LCSB: Layer-Cyclic Selective Backpropagation for Memory-Efficient On-Device LLM Fine-Tuning
作者: Juneyoung Park, Eunbeen Yoon, Seongwan Kim. Jaeho Lee
分类: cs.LG, cs.CL
发布日期: 2026-02-13
备注: Under the review, 13 pages
💡 一句话要点
提出层循环选择反向传播(LCSB),实现低内存设备上LLM高效微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源微调 大型语言模型 反向传播优化 移动设备 量化训练
📋 核心要点
- 现有内存高效反向传播(MeBP)虽能在低内存设备上微调LLM,但反向计算耗时,权重解压占比高。
- 提出层循环选择反向传播(LCSB),每步仅计算部分层梯度,利用残差连接和AdamW动量保证更新。
- 实验表明,LCSB在保证模型性能的前提下,显著加速微调过程,并在量化场景下提升训练稳定性。
📝 摘要(中文)
本文提出了一种内存高效的反向传播方法(MeBP),旨在使大型语言模型(LLM)能够在内存小于1GB的移动设备上进行一阶微调。尽管MeBP实现了低内存微调,但它需要在每一步都通过所有Transformer层进行反向计算,其中仅权重解压缩就占用了32-42%的反向传播时间。为此,我们提出了层循环选择反向传播(LCSB),该方法在每一步仅计算一部分层的梯度。我们的核心思想是,残差连接保证了梯度通过恒等路径的流动,而AdamW动量为未选择的层提供了隐式更新。我们将LCSB解释为LoRA参数空间上的块坐标下降,并提供了收敛性的理论证明。在五个模型和三个任务上,LCSB实现了高达1.40倍的加速,而质量下降小于2%。令人惊讶的是,在4位量化设置中,LCSB表现出卓越的稳定性:一个在完全反向传播下完全发散的3B模型在使用LCSB时平稳收敛,这表明选择性梯度计算具有隐式的正则化效果。
🔬 方法详解
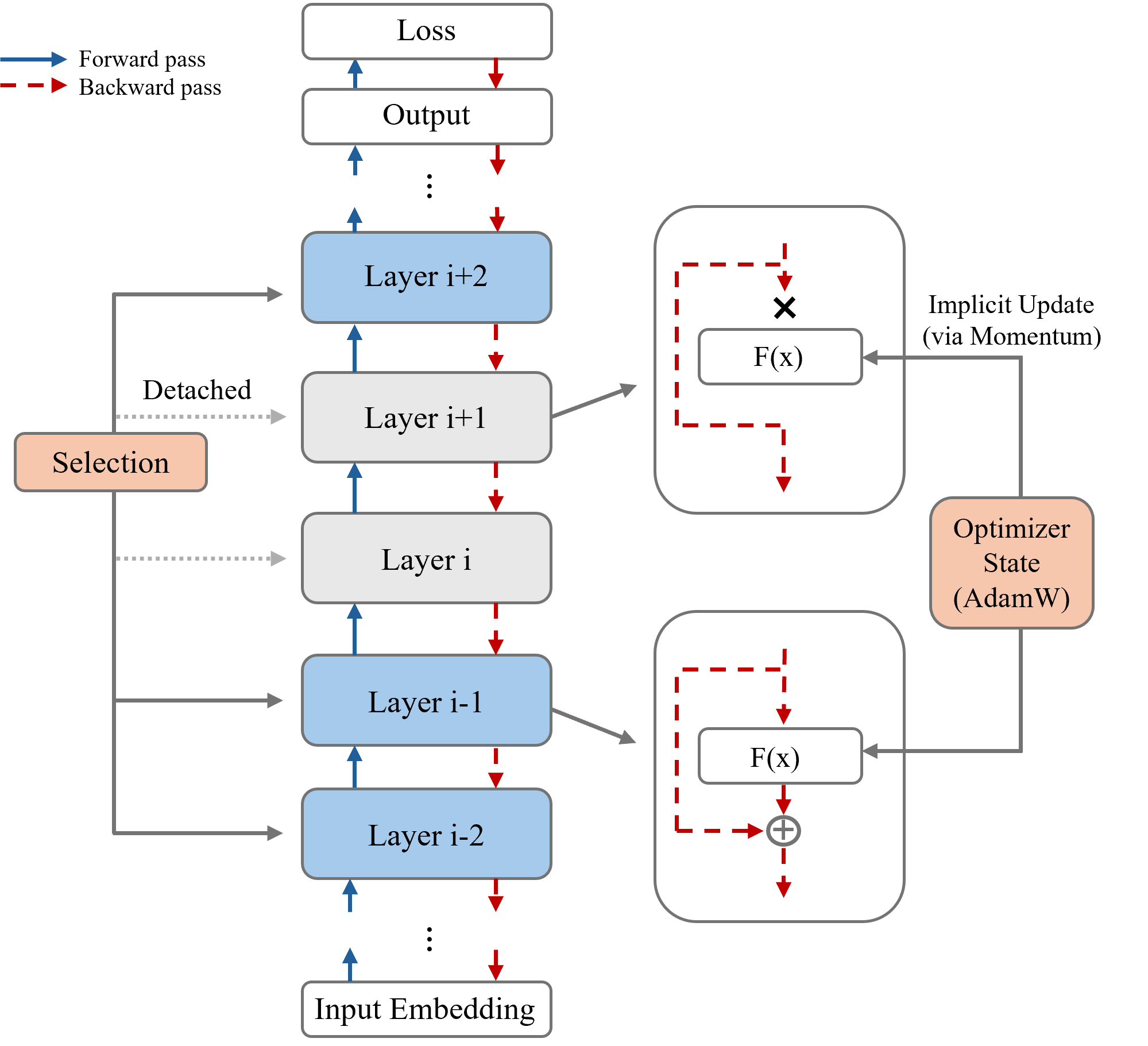
问题定义:论文旨在解决在资源受限的移动设备上微调大型语言模型(LLM)时,内存高效反向传播(MeBP)方法计算开销大的问题。MeBP虽然降低了内存占用,但需要在每一步都对所有Transformer层进行反向传播,其中权重解压缩占据了大量时间,成为性能瓶颈。
核心思路:论文的核心思路是选择性地进行反向传播,即在每个训练步骤中,只更新部分Transformer层的参数。这种方法基于两个关键观察:一是Transformer中的残差连接保证了梯度可以通过恒等映射传播;二是AdamW优化器的动量项可以为未被显式更新的层提供隐式的参数更新。通过周期性地选择不同的层进行更新,可以实现对整个模型的有效微调,同时显著降低计算成本。
技术框架:LCSB的整体框架是在标准的LLM微调流程中引入层选择机制。具体来说,训练过程被划分为多个循环,每个循环包含若干个训练步骤。在每个步骤中,首先根据预定义的策略选择一个或多个Transformer层进行梯度计算和参数更新。然后,只对选定的层进行反向传播,计算梯度并更新参数。对于未被选中的层,则不进行显式的梯度计算和参数更新,而是依赖于残差连接和AdamW动量进行隐式更新。
关键创新:LCSB的关键创新在于选择性反向传播的策略,它通过只更新部分层来降低计算复杂度,同时利用残差连接和AdamW动量来保证模型的收敛性。与传统的MeBP方法相比,LCSB避免了对所有层进行反向传播,从而显著减少了计算时间和内存占用。此外,论文还将LCSB解释为LoRA参数空间上的块坐标下降,并提供了收敛性的理论证明。
