SLA2: Sparse-Linear Attention with Learnable Routing and QAT
作者: Jintao Zhang, Haoxu Wang, Kai Jiang, Kaiwen Zheng, Youhe Jiang, Ion Stoica, Jianfei Chen, Jun Zhu, Joseph E. Gonzalez
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-02-13
💡 一句话要点
SLA2:结合可学习路由与量化感知训练的稀疏线性注意力,加速视频扩散模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 稀疏注意力 线性注意力 可学习路由 量化感知训练 视频扩散模型 模型加速 低比特量化
📋 核心要点
- 现有SLA方法依赖启发式规则进行稀疏和线性注意力分支的选择,可能导致次优的计算分配。
- SLA2通过引入可学习的路由器动态选择注意力计算分支,并采用可学习比率融合稀疏和线性注意力结果。
- SLA2结合稀疏注意力和低比特注意力,并通过量化感知微调降低量化误差,实验表明其在视频扩散模型上实现了显著加速。
📝 摘要(中文)
稀疏线性注意力(SLA)结合了稀疏注意力和线性注意力,以加速扩散模型,并在视频生成方面表现出强大的性能。然而,(i) SLA依赖于一种启发式分割方法,该方法基于注意力权值的大小将计算分配给稀疏或线性分支,这可能不是最优的。(ii) 在正式分析SLA中的注意力误差后,我们发现SLA与直接分解为稀疏和线性注意力之间存在不匹配。我们提出了SLA2,它引入了(I)一个可学习的路由器,动态选择每个注意力计算应该使用稀疏还是线性注意力,(II)一个更忠实和直接的稀疏-线性注意力公式,它使用一个可学习的比率来组合稀疏和线性注意力分支,以及(III)一个稀疏+低比特注意力设计,其中通过量化感知微调引入低比特注意力以减少量化误差。实验表明,在视频扩散模型上,SLA2可以实现97%的注意力稀疏性,并在保持生成质量的同时提供18.6倍的注意力加速。
🔬 方法详解
问题定义:现有稀疏线性注意力(SLA)方法在视频扩散模型中加速效果显著,但其基于注意力权重大小的启发式分支选择策略并非最优。此外,SLA的注意力误差分析表明,其实现方式与直接分解为稀疏和线性注意力存在偏差,导致性能瓶颈。
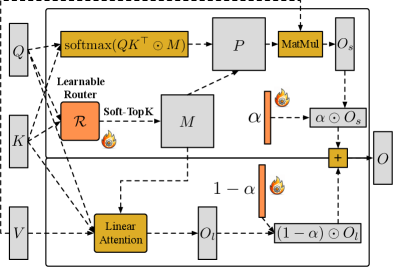
核心思路:SLA2的核心在于通过可学习的方式动态地决定每个注意力计算应该使用稀疏注意力还是线性注意力,并采用更直接的稀疏-线性注意力公式。这种方式旨在克服启发式规则的局限性,并更准确地逼近原始注意力机制。同时,引入低比特量化进一步提升计算效率。
技术框架:SLA2主要包含三个核心模块:可学习路由器、稀疏-线性注意力融合模块和量化感知微调模块。可学习路由器根据输入动态选择稀疏或线性注意力分支;融合模块使用可学习的比率组合两个分支的结果;量化感知微调模块则用于优化低比特注意力,减少量化带来的精度损失。
关键创新:SLA2的关键创新在于引入了可学习的路由机制,取代了原有的启发式规则。这种方式能够根据输入自适应地选择最佳的注意力计算方式,从而提高效率和精度。此外,更直接的稀疏-线性注意力公式也减少了与原始注意力机制的偏差。
关键设计:可学习路由器通常由一个小型神经网络实现,其输入是注意力权重或其他相关特征,输出是选择稀疏或线性注意力的概率。稀疏-线性注意力融合模块中的可学习比率通常通过一个sigmoid函数进行约束,以保证其取值在0到1之间。量化感知微调则需要在训练过程中模拟量化操作,并使用特定的损失函数来优化量化后的模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SLA2在视频扩散模型上实现了97%的注意力稀疏性,同时获得了18.6倍的注意力加速,并且保持了与原始模型相当的生成质量。这些结果显著优于现有的稀疏注意力方法,证明了SLA2的有效性和优越性。
🎯 应用场景
SLA2具有广泛的应用前景,尤其是在计算资源受限的场景下,例如移动设备上的视频生成、实时视频处理等。通过大幅度降低计算复杂度,SLA2使得在这些场景下部署高性能的视频扩散模型成为可能。此外,该方法也可以应用于其他需要加速注意力计算的任务中,例如自然语言处理、图像识别等。
📄 摘要(原文)
Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.