的步骤可以提高表达能力,但会显著增加计算成本,限制了其在实时性要求高的任务中的应用。因此,如何设计一种既具有高表达能力又具有高效采样过程的策略函数是一个关键问题。
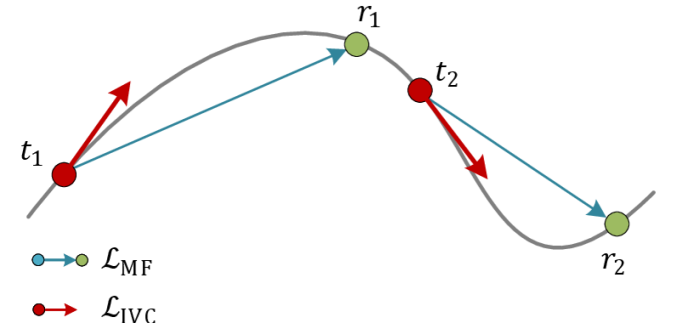
核心思路:本文的核心思路是直接建模平均速度场,从而实现单步动作生成。通过这种方式,可以避免传统流模型中需要多次迭代才能生成动作的问题,从而显著提高采样效率。为了保证平均速度场的表达能力,引入了瞬时速度约束(IVC),确保学习到的速度场能够准确地反映环境的动态特性。
技术框架:MVP策略函数的整体框架包括以下几个主要部分:1) 状态编码器:将环境状态编码为潜在向量;2) 平均速度场建模器:基于潜在向量,预测平均速度场;3) 瞬时速度约束(IVC):在训练过程中,对平均速度场施加约束,确保其满足物理规律;4) 动作生成器:基于平均速度场,直接生成动作。整个框架采用端到端的方式进行训练,通过强化学习算法优化策略函数。
关键创新:本文最重要的技术创新点在于引入了瞬时速度约束(IVC)。与现有方法相比,IVC能够显式地作为边界条件,指导平均速度场的学习,从而提高学习精度和策略表达能力。此外,MVP采用单步动作生成的方式,避免了传统流模型中的迭代过程,显著提高了采样效率。
关键设计:在具体实现中,平均速度场建模器可以采用神经网络结构,例如多层感知机(MLP)或卷积神经网络(CNN)。瞬时速度约束(IVC)可以通过损失函数的形式添加到训练目标中,例如,可以采用均方误差(MSE)损失函数来衡量预测速度与真实速度之间的差异。此外,还可以通过调整神经网络的结构和参数,以及优化训练算法,来进一步提高MVP的性能。
🖼️ 关键图片
📊 实验亮点
MVP在Robomimic和OGBench的多个机器人操作任务中取得了state-of-the-art的成功率。与现有基于流的策略相比,MVP在训练速度上提升了显著的幅度(具体数值未知),并且实现了更快的推理速度。这些实验结果表明,MVP在表达能力和效率方面都具有显著的优势。
🎯 应用场景
该研究成果可应用于各种需要快速决策和精确控制的机器人操作任务,例如自动化装配、物流分拣、医疗手术等。通过提高策略函数的表达能力和采样效率,可以使机器人更好地适应复杂环境,完成更加精细的操作,从而提高生产效率和降低成本。未来,该方法还可以扩展到其他领域,例如自动驾驶、游戏AI等。
📄 摘要(原文)
Learning expressive and efficient policy functions is a promising direction in reinforcement learning (RL). While flow-based policies have recently proven effective in modeling complex action distributions with a fast deterministic sampling process, they still face a trade-off between expressiveness and computational burden, which is typically controlled by the number of flow steps. In this work, we propose mean velocity policy (MVP), a new generative policy function that models the mean velocity field to achieve the fastest one-step action generation. To ensure its high expressiveness, an instantaneous velocity constraint (IVC) is introduced on the mean velocity field during training. We theoretically prove that this design explicitly serves as a crucial boundary condition, thereby improving learning accuracy and enhancing policy expressiveness. Empirically, our MVP achieves state-of-the-art success rates across several challenging robotic manipulation tasks from Robomimic and OGBench. It also delivers substantial improvements in training and inference speed over existing flow-based policy baselines.