关键设计:LCSB的关键设计包括:1) 层选择策略:可以采用不同的策略来选择需要更新的层,例如随机选择、轮流选择等。2) 循环周期:需要合理设置循环周期,以保证每个层都能得到充分的更新。3) AdamW优化器:利用AdamW优化器的动量项来为未选择的层提供隐式更新。4) LoRA参数空间:将LCSB解释为LoRA参数空间上的块坐标下降,为算法的收敛性提供了理论依据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LCSB在五个模型和三个任务上实现了高达1.40倍的加速,而质量下降小于2%。更令人惊讶的是,在4位量化设置中,一个在完全反向传播下完全发散的3B模型在使用LCSB时平稳收敛,这表明选择性梯度计算具有隐式的正则化效果。这些结果表明LCSB在内存效率和训练稳定性方面具有显著优势。
🎯 应用场景
LCSB技术可广泛应用于移动设备、嵌入式系统等资源受限场景下的大型语言模型微调。它降低了对硬件的要求,使得在本地设备上进行个性化模型定制成为可能,例如智能助手、离线翻译、文本生成等应用。该技术还有助于保护用户数据隐私,减少对云端服务器的依赖。
📄 摘要(原文)
Memory-efficient backpropagation (MeBP) has enabled first-order fine-tuning of large language models (LLMs) on mobile devices with less than 1GB memory. However, MeBP requires backward computation through all transformer layers at every step, where weight decompression alone accounts for 32--42% of backward time. We propose Layer-Cyclic Selective Backpropagation (LCSB), which computes gradients for only a subset of layers per step. Our key insight is that residual connections guarantee gradient flow through identity paths, while AdamW momentum provides implicit updates for non-selected layers. We interpret LCSB as Block Coordinate Descent on the LoRA parameter space, providing theoretical justification for convergence. LCSB achieves up to 1.40$\times$ speedup with less than 2\% quality degradation across five models and three tasks. Surprisingly, in 4-bit quantized settings, LCSB exhibits superior stability: a 3B model that completely diverges under full backpropagation converges smoothly with LCSB, suggesting an implicit regularization effect from selective gradient computation.