Look Inward to Explore Outward: Learning Temperature Policy from LLM Internal States via Hierarchical RL
作者: Yixiao Zhou, Yang Li, Dongzhou Cheng, Hehe Fan, Yu Cheng
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-13
💡 一句话要点
提出基于分层强化学习的Introspective LLM,从LLM内部状态学习温度策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 温度策略 分层强化学习 数学推理 探索-利用 内部状态 可解释性
📋 核心要点
- 现有方法在训练LLM时,解码策略(如采样温度)通常是静态或启发式的,与任务奖励脱节。
- Introspective LLM通过分层强化学习,使LLM能够根据自身内部状态动态调整采样温度,实现更有效的探索。
- 实验表明,学习到的温度策略在数学推理任务上优于传统方法,并展现出与推理不确定性相关的可解释性。
📝 摘要(中文)
可验证奖励的强化学习(RLVR)通过采样轨迹训练大型语言模型(LLM),使得解码策略成为学习的核心组成部分,而不仅仅是推理时的选择。采样温度通过调节策略熵直接控制探索-利用的权衡,但现有方法依赖于静态值或与任务级奖励解耦的启发式调整。我们提出了Introspective LLM,一个分层强化学习框架,学习在生成过程中控制采样温度。在每个解码步骤中,模型根据其隐藏状态选择一个温度,并从生成的分布中采样下一个token。温度和token策略通过坐标上升方案从下游奖励中联合优化。在数学推理基准上的实验表明,学习到的温度策略优于固定和启发式基线,同时表现出与推理不确定性对齐的可解释的探索行为。
🔬 方法详解
问题定义:现有方法在利用强化学习训练LLM时,通常采用固定的或启发式的采样温度,无法根据LLM自身的推理状态动态调整探索-利用的平衡。这导致模型在推理过程中可能无法有效地探索潜在的更优解,尤其是在复杂的推理任务中。
核心思路:论文的核心思路是让LLM具备“内省”能力,即根据自身的内部状态(hidden state)来动态调整采样温度。通过强化学习,模型学习一个温度策略,该策略能够根据当前状态选择合适的温度,从而更好地平衡探索和利用。这种方法将温度控制问题转化为一个序列决策问题。
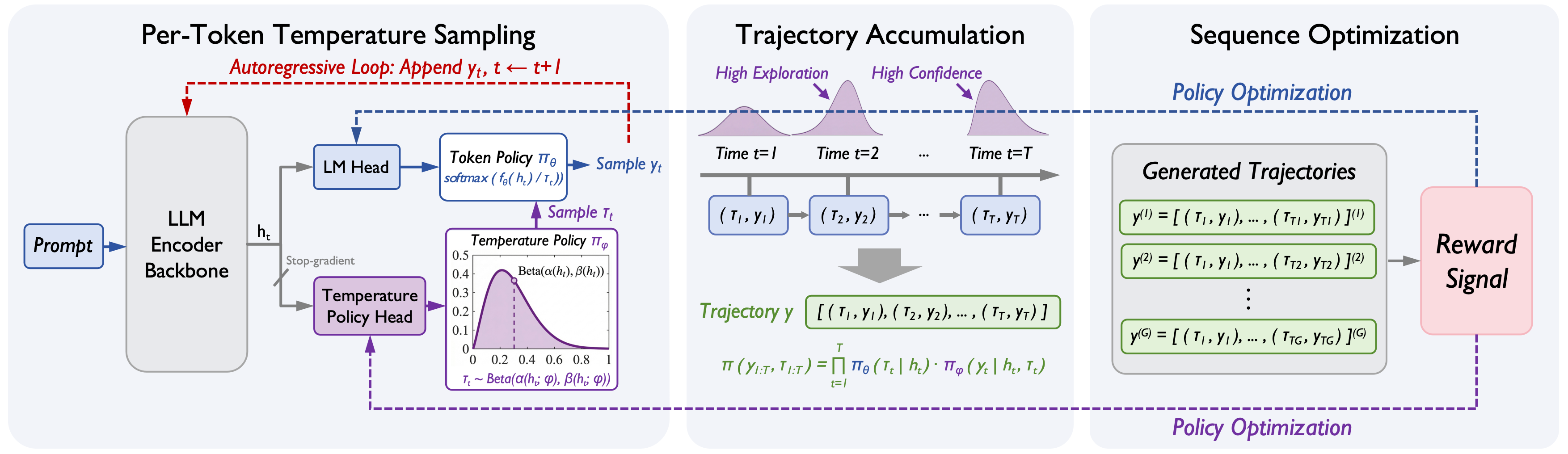
技术框架:Introspective LLM采用分层强化学习框架。该框架包含两个层级的策略:高层级的温度策略和低层级的token策略。在每个解码步骤,高层级的温度策略根据LLM的隐藏状态选择一个温度值。然后,低层级的token策略根据该温度值对token分布进行采样,生成下一个token。温度策略和token策略通过坐标上升方案联合优化,其中token策略的目标是最大化下游任务的奖励,而温度策略的目标是最大化token策略的性能。
关键创新:该论文的关键创新在于将LLM的采样温度控制问题建模为一个分层强化学习问题,并利用LLM自身的内部状态来动态调整温度。与传统的固定温度或启发式方法相比,这种方法能够更有效地探索潜在的更优解,并提高LLM在复杂推理任务上的性能。此外,该方法还具有可解释性,学习到的温度策略与LLM的推理不确定性相关。
