On Representation Redundancy in Large-Scale Instruction Tuning Data Selection
作者: Youwei Shu, Shaomian Zheng, Dingnan Jin, Wenjie Qu, Ziyao Guo, Qing Cui, Jun Zhou, Jiaheng Zhang
分类: cs.LG
发布日期: 2026-02-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出压缩表征数据选择(CRDS)框架,解决指令微调数据选择中的表征冗余问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 数据选择 表征学习 数据压缩 大型语言模型
📋 核心要点
- 现有LLM编码器在指令微调数据选择中产生高度冗余的语义嵌入,限制了数据质量和模型性能。
- 提出压缩表征数据选择(CRDS)框架,通过随机投影或白化降维减少表征冗余,提升数据质量。
- 实验表明CRDS显著提升数据质量,CRDS-W仅用3.5%数据超越全数据基线0.71%,验证了有效性。
📝 摘要(中文)
数据质量是大型语言模型训练的关键因素。虽然先前的工作表明,在较小的高质量数据集上训练的模型可以胜过在更大但嘈杂或低质量语料库上训练的模型,但工业规模指令微调中的系统数据选择方法仍未得到充分探索。本文从语义表征相似性的角度研究了指令微调数据选择,并确定了当前最先进的LLM编码器的一个关键限制:它们产生高度冗余的语义嵌入。为了缓解这种冗余,我们提出了一种新的压缩表征数据选择(CRDS)框架,该框架包含两个变体。CRDS-R应用Rademacher随机投影,然后连接Transformer隐藏层表征,而CRDS-W采用基于白化的降维方法来提高表征质量。实验结果表明,这两种变体都显著提高了数据质量,并且始终优于当前最先进的基于表征的选择方法。值得注意的是,CRDS-W仅使用3.5%的数据就实现了强大的性能,在四个数据集上的平均性能超过了全数据基线0.71%。我们的代码可在https://github.com/tdano1/CRDS 获得。
