Cast-R1: Learning Tool-Augmented Sequential Decision Policies for Time Series Forecasting
作者: Xiaoyu Tao, Mingyue Cheng, Chuang Jiang, Tian Gao, Huanjian Zhang, Yaguo Liu
分类: cs.LG
发布日期: 2026-02-14
🔗 代码/项目: GITHUB
💡 一句话要点
Cast-R1:提出工具增强的序列决策策略,用于时序预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 时序预测 序列决策 强化学习 工具增强 智能体 课程学习 状态管理
📋 核心要点
- 传统时序预测方法难以在复杂和不断变化的环境中有效工作,因为它们缺乏自主获取信息、推理未来变化和迭代修正预测的能力。
- Cast-R1将时序预测建模为序列决策过程,利用工具增强的智能体自主交互,提取特征、调用模型、进行推理和迭代优化预测。
- Cast-R1采用两阶段学习策略,结合监督微调和多轮强化学习,并通过课程学习提高策略学习效果,实验证明了其在真实数据集上的有效性。
📝 摘要(中文)
本文提出了一种名为Cast-R1的学习型时序预测框架,该框架将预测重新定义为一个序列决策问题。Cast-R1引入了一种基于内存的状态管理机制,用于维护跨交互步骤的决策相关信息,从而能够积累上下文证据以支持长时程推理。在此基础上,通过工具增强的智能体工作流执行预测,其中智能体自主地与模块化工具包交互,以提取统计特征,调用轻量级预测模型以进行决策支持,执行基于推理的预测,并通过自我反思迭代地改进预测。为了训练Cast-R1,我们采用了一种两阶段学习策略,该策略将监督微调与多轮强化学习相结合,以及一种课程学习方案,该方案逐步增加任务难度以提高策略学习。在多个真实世界时序数据集上的大量实验证明了Cast-R1的有效性。
🔬 方法详解
问题定义:传统时序预测方法通常将预测视为从历史观测到未来值的单次映射。这种方法在复杂和动态的环境中表现不佳,主要原因是缺乏自主获取信息、推理未来变化以及通过迭代决策过程修正预测的能力。现有方法难以有效利用上下文信息进行长时程推理,并且缺乏灵活的决策和优化机制。
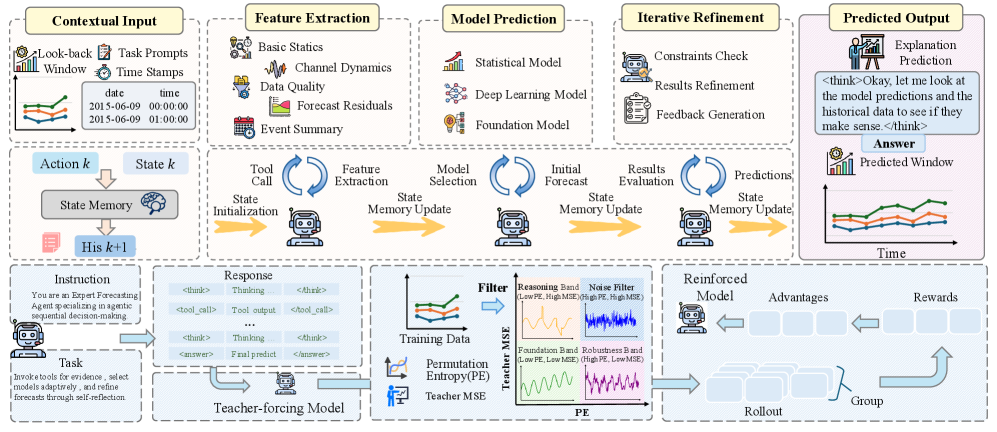
核心思路:Cast-R1的核心思路是将时序预测重新建模为一个序列决策问题。通过引入一个智能体,该智能体可以自主地与外部工具交互,提取有用的信息,并进行推理和预测。这种方法允许模型在预测过程中逐步积累证据,并根据新的信息迭代地改进预测结果。
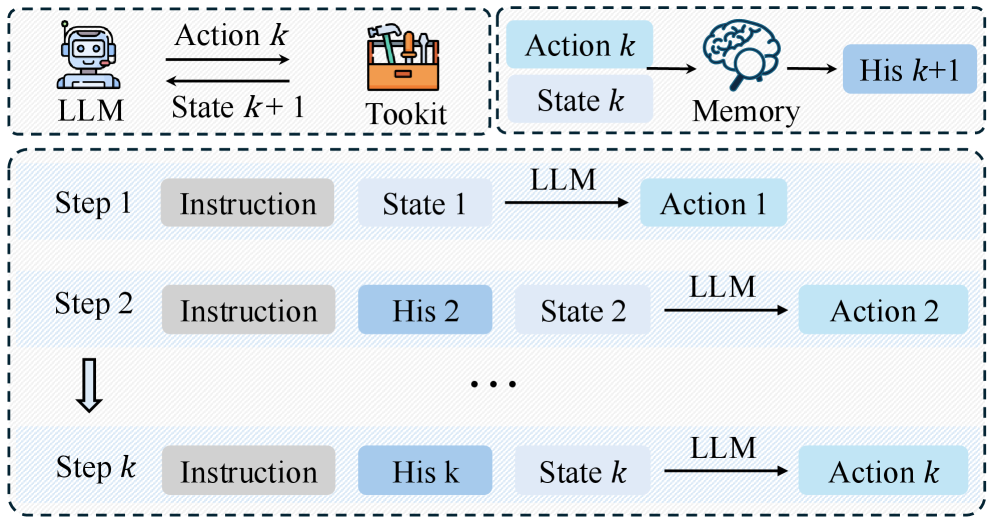
技术框架:Cast-R1的整体框架包含以下几个主要模块:1) 状态管理模块:使用基于内存的机制来维护决策相关的信息,并在交互步骤中更新状态。2) 工具包:包含各种工具,例如统计特征提取器和轻量级预测模型,用于提供决策支持。3) 智能体:负责与工具包交互,执行推理和预测,并通过自我反思迭代地改进预测结果。4) 学习模块:采用两阶段学习策略,包括监督微调和多轮强化学习,以及课程学习方案。
关键创新:Cast-R1的关键创新在于将时序预测问题转化为一个工具增强的序列决策问题。与传统的单次映射方法不同,Cast-R1允许模型通过与外部工具的交互来获取信息,并进行迭代的推理和预测。这种方法使得模型能够更好地适应复杂和动态的环境,并提高预测的准确性。
关键设计:Cast-R1采用两阶段学习策略。首先,使用监督学习对模型进行微调,使其能够初步学习预测任务。然后,使用多轮强化学习来训练智能体,使其能够自主地与工具包交互,并优化预测策略。此外,还使用课程学习来逐步增加任务难度,以提高策略学习的效果。具体的损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
论文在多个真实世界的时序数据集上进行了广泛的实验,结果表明Cast-R1显著优于传统的时序预测方法。具体的性能提升数据在论文中进行了详细的展示,证明了Cast-R1在复杂时序预测任务中的有效性。
🎯 应用场景
