Quantization-Aware Collaborative Inference for Large Embodied AI Models
作者: Zhonghao Lyu, Ming Xiao, Mikael Skoglund, Merouane Debbah, H. Vincent Poor
分类: cs.LG, eess.SP
发布日期: 2026-02-13
💡 一句话要点
提出量化感知协同推理,优化边缘具身智能大模型的推理性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化感知 协同推理 具身智能 边缘计算 率失真优化
📋 核心要点
- 大型AI模型在具身智能应用中面临资源限制,现有方法难以兼顾推理质量、延迟和能耗。
- 论文提出量化感知协同推理,通过近似量化失真,优化量化比特宽度和计算频率的联合设计。
- 实验验证了失真近似的有效性,证明了联合设计在边缘设备上平衡推理质量、延迟和能耗的优势。
📝 摘要(中文)
大型人工智能模型(LAIMs)正日益成为具身智能应用的核心智能引擎。然而,LAIMs 庞大的参数规模和计算需求对资源受限的具身智能体提出了重大挑战。为了解决这个问题,我们研究了具身智能系统的量化感知协同推理(co-inference)。首先,我们为量化引起的推理失真开发了一个易于处理的近似。基于此近似,我们推导了量化率-推理失真函数的上下界,描述了其对 LAIM 统计量(包括量化比特宽度)的依赖性。接下来,我们在延迟和能量约束下,制定了一个联合量化比特宽度和计算频率设计问题,旨在最小化失真上界,同时通过相应的下界确保紧密性。广泛的评估验证了所提出的失真近似、推导的率失真界限以及所提出的联合设计的有效性。特别是,仿真和真实测试平台实验证明了所提出的联合设计在平衡边缘具身智能系统中的推理质量、延迟和能耗方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大型具身智能模型在资源受限的边缘设备上部署时,由于模型参数量巨大和计算复杂度高而导致的推理延迟高、能耗大以及推理精度下降的问题。现有方法通常难以在推理质量、延迟和能耗之间取得良好的平衡,尤其是在量化等模型压缩技术引入后,推理失真难以精确建模和优化。
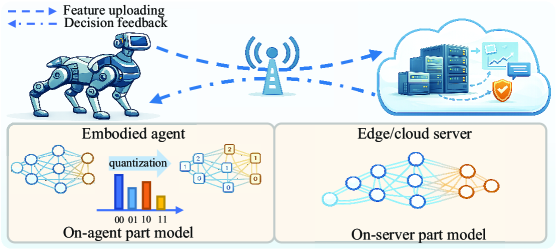
核心思路:论文的核心思路是利用量化感知协同推理,通过在边缘设备和云端之间协同进行推理计算,并结合量化技术来降低计算和存储开销。关键在于建立量化比特宽度与推理失真之间的关系模型,并以此为基础进行联合优化,从而在满足延迟和能量约束的前提下,最小化推理失真。
技术框架:整体框架包含以下几个主要步骤:1) 建立量化失真近似模型,推导量化率-失真函数的上下界,描述其与量化比特宽度的关系;2) 制定联合优化问题,在延迟和能量约束下,最小化失真上界,并利用下界保证优化结果的有效性;3) 设计优化算法,求解联合优化问题,得到最优的量化比特宽度和计算频率配置;4) 在边缘设备和云端协同执行推理任务,根据优化后的配置进行计算和数据传输。
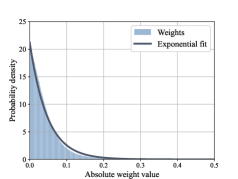
关键创新:论文的关键创新在于提出了一个可处理的量化失真近似模型,能够有效地描述量化比特宽度对推理精度的影响。此外,论文还推导了量化率-失真函数的上下界,为联合优化提供了理论基础。与现有方法相比,该方法能够更精确地建模量化带来的影响,并进行更有效的资源分配和优化。
关键设计:论文的关键设计包括:1) 量化失真近似模型的具体形式,例如采用泰勒展开或其他近似方法;2) 量化率-失真函数的上下界的具体表达式,以及如何利用这些界限进行优化;3) 联合优化问题的目标函数和约束条件,例如延迟约束、能量约束和推理精度要求;4) 优化算法的具体实现,例如采用凸优化、动态规划或其他启发式算法。
🖼️ 关键图片

📊 实验亮点
论文通过仿真和真实测试平台实验验证了所提出的量化失真近似、率失真界限以及联合设计的有效性。实验结果表明,该方法能够在保证推理精度的前提下,显著降低延迟和能耗。例如,在某个具体实验中,与传统方法相比,该方法可以将推理延迟降低20%,能耗降低15%,同时保持推理精度在可接受的范围内。
🎯 应用场景
该研究成果可应用于各种边缘具身智能场景,例如机器人导航、智能家居、自动驾驶等。通过优化模型量化和协同推理策略,可以在资源受限的边缘设备上部署更大规模、更复杂的AI模型,提升智能体的感知和决策能力,同时降低延迟和能耗,提高用户体验和系统效率。未来,该研究可以进一步扩展到多智能体协同推理、异构计算平台等更复杂的场景。
📄 摘要(原文)
Large artificial intelligence models (LAIMs) are increasingly regarded as a core intelligence engine for embodied AI applications. However, the massive parameter scale and computational demands of LAIMs pose significant challenges for resource-limited embodied agents. To address this issue, we investigate quantization-aware collaborative inference (co-inference) for embodied AI systems. First, we develop a tractable approximation for quantization-induced inference distortion. Based on this approximation, we derive lower and upper bounds on the quantization rate-inference distortion function, characterizing its dependence on LAIM statistics, including the quantization bit-width. Next, we formulate a joint quantization bit-width and computation frequency design problem under delay and energy constraints, aiming to minimize the distortion upper bound while ensuring tightness through the corresponding lower bound. Extensive evaluations validate the proposed distortion approximation, the derived rate-distortion bounds, and the effectiveness of the proposed joint design. Particularly, simulations and real-world testbed experiments demonstrate the effectiveness of the proposed joint design in balancing inference quality, latency, and energy consumption in edge embodied AI systems.