🔬 方法详解
问题定义:论文旨在解决大规模指令微调数据选择中,现有LLM编码器产生的语义表征高度冗余的问题。这种冗余导致数据质量下降,影响模型训练效果。现有方法难以有效去除冗余信息,导致模型在训练过程中学习到大量重复或无用的知识,降低了模型的泛化能力和效率。
核心思路:论文的核心思路是通过压缩语义表征来减少冗余信息,从而提升数据质量。具体而言,通过降维技术,将高维的语义表征压缩到低维空间,去除冗余维度,保留关键信息。这样可以使得模型在训练过程中更加关注重要的数据样本,提高训练效率和模型性能。
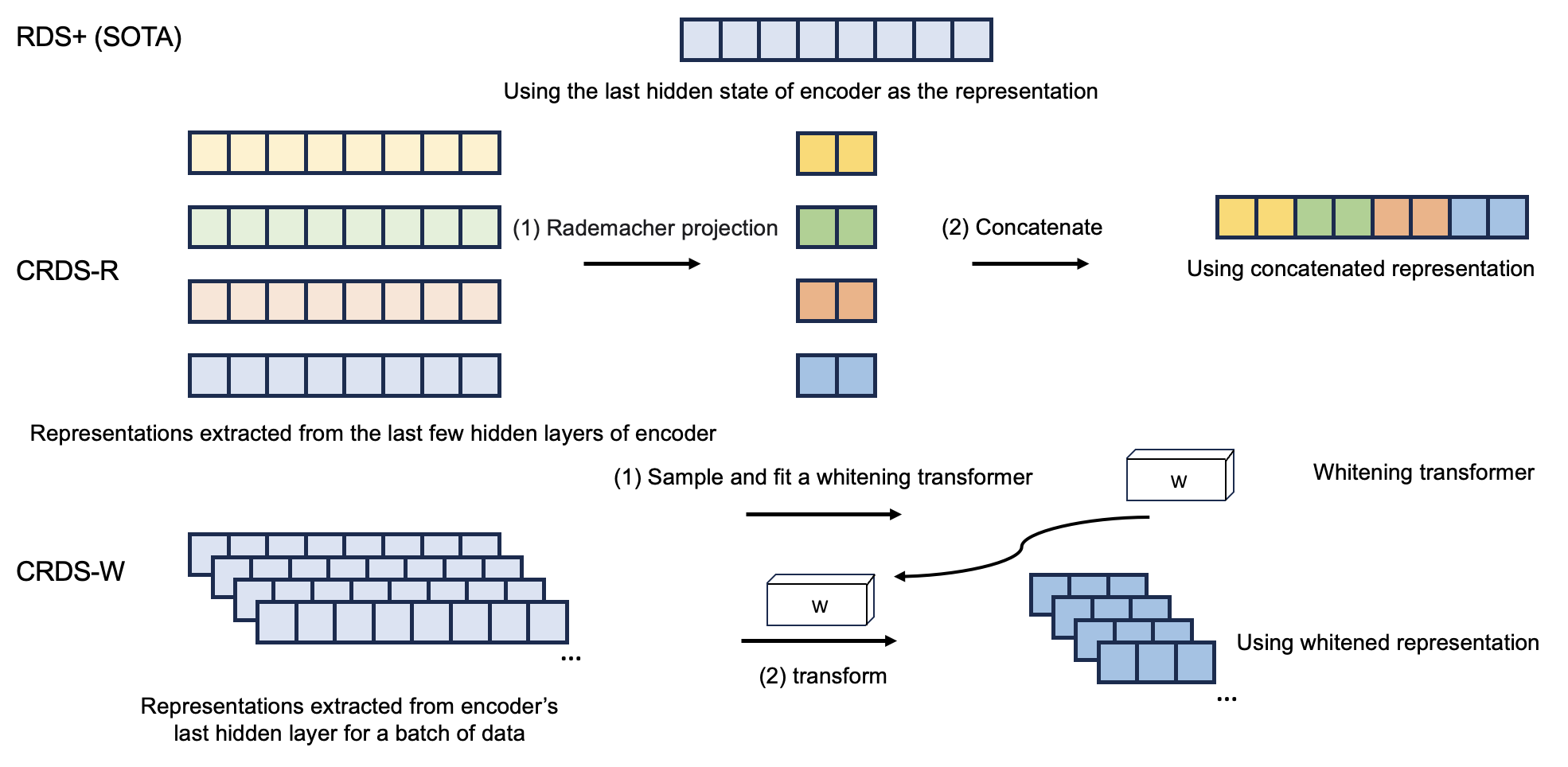
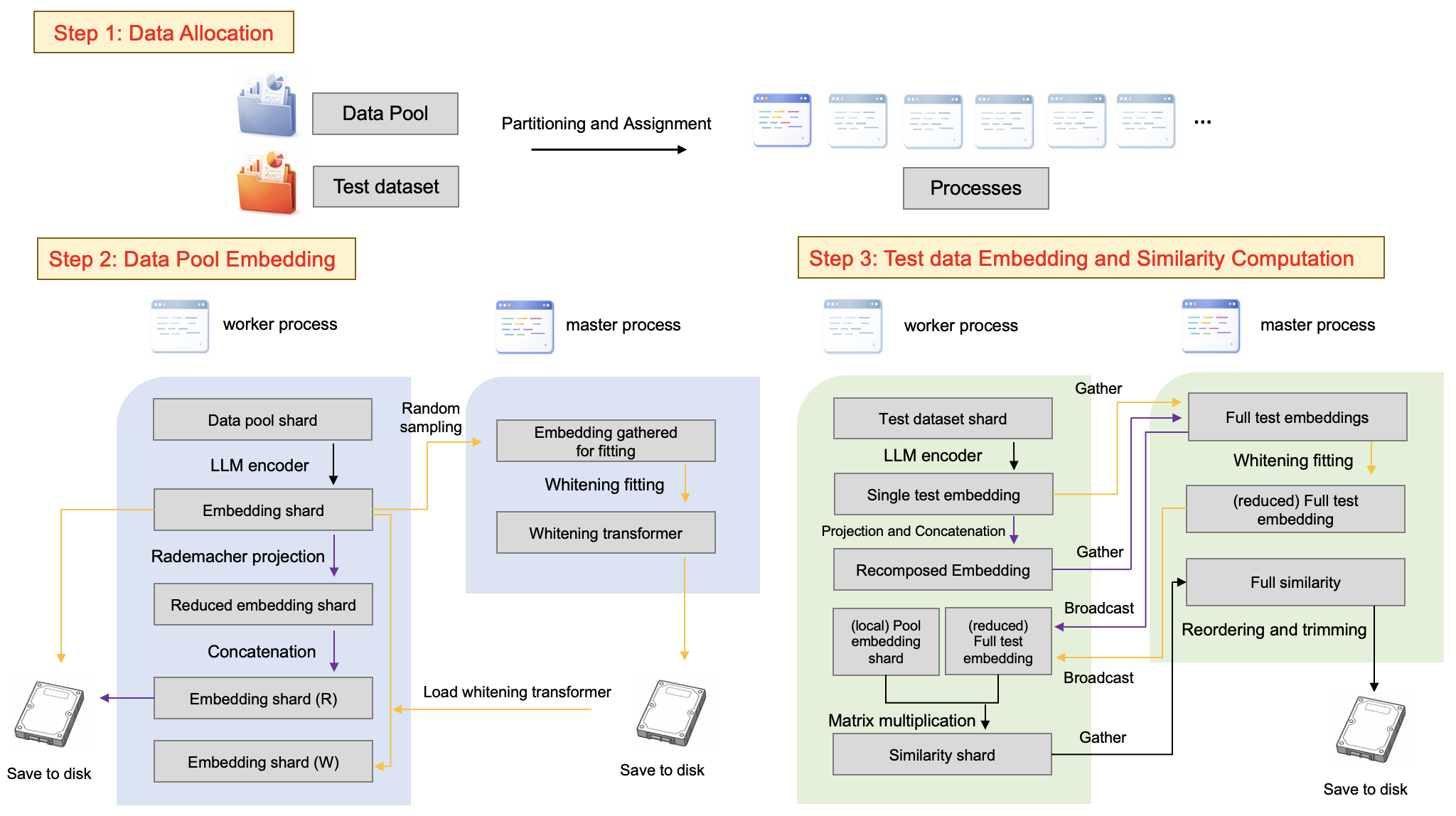
技术框架:CRDS框架包含两个主要变体:CRDS-R和CRDS-W。CRDS-R首先应用Rademacher随机投影来降低表征维度,然后连接Transformer的多个隐藏层表征。CRDS-W则采用基于白化的降维方法,直接对表征进行降维。两个变体都旨在减少表征冗余,提高数据质量。整体流程包括:1) 使用LLM编码器提取数据样本的语义表征;2) 使用CRDS-R或CRDS-W对表征进行压缩;3) 基于压缩后的表征进行数据选择。
关键创新:论文的关键创新在于提出了压缩表征数据选择(CRDS)框架,并设计了两种具体的压缩方法(CRDS-R和CRDS-W)。与现有方法相比,CRDS框架能够更有效地减少语义表征的冗余,从而提高数据质量。现有方法通常直接使用LLM编码器产生的表征进行数据选择,而忽略了表征中的冗余信息。CRDS框架通过显式地压缩表征,使得数据选择更加关注关键信息,提高了选择的准确性和效率。
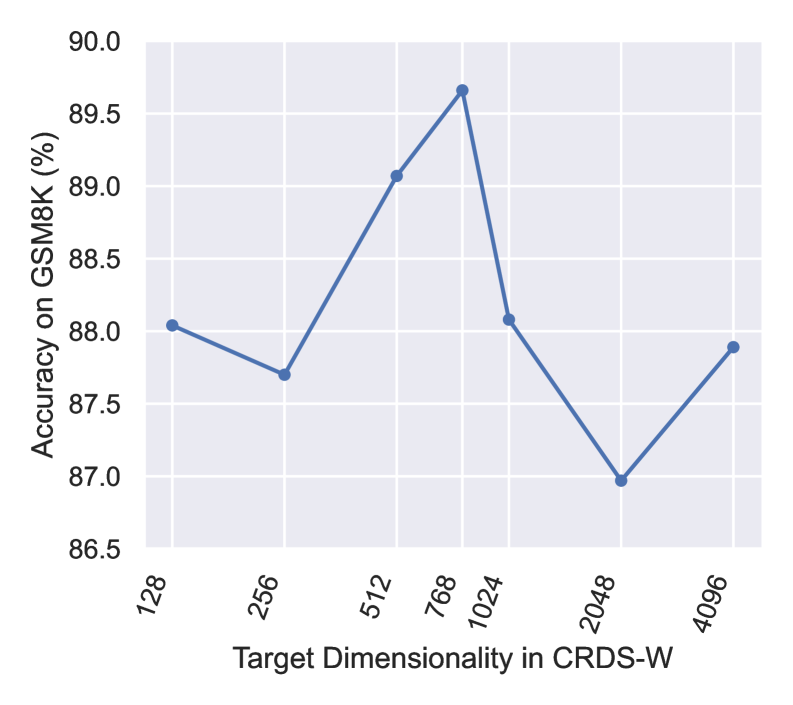
