Attention Head Entropy of LLMs Predicts Answer Correctness
作者: Sophie Ostmeier, Brian Axelrod, Maya Varma, Asad Aali, Yabin Zhang, Magdalini Paschali, Sanmi Koyejo, Curtis Langlotz, Akshay Chaudhari
分类: cs.LG
发布日期: 2026-02-14
💡 一句话要点
提出Head Entropy方法,利用LLM注意力头熵预测答案正确性,提升领域外泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 注意力机制 熵 答案正确性预测 领域外泛化
📋 核心要点
- 现有方法难以有效预测LLM答案的正确性,尤其是在领域外数据上泛化能力不足。
- Head Entropy通过分析注意力头的熵值,衡量注意力分散程度,从而预测答案正确性。
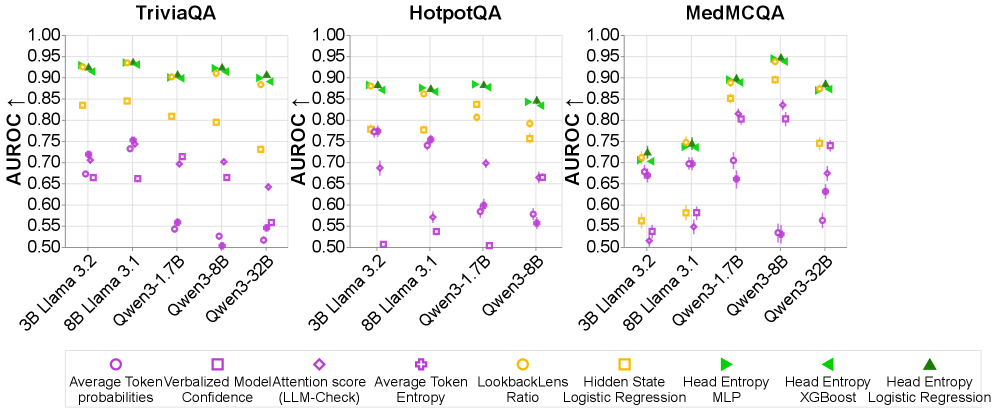
- 实验表明,Head Entropy在同分布和领域外数据集上均优于现有基线方法,尤其在领域外提升显著。
📝 摘要(中文)
大型语言模型(LLMs)经常生成看似合理但不正确的答案,这在医疗等安全关键领域构成风险。人工评估成本高昂,而LLM作为评判者的方法又可能引入隐藏的错误。最近的白盒方法通过关注注意力权重的分布来检测上下文幻觉,但两个问题仍然存在:这些方法是否能扩展到预测答案的正确性?它们是否能泛化到领域外?我们引入了Head Entropy,一种通过注意力熵模式预测答案正确性的方法,具体来说是测量注意力权重的分散程度。通过对每个注意力头的2-Renyi熵进行稀疏逻辑回归,Head Entropy在同分布情况下与基线方法相匹配或超过基线方法,并且在领域外具有更好的泛化能力,平均超过最接近的基线方法+8.5% AUROC。我们进一步表明,仅使用问题/上下文的注意力模式,在答案生成之前,就已经携带了预测信号,使用Head Entropy比最接近的基线方法平均高出+17.7% AUROC。我们在5个指令微调的LLM和3个QA数据集上进行了评估,这些数据集涵盖了通用知识、多跳推理和医学。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)生成答案的正确性预测问题,尤其关注现有方法在领域外数据上的泛化能力不足的痛点。现有方法要么依赖昂贵的人工评估,要么使用LLM自身进行判断,存在引入偏差的风险。此外,基于注意力权重的上下文幻觉检测方法,其预测答案正确性的能力以及领域外泛化能力有待提升。
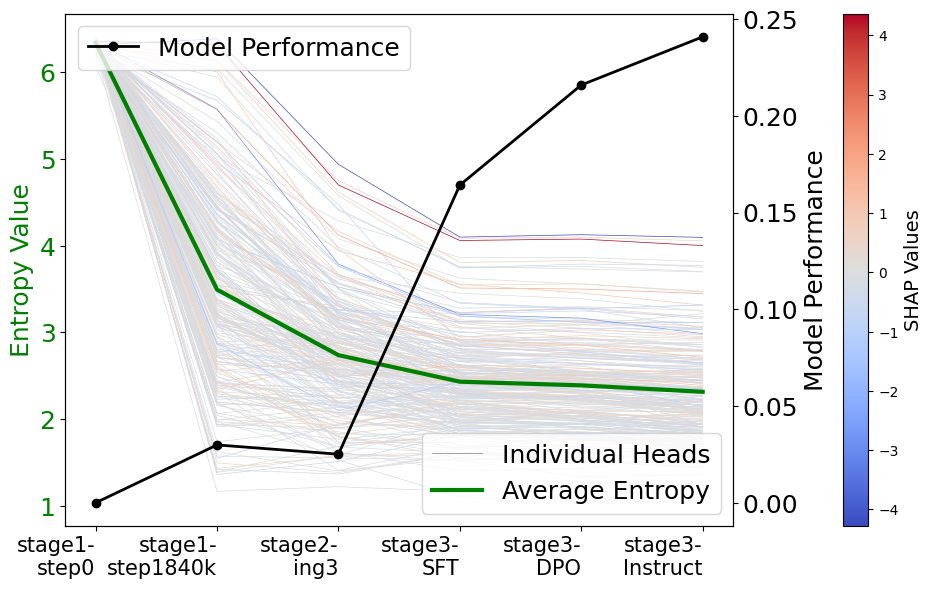
核心思路:论文的核心思路是利用LLM内部的注意力机制,通过分析注意力头的熵值来预测答案的正确性。作者认为,注意力权重分布的集中或分散程度蕴含了模型对答案的置信度信息。如果模型对答案更有把握,注意力可能会更集中在相关的token上,反之则会更分散。
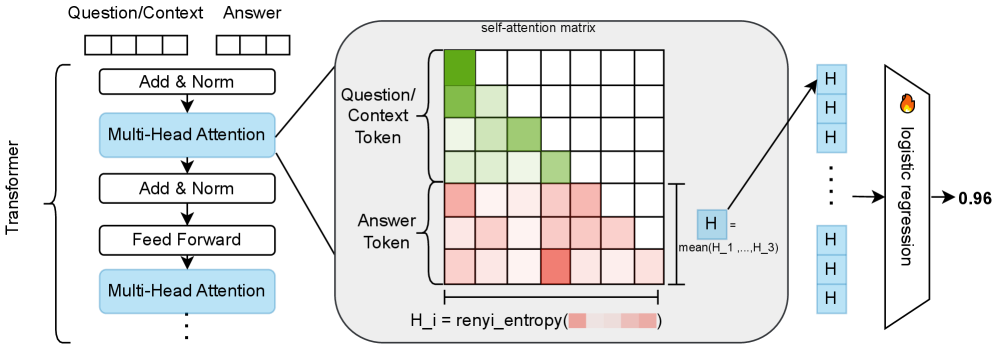
技术框架:Head Entropy方法主要包含以下几个阶段:1) 获取LLM在处理问题和上下文时的注意力权重;2) 计算每个注意力头的2-Renyi熵,用于衡量注意力权重的分散程度;3) 使用稀疏逻辑回归模型,将每个注意力头的熵值作为特征,训练一个分类器来预测答案的正确性。该框架的关键在于利用注意力头的熵值作为预测答案正确性的指标。
关键创新:该方法最重要的创新点在于提出了一种新的指标——Head Entropy,它能够有效地捕捉LLM在生成答案时的置信度信息。与现有方法相比,Head Entropy不仅能够预测答案的正确性,而且在领域外数据上具有更好的泛化能力。此外,该方法还发现,仅使用问题/上下文的注意力模式,在答案生成之前,就已经携带了预测信号。
