Amortized Reasoning Tree Search: Decoupling Proposal and Decision in Large Language Models
作者: Zesheng Hong, Jiadong Yu, Hui Pan
分类: cs.LG, cs.AI
发布日期: 2026-02-13
💡 一句话要点
提出Amortized Reasoning Tree Search (ARTS),解耦大语言模型中的提议与决策过程。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 强化学习 树搜索 解耦 Flow Matching 长尾问题 RLVR
📋 核心要点
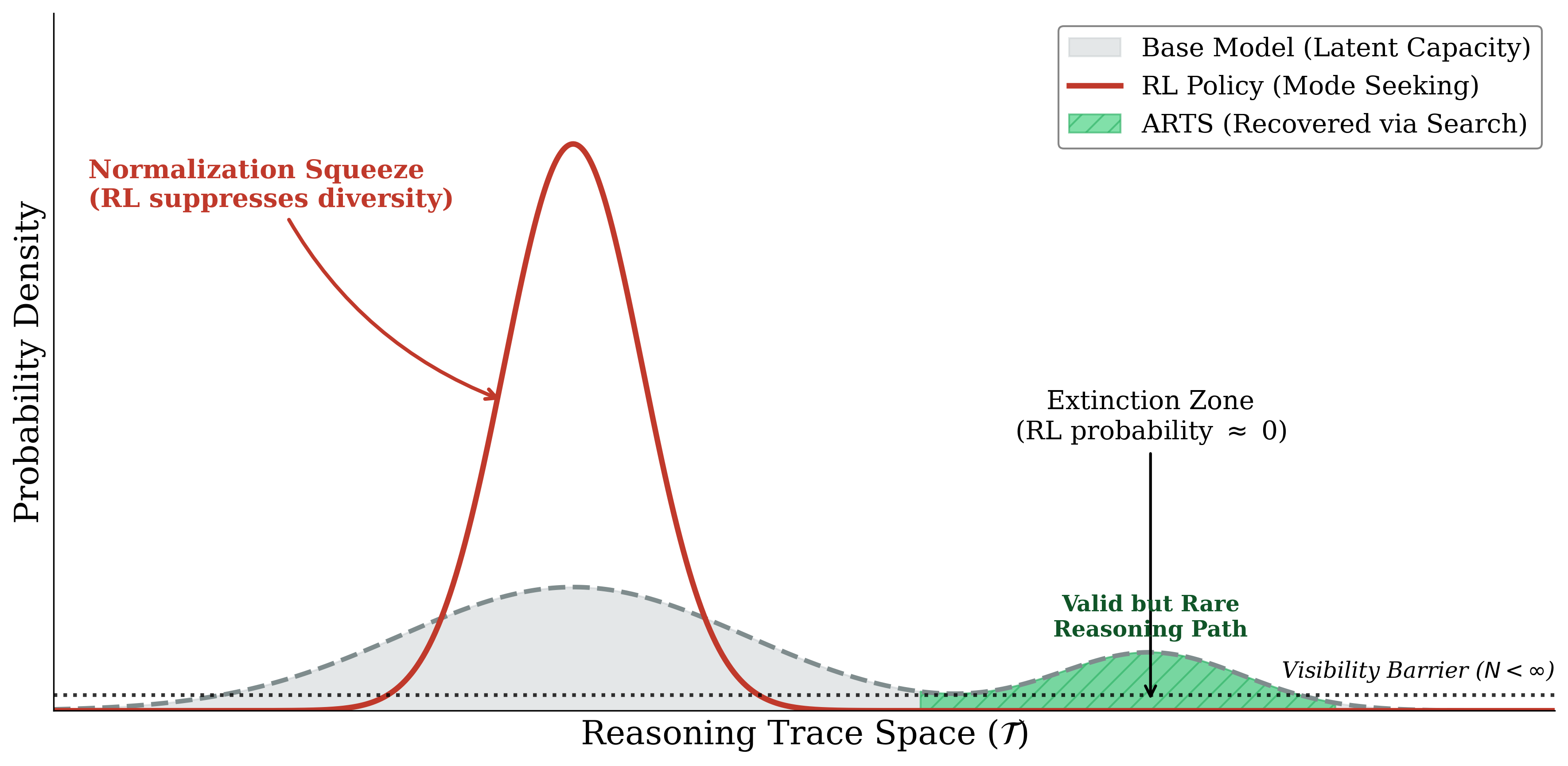
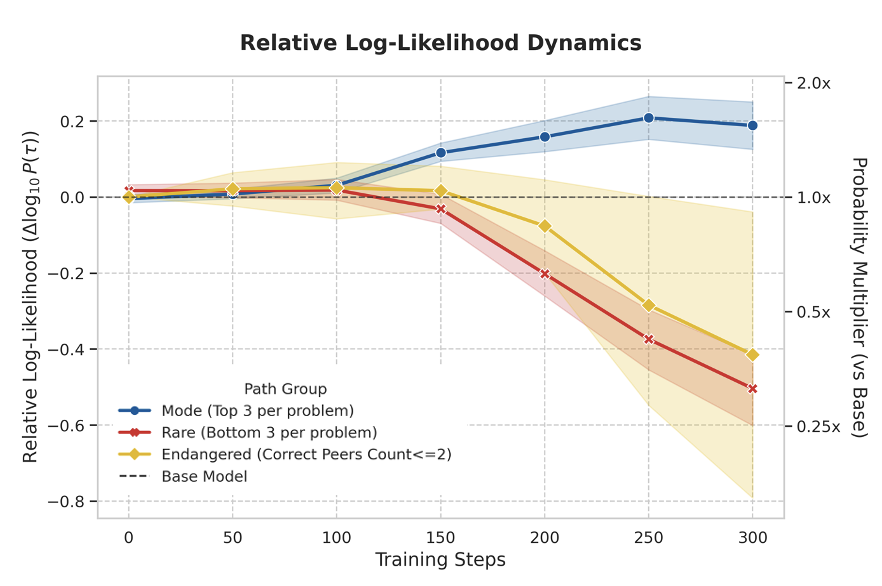
- 现有基于RLVR的方法在训练大语言模型推理能力时,会抑制模型中概率较低但正确的推理路径。
- ARTS通过解耦生成和验证过程,避免了对生成模型参数的直接修改,保留了模型的多样性。
- 在MATH-500数据集上,ARTS在不微调生成模型的情况下,性能与微调模型相当,并在长尾问题上表现出显著优势。
📝 摘要(中文)
强化学习与可验证奖励(RLVR)已成为赋予大型语言模型严谨推理能力的主流范式。尽管它在放大主导行为方面有效,但我们发现此对齐过程中的一个关键问题:系统性地抑制有效但罕见(在基础模型分布下低概率)的推理路径。我们从理论上将这种现象描述为“归一化挤压”,其中寻求模式的策略梯度与有限采样之间的相互作用充当高通似然滤波器,导致罕见正确轨迹的概率在统计上消失。为了抵消这种崩溃,同时不丢弃基础模型的潜在多样性,我们提出了Amortized Reasoning Tree Search (ARTS)。与通过参数更新强制内化的标准方法不同,ARTS通过解耦生成和验证来优先考虑审议。我们引入了Flow Matching目标,该目标重新利用验证器来估计概率流的守恒性,从而能够在传统的判别目标失败的稀疏、高熵搜索空间中进行稳健的导航。在MATH-500基准上的大量实验表明,ARTS实现了74.6%的性能(BoN@16),有效地匹配了完全微调的策略(74.7%),而无需修改生成骨干。至关重要的是,在耦合RL优化崩溃到0% pass@k的长尾子集上,ARTS独特地恢复了显著的性能,表明将验证与生成分离为解决复杂推理任务提供了一条更稳健的途径。
