Benchmark Leakage Trap: Can We Trust LLM-based Recommendation?
作者: Mingqiao Zhang, Qiyao Peng, Yumeng Wang, Chunyuan Liu, Hongtao Liu
分类: cs.LG
发布日期: 2026-02-14
🔗 代码/项目: GITHUB
💡 一句话要点
揭示LLM推荐系统中的基准泄漏陷阱,评估可靠性面临挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推荐系统 数据泄漏 基准评估 持续预训练 性能评估 领域适应 推荐算法
📋 核心要点
- 现有LLM推荐系统评估未充分考虑基准数据泄漏问题,导致性能评估失真。
- 通过模拟不同数据泄漏场景,研究域内和域外数据泄漏对LLM推荐性能的影响。
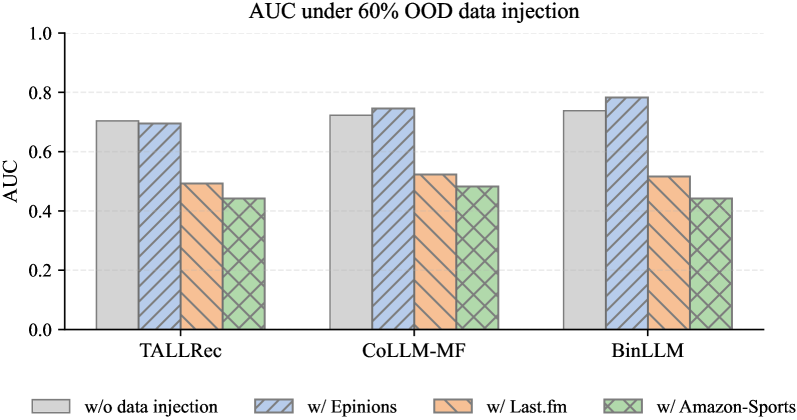
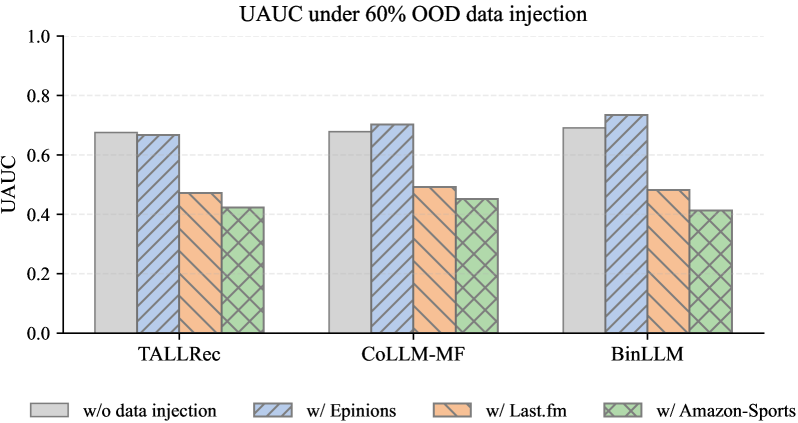
- 实验表明,域内数据泄漏会虚假提升性能,而域外数据泄漏则会降低性能。
📝 摘要(中文)
大型语言模型(LLM)在推荐系统中的日益普及对评估的可靠性提出了严峻挑战。本文识别并研究了一个先前被忽视的问题:基于LLM的推荐系统中的基准数据泄漏。当LLM在预训练或微调过程中接触并可能记忆基准数据集时,就会发生这种现象,从而导致人为夸大的性能指标,而这些指标未能反映模型的真实性能。为了验证这种现象,我们通过在策略性混合语料库上对基础模型进行持续预训练来模拟各种数据泄漏场景,这些语料库包括来自域内和域外来源的用户-项目交互。我们的实验揭示了数据泄漏的双重效应:当泄漏的数据与领域相关时,它会产生显著但虚假的性能提升,从而误导性地夸大模型的能力。相反,与领域无关的泄漏通常会降低推荐准确性,突显了这种污染的复杂性和偶然性。我们的研究结果表明,数据泄漏是基于LLM的推荐系统中一个关键的、先前未被考虑的因素,它可能会影响模型的真实性能。我们在https://github.com/yusba1/LLMRec-Data-Leakage 上发布了我们的代码。
🔬 方法详解
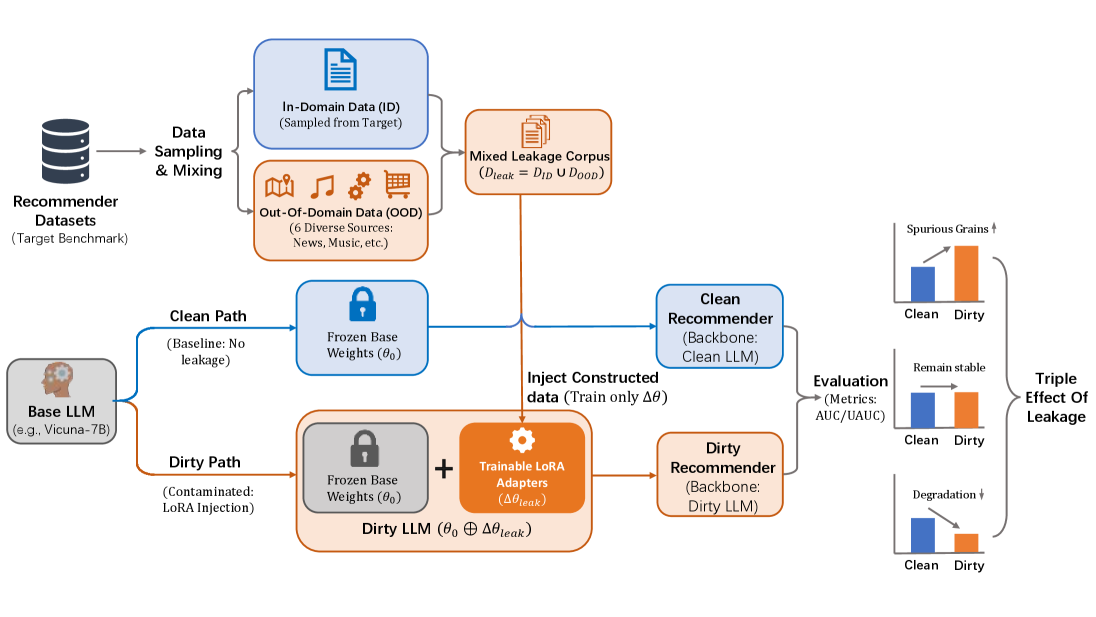
问题定义:论文旨在解决LLM在推荐系统中应用时,由于预训练或微调阶段接触到基准数据集而导致的性能评估偏差问题。现有方法未能充分考虑数据泄漏的影响,使得评估结果无法真实反映模型的泛化能力。
核心思路:核心思路是通过模拟不同程度和类型的基准数据泄漏,观察LLM推荐模型的性能变化。通过控制泄漏数据的领域相关性,分析其对模型性能的正面和负面影响,从而揭示数据泄漏对评估结果的干扰。
技术框架:论文采用持续预训练的方式模拟数据泄漏。首先,选择一个基础LLM模型。然后,构建包含不同比例和类型的用户-项目交互数据的语料库,用于持续预训练。语料库包括:1)原始预训练数据;2)域内基准数据集;3)域外基准数据集。最后,在标准的推荐任务上评估模型的性能,并分析不同泄漏场景下的性能差异。
关键创新:该研究的关键创新在于首次系统性地研究了LLM推荐系统中的基准数据泄漏问题。通过实验验证了数据泄漏对模型性能评估的显著影响,并揭示了域内和域外数据泄漏的不同效应。这为更可靠地评估LLM推荐系统提供了新的视角。
关键设计:实验中,关键的设计包括:1)控制泄漏数据的比例,模拟不同程度的泄漏;2)区分域内和域外数据,研究不同类型泄漏的影响;3)选择合适的评估指标,如Recall@K和NDCG@K,衡量推荐性能;4)采用持续预训练的方式,模拟LLM在实际应用中可能遇到的数据泄漏情况。
🖼️ 关键图片
📊 实验亮点