关键设计:论文的关键设计包括:1) 使用2-Renyi熵来衡量注意力权重的分散程度,因为它对异常值更敏感;2) 使用稀疏逻辑回归模型,可以自动选择对预测答案正确性有用的注意力头,提高模型的泛化能力;3) 实验中使用了多个指令微调的LLM和多个QA数据集,以验证Head Entropy的有效性和鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Head Entropy在同分布情况下与基线方法相匹配或超过基线方法,并且在领域外具有更好的泛化能力,平均超过最接近的基线方法+8.5% AUROC。更重要的是,仅使用问题/上下文的注意力模式,Head Entropy比最接近的基线方法平均高出+17.7% AUROC,这表明在答案生成之前,注意力模式就已经携带了预测信号。
🎯 应用场景
该研究成果可应用于医疗、金融等安全关键领域,帮助识别LLM生成的错误答案,降低风险。通过Head Entropy,可以更可靠地利用LLM辅助决策,提高工作效率。未来,该方法有望扩展到其他自然语言处理任务,例如文本摘要、机器翻译等,提升模型的可信度和可靠性。
📄 摘要(原文)
Large language models (LLMs) often generate plausible yet incorrect answers, posing risks in safety-critical settings such as medicine. Human evaluation is expensive, and LLM-as-judge approaches risk introducing hidden errors. Recent white-box methods detect contextual hallucinations using model internals, focusing on the localization of the attention mass, but two questions remain open: do these approaches extend to predicting answer correctness, and do they generalize out-of-domains? We introduce Head Entropy, a method that predicts answer correctness from attention entropy patterns, specifically measuring the spread of the attention mass. Using sparse logistic regression on per-head 2-Renyi entropies, Head Entropy matches or exceeds baselines in-distribution and generalizes substantially better on out-of-domains, it outperforms the closest baseline on average by +8.5% AUROC. We further show that attention patterns over the question/context alone, before answer generation, already carry predictive signal using Head Entropy with on average +17.7% AUROC over the closest baseline. We evaluate across 5 instruction-tuned LLMs and 3 QA datasets spanning general knowledge, multi-hop reasoning, and medicine.