🔬 方法详解
问题定义:现有基于强化学习的推理方法,特别是RLVR,在训练大语言模型时,倾向于放大高概率的推理路径,而忽略那些概率较低但同样正确的推理路径。这种现象被称为“归一化挤压”,导致模型在处理罕见但有效的推理过程时表现不佳。现有方法的痛点在于,它们通过参数更新强制模型内化推理能力,从而牺牲了模型原有的多样性,尤其是在长尾问题上表现很差。
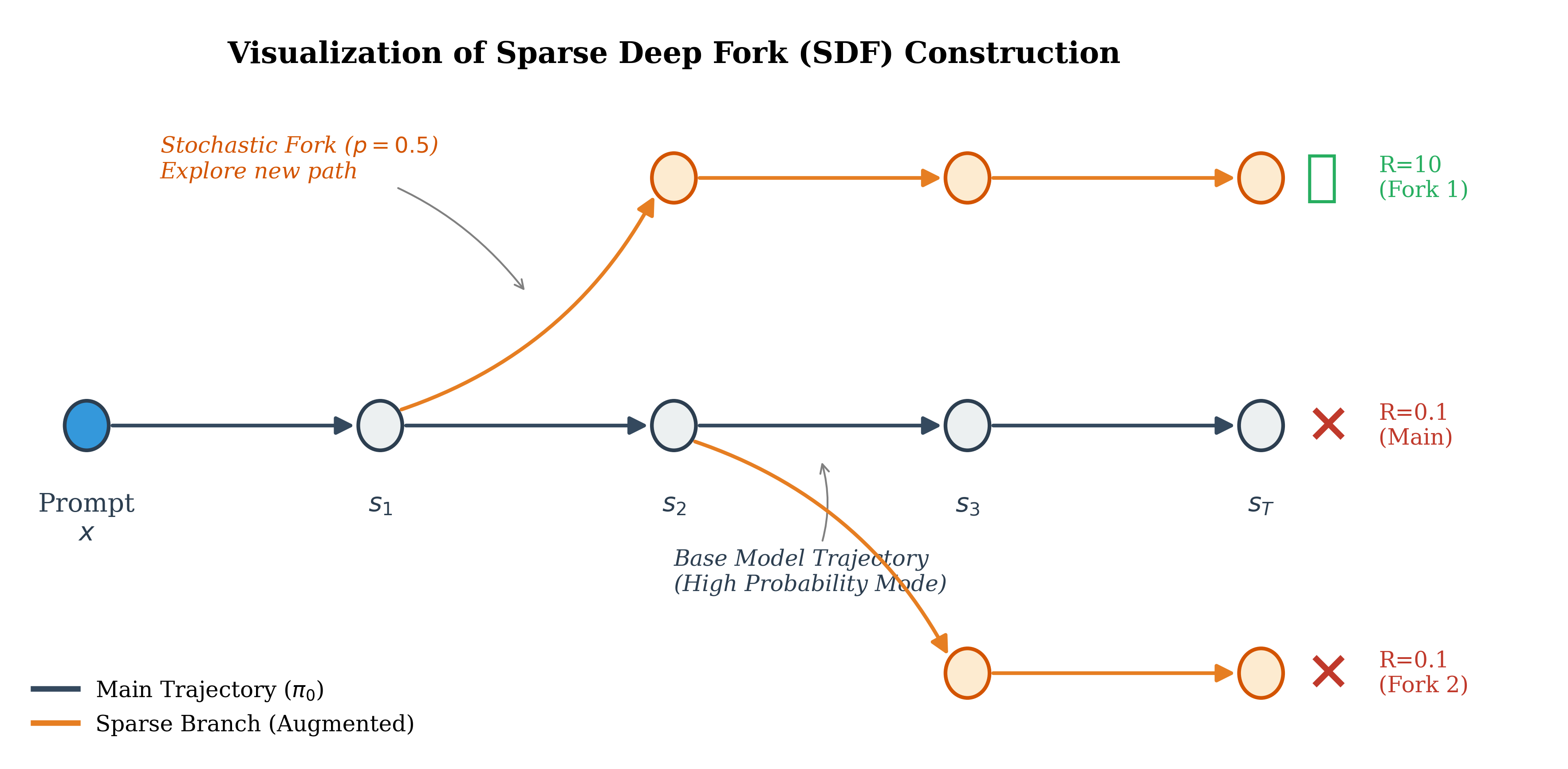
核心思路:ARTS的核心思路是将推理过程中的生成(proposal)和验证(decision)解耦。这意味着模型首先生成多个可能的推理路径,然后使用一个独立的验证器来评估这些路径的正确性。通过这种方式,模型可以探索更广泛的搜索空间,而不会受到生成模型自身概率分布的限制。这种解耦允许模型保留其原有的多样性,并更好地处理罕见但有效的推理路径。
技术框架:ARTS的整体框架包含两个主要模块:生成器(Generator)和验证器(Verifier)。生成器负责生成多个候选的推理路径。验证器则负责评估这些路径的正确性。ARTS使用Flow Matching目标来训练验证器,使其能够估计概率流的守恒性。整个流程可以概括为:1. 生成器采样多个推理路径;2. 验证器评估这些路径的质量;3. 使用Flow Matching目标更新验证器,使其能够更准确地评估路径的质量;4. 基于验证器的评估结果,选择最佳的推理路径。
关键创新:ARTS最重要的技术创新点在于解耦了生成和验证过程,并引入了Flow Matching目标。与现有方法相比,ARTS不直接修改生成模型的参数,而是通过训练一个独立的验证器来引导推理过程。Flow Matching目标使得验证器能够更好地处理稀疏、高熵的搜索空间,从而提高了模型在复杂推理任务中的性能。这种解耦和Flow Matching的结合,使得ARTS能够更好地保留模型的多样性,并有效地处理罕见但有效的推理路径。
关键设计:ARTS的关键设计包括:1. 使用预训练的大语言模型作为生成器,以利用其强大的生成能力;2. 使用Transformer架构作为验证器,以学习复杂的推理模式;3. 使用Flow Matching目标训练验证器,该目标旨在最小化验证器预测的概率流与真实概率流之间的差异;4. 在推理过程中,使用树搜索算法来探索不同的推理路径,并根据验证器的评估结果选择最佳路径。具体的参数设置和网络结构等细节在论文中有更详细的描述。