Cast-R1具有广泛的应用前景,例如金融市场预测、供应链管理、能源需求预测、医疗健康监测等。通过自主学习和迭代优化,Cast-R1能够更好地适应复杂和动态的环境,提高预测的准确性和可靠性,为决策者提供更有价值的信息,并最终提升相关领域的效率和效益。
📄 摘要(原文)
Time series forecasting has long been dominated by model-centric approaches that formulate prediction as a single-pass mapping from historical observations to future values. Despite recent progress, such formulations often struggle in complex and evolving settings, largely because most forecasting models lack the ability to autonomously acquire informative evidence, reason about potential future changes, or revise predictions through iterative decision processes. In this work, we propose Cast-R1, a learned time series forecasting framework that reformulates forecasting as a sequential decision-making problem. Cast-R1 introduces a memory-based state management mechanism that maintains decision-relevant information across interaction steps, enabling the accumulation of contextual evidence to support long-horizon reasoning. Building on this formulation, forecasting is carried out through a tool-augmented agentic workflow, in which the agent autonomously interacts with a modular toolkit to extract statistical features, invoke lightweight forecasting models for decision support, perform reasoning-based prediction, and iteratively refine forecasts through self-reflection. To train Cast-R1, we adopt a two-stage learning strategy that combines supervised fine-tuning with multi-turn reinforcement learning, together with a curriculum learning scheme that progressively increases task difficulty to improve policy learning. Extensive experiments on multiple real-world time series datasets demonstrate the effectiveness of Cast-R1. We hope this work provides a practical step towards further exploration of agentic paradigms for time series modeling. Our code is available at https://github.com/Xiaoyu-Tao/Cast-R1-TS.