关键设计:温度策略使用一个小型神经网络,输入为LLM的隐藏状态,输出为温度值。温度值被限制在一个合理的范围内。奖励函数来自下游任务的性能指标。坐标上升方案交替优化温度策略和token策略。在优化温度策略时,token策略被固定,反之亦然。实验中使用了常见的数学推理数据集,并与固定温度和启发式温度调整方法进行了比较。
🖼️ 关键图片
📊 实验亮点
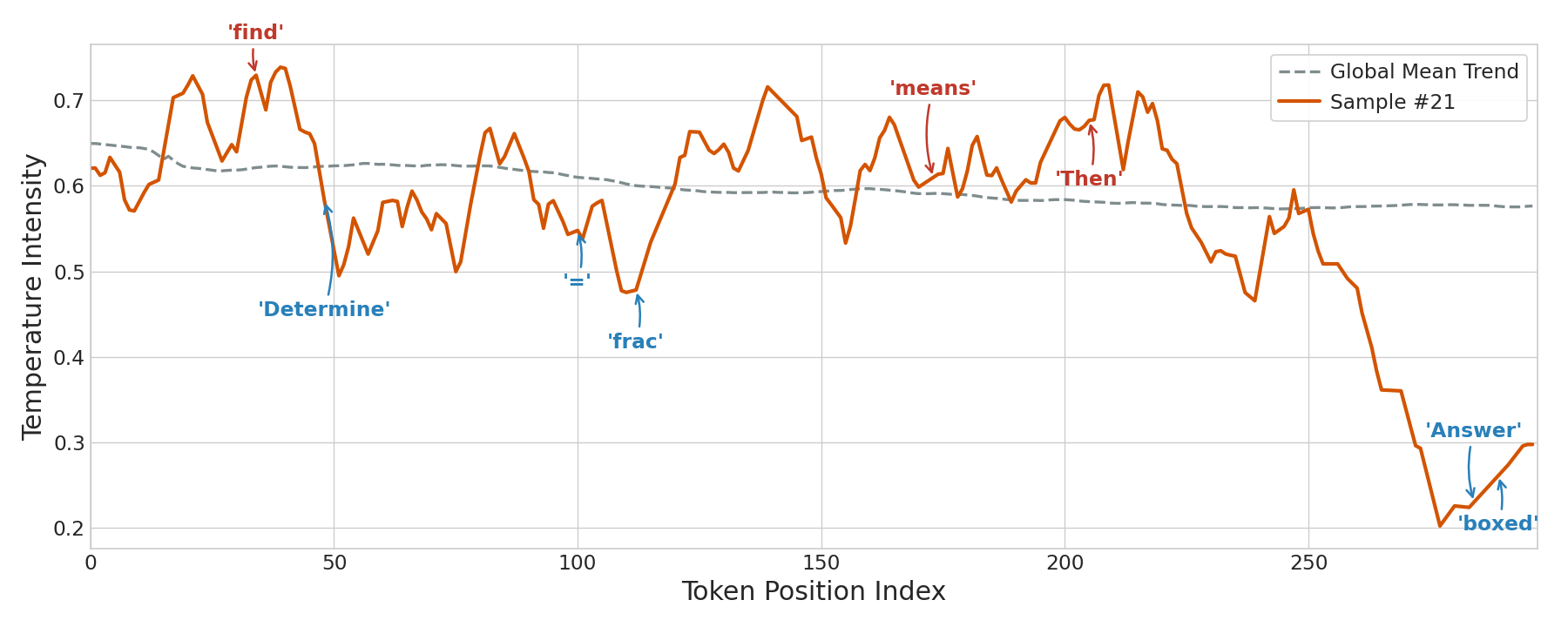
实验结果表明,Introspective LLM在数学推理基准上显著优于固定温度和启发式温度调整方法。具体来说,学习到的温度策略在多个数据集上取得了更高的准确率,并且展现出与推理不确定性相关的可解释性。例如,在模型对当前推理步骤不确定时,学习到的温度策略倾向于选择更高的温度,以鼓励更多的探索。
🎯 应用场景
该研究成果可应用于各种需要LLM进行复杂推理和决策的任务中,例如数学问题求解、代码生成、对话系统等。通过动态调整采样温度,可以提高LLM的探索能力和生成质量,使其能够更好地适应不同的任务需求。此外,该方法还可以用于提高LLM的可解释性,帮助人们理解LLM的推理过程。
📄 摘要(原文)
Reinforcement Learning from Verifiable Rewards (RLVR) trains large language models (LLMs) from sampled trajectories, making decoding strategy a core component of learning rather than a purely inference-time choice. Sampling temperature directly controls the exploration--exploitation trade-off by modulating policy entropy, yet existing methods rely on static values or heuristic adaptations that are decoupled from task-level rewards. We propose Introspective LLM, a hierarchical reinforcement learning framework that learns to control sampling temperature during generation. At each decoding step, the model selects a temperature based on its hidden state and samples the next token from the resulting distribution. Temperature and token policies are jointly optimized from downstream rewards using a coordinate ascent scheme. Experiments on mathematical reasoning benchmarks show that learned temperature policies outperform fixed and heuristic baselines, while exhibiting interpretable exploration behaviors aligned with reasoning uncertainty.