🖼️ 关键图片
📊 实验亮点
ARTS在MATH-500数据集上取得了显著的成果,在BoN@16指标上达到了74.6%的性能,与完全微调的策略(74.7%)相当,而无需修改生成骨干。更重要的是,在长尾子集上,传统的耦合RL优化方法性能崩溃至0% pass@k,而ARTS能够显著恢复性能,表明其在处理罕见但有效的推理路径方面具有独特的优势。
🎯 应用场景
ARTS具有广泛的应用前景,尤其是在需要复杂推理能力的领域,如数学问题求解、代码生成、逻辑推理等。该方法可以提高大语言模型在这些领域的性能,使其能够更好地解决实际问题。此外,ARTS的解耦设计也为未来的研究提供了新的思路,例如可以探索更有效的验证器训练方法,或者将ARTS应用于其他类型的生成模型。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has established itself as the dominant paradigm for instilling rigorous reasoning capabilities in Large Language Models. While effective at amplifying dominant behaviors, we identify a critical pathology in this alignment process: the systematic suppression of valid but rare (low-likelihood under the base model distribution) reasoning paths. We theoretically characterize this phenomenon as a "Normalization Squeeze," where the interplay between mode-seeking policy gradients and finite sampling acts as a high-pass likelihood filter, driving the probability of rare correct traces to statistical extinction. To counteract this collapse without discarding the base model's latent diversity, we propose Amortized Reasoning Tree Search (ARTS). Unlike standard approaches that force internalization via parameter updates, ARTS prioritizes deliberation by decoupling generation from verification. We introduce a Flow Matching objective that repurposes the verifier to estimate the conservation of probability flow, enabling robust navigation through sparse, high-entropy search spaces where traditional discriminative objectives fail. Extensive experiments on the MATH-500 benchmark demonstrate that ARTS achieves a performance of 74.6% (BoN@16), effectively matching fully fine-tuned policies (74.7%) without modifying the generative backbone. Crucially, on the long-tail subset where coupled RL optimization collapses to 0% pass@k, ARTS uniquely recovers significant performance, suggesting that disentangling verification from generation offers a more robust pathway for solving complex reasoning tasks.