实验结果表明,域内数据泄漏会导致推荐性能的显著提升,但这种提升是虚假的,不能反映模型的真实泛化能力。相反,域外数据泄漏通常会降低推荐准确性。例如,在特定数据集上,域内数据泄漏可能导致Recall@K指标提升超过20%,而域外数据泄漏则可能导致该指标下降超过10%。
🎯 应用场景
该研究成果可应用于评估和改进基于LLM的推荐系统。通过识别和控制数据泄漏,可以更准确地评估模型的真实性能,避免过度依赖在泄漏数据上获得的虚假性能提升。这有助于开发更可靠、更泛化的推荐系统,并为未来的LLM推荐系统评估提供指导。
📄 摘要(原文)
The expanding integration of Large Language Models (LLMs) into recommender systems poses critical challenges to evaluation reliability. This paper identifies and investigates a previously overlooked issue: benchmark data leakage in LLM-based recommendation. This phenomenon occurs when LLMs are exposed to and potentially memorize benchmark datasets during pre-training or fine-tuning, leading to artificially inflated performance metrics that fail to reflect true model performance. To validate this phenomenon, we simulate diverse data leakage scenarios by conducting continued pre-training of foundation models on strategically blended corpora, which include user-item interactions from both in-domain and out-of-domain sources. Our experiments reveal a dual-effect of data leakage: when the leaked data is domain-relevant, it induces substantial but spurious performance gains, misleadingly exaggerating the model's capability. In contrast, domain-irrelevant leakage typically degrades recommendation accuracy, highlighting the complex and contingent nature of this contamination. Our findings reveal that data leakage acts as a critical, previously unaccounted-for factor in LLM-based recommendation, which could impact the true model performance. We release our code at https://github.com/yusba1/LLMRec-Data-Leakage.