MEMTS: Internalizing Domain Knowledge via Parameterized Memory for Retrieval-Free Domain Adaptation of Time Series Foundation Models
作者: Xiaoyun Yu, Li fan, Xiangfei Qiu, Nanqing Dong, Yonggui Huang, Honggang Qi, Geguang Pu, Wanli Ouyang, Xi Chen, Jilin Hu
分类: cs.LG
发布日期: 2026-02-14
💡 一句话要点
提出MEMTS,通过参数化记忆内化领域知识,实现时间序列基础模型的免检索领域自适应。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 领域自适应 知识蒸馏 免检索 基础模型 参数化记忆 知识持久性模块
📋 核心要点
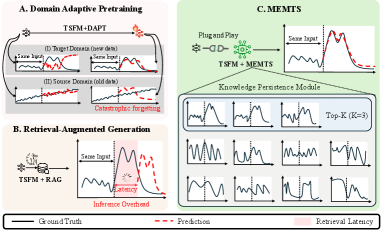
- 时间序列基础模型在特定领域面临时间分布偏移和领域周期性挑战,现有方法如DAPT易遗忘全局模式,RAG检索开销大。
- MEMTS通过知识持久性模块(KPM)将领域知识内化为可学习的潜在原型,实现免检索的领域自适应。
- 实验表明,MEMTS在多个数据集上实现了SOTA性能,同时缓解了灾难性遗忘,且推理延迟接近于零。
📝 摘要(中文)
时间序列基础模型(TSFMs)在广义预测中表现出色,但在具有时间分布偏移和领域特定周期结构的实际垂直领域中,性能显著下降。现有解决方案主要受限于两种范式:领域自适应预训练(DAPT),它改善了短期领域拟合,但由于灾难性遗忘,经常破坏先前学习的全局时间模式;以及检索增强生成(RAG),它结合了外部知识,但引入了大量的检索开销。这造成了严重的可扩展性瓶颈,无法满足实时流处理的高效率要求。为了打破这一僵局,我们提出了一种用于时间序列预测中免检索领域自适应的轻量级即插即用方法——时间序列记忆(MEMTS)。MEMTS的关键组件是知识持久性模块(KPM),它将领域特定的时间动态,如重复的季节性模式和趋势,内化为一组紧凑的可学习潜在原型。通过这样做,它将零散的历史观测转化为连续的、参数化的知识表示。这种范式转变使MEMTS能够以恒定时间的推理和接近零的延迟实现精确的领域自适应,同时有效地缓解了一般时间模式的灾难性遗忘,所有这些都不需要对冻结的TSFM骨干网络进行任何架构修改。在多个数据集上的大量实验证明了MEMTS的SOTA性能。
🔬 方法详解
问题定义:论文旨在解决时间序列基础模型在特定领域应用时,由于领域数据分布差异和特有周期性模式,导致模型性能显著下降的问题。现有的领域自适应预训练方法容易造成灾难性遗忘,破坏模型已学习的通用时间模式;而检索增强生成方法则引入了过高的检索开销,难以满足实时性要求。
核心思路:论文的核心思路是通过一个轻量级的知识持久性模块(KPM),将领域特定的时间动态(如季节性模式和趋势)编码成一组可学习的潜在原型。这些原型可以看作是对领域知识的压缩表示,从而避免了直接检索外部知识的开销,并减少了对原始时间序列基础模型结构的修改。
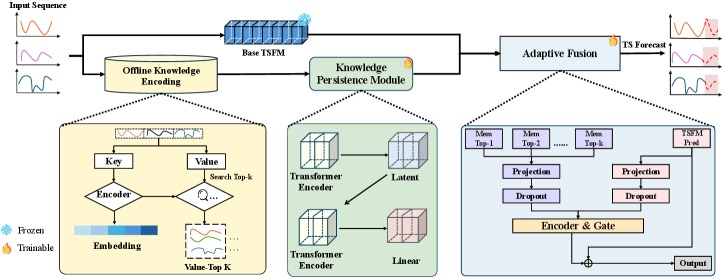
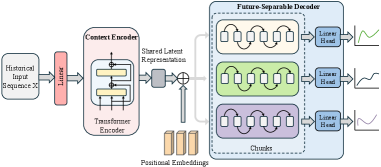
技术框架:MEMTS整体框架包含一个预训练的时间序列基础模型(TSFM)和一个知识持久性模块(KPM)。KPM接收输入时间序列,将其编码为潜在原型,然后将这些原型与TSFM的输出相结合,用于最终的预测。整个过程无需检索外部数据,实现了免检索的领域自适应。
关键创新:MEMTS的关键创新在于提出了知识持久性模块(KPM),它能够将领域知识内化为可学习的参数化表示。这种方法避免了检索外部知识带来的高延迟,同时缓解了领域自适应预训练可能导致的灾难性遗忘问题。与现有方法相比,MEMTS在效率和性能之间取得了更好的平衡。
关键设计:KPM的具体实现细节包括潜在原型的数量、初始化方式、以及如何与TSFM的输出进行融合。论文可能还涉及了特定的损失函数设计,用于训练KPM,使其能够有效地捕捉领域特定的时间动态。此外,如何选择合适的TSFM作为骨干网络,以及如何调整KPM的参数以适应不同的领域数据,也是关键的设计考虑。
🖼️ 关键图片
📊 实验亮点
MEMTS在多个时间序列数据集上取得了SOTA性能,显著优于现有的领域自适应方法。实验结果表明,MEMTS不仅能够有效提升预测精度,还能够显著降低推理延迟,使其能够满足实时应用的需求。具体的性能提升数据和对比基线需要在论文中查找。
🎯 应用场景
MEMTS具有广泛的应用前景,例如智能电网的电力负荷预测、金融市场的股票价格预测、以及工业生产过程中的设备状态监测等。该方法能够有效提升时间序列基础模型在特定领域的预测精度和效率,降低部署成本,并为实时决策提供支持。未来,MEMTS有望成为时间序列分析领域的重要工具。
📄 摘要(原文)
While Time Series Foundation Models (TSFMs) have demonstrated exceptional performance in generalized forecasting, their performance often degrades significantly when deployed in real-world vertical domains characterized by temporal distribution shifts and domain-specific periodic structures. Current solutions are primarily constrained by two paradigms: Domain-Adaptive Pretraining (DAPT), which improves short-term domain fitting but frequently disrupts previously learned global temporal patterns due to catastrophic forgetting; and Retrieval-Augmented Generation (RAG), which incorporates external knowledge but introduces substantial retrieval overhead. This creates a severe scalability bottleneck that fails to meet the high-efficiency requirements of real-time stream processing. To break this impasse, we propose Memory for Time Series (MEMTS), a lightweight and plug-and-play method for retrieval-free domain adaptation in time series forecasting. The key component of MEMTS is a Knowledge Persistence Module (KPM), which internalizes domain-specific temporal dynamics, such as recurring seasonal patterns and trends into a compact set of learnable latent prototypes. In doing so, it transforms fragmented historical observations into continuous, parameterized knowledge representations. This paradigm shift enables MEMTS to achieve accurate domain adaptation with constant-time inference and near-zero latency, while effectively mitigating catastrophic forgetting of general temporal patterns, all without requiring any architectural modifications to the frozen TSFM backbone. Extensive experiments on multiple datasets demonstrate the SOTA performance of MEMTS.