关键设计:CRDS-R的关键设计在于Rademacher随机投影,它是一种简单有效的降维方法,可以快速降低表征维度。CRDS-W的关键设计在于基于白化的降维方法,它可以去除表征中的相关性,使得表征更加独立。在参数设置方面,需要选择合适的降维维度,以平衡表征的压缩程度和信息损失。损失函数方面,论文可能没有引入新的损失函数,而是直接使用压缩后的表征进行数据选择,例如计算样本之间的相似度,选择相似度较低的样本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CRDS框架的两个变体(CRDS-R和CRDS-W)均显著提升了数据质量,并优于现有基于表征的选择方法。尤其值得注意的是,CRDS-W仅使用3.5%的数据,在四个数据集上的平均性能超过了全数据基线0.71%。这表明CRDS框架能够以极低的成本实现显著的性能提升。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的指令微调数据选择,尤其是在数据量庞大但质量参差不齐的情况下。通过CRDS框架,可以有效提升数据质量,降低训练成本,提高模型性能。此外,该方法也可应用于其他自然语言处理任务,例如文本分类、文本摘要等,通过减少表征冗余,提高模型对关键信息的关注度。
📄 摘要(原文)
Data quality is a crucial factor in large language models training. While prior work has shown that models trained on smaller, high-quality datasets can outperform those trained on much larger but noisy or low-quality corpora, systematic methods for industrial-scale data selection in instruction tuning remain underexplored. In this work, we study instruction-tuning data selection through the lens of semantic representation similarity and identify a key limitation of state-of-the-art LLM encoders: they produce highly redundant semantic embeddings. To mitigate this redundancy, we propose Compressed Representation Data Selection (CRDS), a novel framework with two variants. CRDS-R applies Rademacher random projection followed by concatenation of transformer hidden-layer representations, while CRDS-W employs whitening-based dimensionality reduction to improve representational quality. Experimental results demonstrate that both variants substantially enhance data quality and consistently outperform state-of-the-art representation-based selection methods. Notably, CRDS-W achieves strong performance using only 3.5% of the data, surpassing the full-data baseline by an average of 0.71% across four datasets. Our code is available at https://github.com/tdano1/CRDS.