Memory-Efficient Structured Backpropagation for On-Device LLM Fine-Tuning
作者: Juneyoung Park, Yuri Hong, Seongwan Kim, Jaeho Lee
分类: cs.LG, cs.CL
发布日期: 2026-02-13
备注: Under the review, 11 pages
💡 一句话要点
提出内存高效的结构化反向传播以解决设备端LLM微调问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内存高效 结构化反向传播 设备端微调 大型语言模型 隐私保护
📋 核心要点
- 现有方法在内存使用上存在权衡,导致精确梯度和低内存估计之间的选择困难。
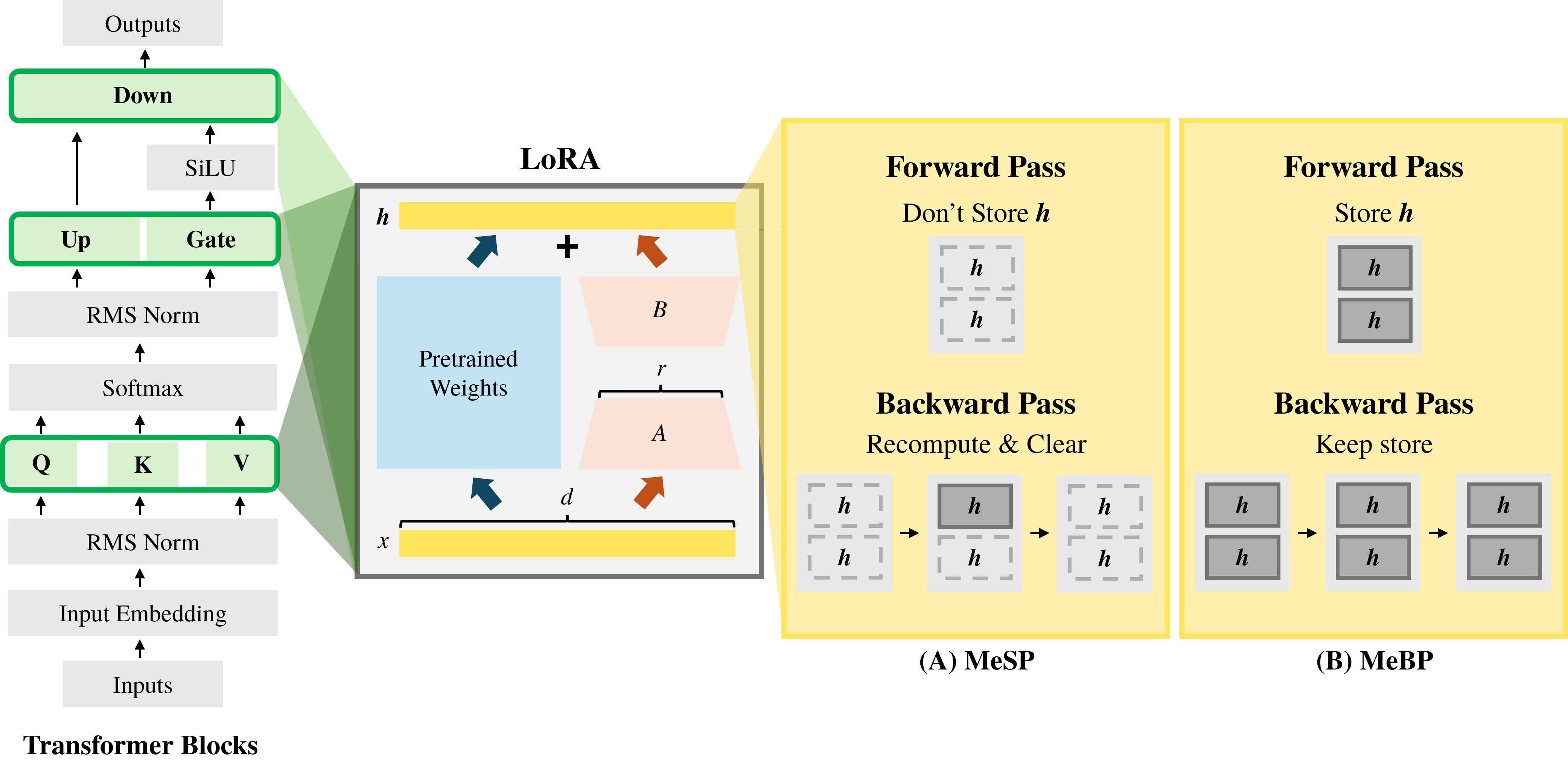
- 提出的MeSP方法通过利用LoRA的低秩结构,手动推导反向传播过程,从而减少内存需求。
- MeSP在Qwen2.5-0.5B模型上将峰值内存从361MB降低至136MB,显著提升了微调的可行性。
📝 摘要(中文)
设备端微调能够实现隐私保护的个性化大型语言模型,但移动设备的内存限制通常在6至12GB之间,现有方法在高内存的精确梯度和低内存的噪声估计之间存在权衡。本文提出了内存高效的结构化反向传播(MeSP),通过手动推导利用LoRA低秩结构的反向传播过程,消除了存储中间投影的需求,从而在计算上实现了相同的梯度。MeSP在Qwen2.5模型上实现了49%的平均内存减少,显著降低了峰值内存,支持在内存受限设备上的微调场景。
🔬 方法详解
问题定义:本文旨在解决在内存受限的移动设备上进行大型语言模型微调时的内存不足问题。现有方法如MeBP和MeZO在内存使用和梯度精确度之间存在显著的权衡,导致微调效率低下。
核心思路:MeSP方法的核心思路是通过手动推导反向传播过程,利用LoRA的低秩结构,减少中间结果的存储需求。具体而言,反向传播中的中间投影可以在反向计算时以最低成本重新计算,从而避免存储。
技术框架:MeSP的整体架构包括数据输入、前向传播、反向传播和梯度更新四个主要模块。在反向传播阶段,通过重新计算中间投影,降低内存占用。
关键创新:MeSP的主要创新在于通过手动推导反向传播过程,消除了对中间结果的存储需求,从而在内存使用上实现了显著优化。与现有方法相比,MeSP在计算上生成相同的梯度,但内存占用显著降低。
关键设计:在MeSP中,关键设计包括对低秩结构的利用,选择合适的参数设置以优化内存使用,以及在反向传播过程中动态计算中间结果,确保梯度计算的准确性。具体的损失函数和网络结构设计也经过精心调整,以适应内存限制。
🖼️ 关键图片
📊 实验亮点
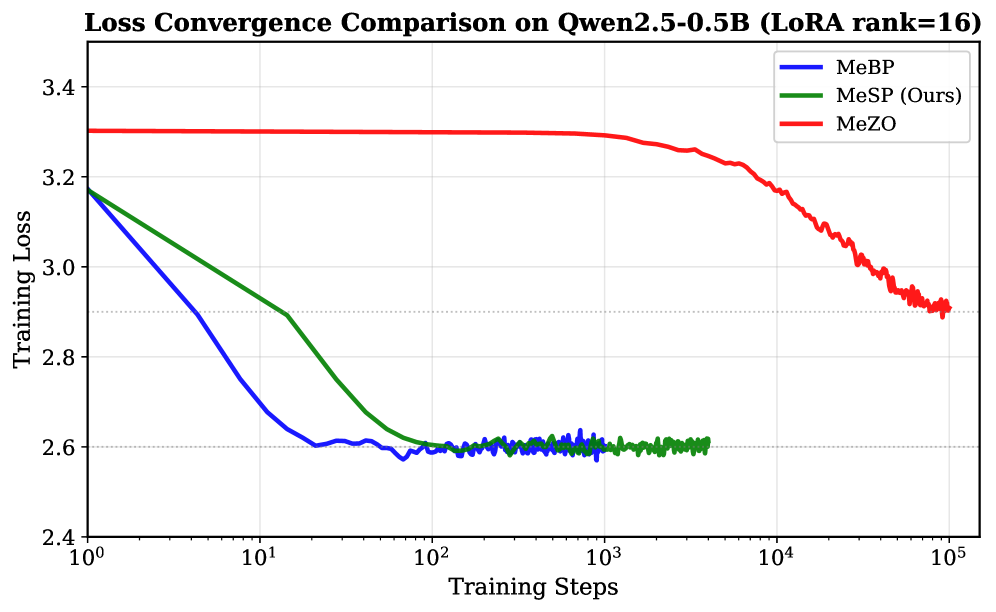
MeSP在Qwen2.5-0.5B模型上实现了49%的内存减少,峰值内存从361MB降低至136MB,同时计算出的梯度与MeBP方法完全一致。这一结果显著提升了在内存受限设备上进行微调的可行性,解决了以往方法的不足。
🎯 应用场景
该研究的潜在应用领域包括移动设备上的个性化AI助手、智能手机中的自然语言处理应用以及其他需要隐私保护的场景。通过降低内存需求,MeSP使得在资源受限的设备上进行大型语言模型的微调成为可能,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
On-device fine-tuning enables privacy-preserving personalization of large language models, but mobile devices impose severe memory constraints, typically 6--12GB shared across all workloads. Existing approaches force a trade-off between exact gradients with high memory (MeBP) and low memory with noisy estimates (MeZO). We propose Memory-efficient Structured Backpropagation (MeSP), which bridges this gap by manually deriving backward passes that exploit LoRA's low-rank structure. Our key insight is that the intermediate projection $h = xA$ can be recomputed during backward at minimal cost since rank $r \ll d_{in}$, eliminating the need to store it. MeSP achieves 49\% average memory reduction compared to MeBP on Qwen2.5 models (0.5B--3B) while computing mathematically identical gradients. Our analysis also reveals that MeZO's gradient estimates show near-zero correlation with true gradients (cosine similarity $\approx$0.001), explaining its slow convergence. MeSP reduces peak memory from 361MB to 136MB for Qwen2.5-0.5B, enabling fine-tuning scenarios previously infeasible on memory-constrained devices.