VI-CuRL: Stabilizing Verifier-Independent RL Reasoning via Confidence-Guided Variance Reduction
作者: Xin-Qiang Cai, Masashi Sugiyama
分类: cs.LG, cs.AI
发布日期: 2026-02-13
💡 一句话要点
VI-CuRL:通过置信度引导的方差缩减稳定无验证器强化学习推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 无验证器学习 课程学习 置信度引导 方差缩减 推理能力 策略优化
📋 核心要点
- 现有RLVR方法依赖外部验证器,限制了可扩展性,且梯度方差大导致训练不稳定。
- VI-CuRL利用模型自身置信度构建课程,优先选择高置信度样本,平衡偏差-方差。
- 实验结果表明,VI-CuRL在多个基准测试中,稳定性和性能均优于无验证器的基线方法。
📝 摘要(中文)
具有可验证奖励的强化学习(RLVR)已成为增强大型语言模型(LLM)推理的主流范例,但其对外部验证器的依赖限制了其可扩展性。最近的研究表明,RLVR主要通过激发潜在能力来发挥作用,这促使了无验证器算法的开发。然而,在这种设置中,诸如Group Relative Policy Optimization之类的标准方法面临着一个关键挑战:破坏性的梯度方差,这通常会导致训练崩溃。为了解决这个问题,我们引入了Verifier-Independent Curriculum Reinforcement Learning(VI-CuRL),该框架利用模型的内在置信度来构建独立于外部验证器的课程。通过优先考虑高置信度的样本,VI-CuRL有效地管理了偏差-方差权衡,特别是针对减少动作和问题方差。我们提供了严格的理论分析,证明我们的估计器保证了渐近无偏性。在经验上,VI-CuRL促进了稳定性,并且在有/无验证器的六个具有挑战性的基准测试中始终优于无验证器的基线。
🔬 方法详解
问题定义:论文旨在解决在无外部验证器的情况下,如何稳定强化学习训练,提升大型语言模型推理能力的问题。现有方法,如Group Relative Policy Optimization,在无验证器场景下,由于梯度方差过大,容易导致训练崩溃,无法有效利用模型的潜在能力。
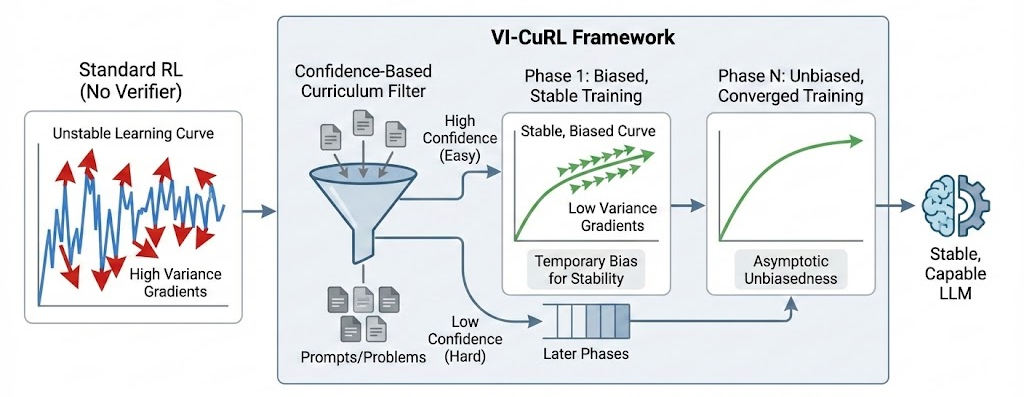
核心思路:论文的核心思路是利用模型自身的置信度来引导训练过程,构建一个与外部验证器无关的课程学习机制。通过优先选择模型置信度高的样本进行训练,可以有效地降低梯度方差,稳定训练过程,并提升模型的推理能力。
技术框架:VI-CuRL框架主要包含以下几个阶段:1) 模型生成样本;2) 模型评估样本置信度;3) 根据置信度构建课程,优先选择高置信度样本;4) 利用选择的样本进行策略优化。整体流程是一个循环迭代的过程,通过不断地选择和优化,逐步提升模型的推理能力。
关键创新:VI-CuRL的关键创新在于利用模型自身的置信度来构建课程,从而避免了对外部验证器的依赖。这种方法不仅提高了训练的效率,还解决了无验证器场景下梯度方差过大的问题,使得模型能够更稳定地学习和提升推理能力。
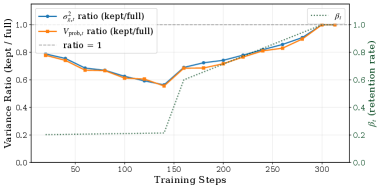
关键设计:VI-CuRL的关键设计包括:1) 置信度评估方法:论文可能采用了某种方式来量化模型对生成样本的置信度,例如softmax输出的最大概率值;2) 课程构建策略:论文设计了一种策略,根据置信度对样本进行排序,并优先选择高置信度的样本进行训练;3) 损失函数:论文可能使用了某种损失函数来优化策略,例如Policy Gradient方法,并结合置信度信息来调整梯度。
🖼️ 关键图片

📊 实验亮点
VI-CuRL在六个具有挑战性的基准测试中,无论有无验证器,都始终优于无验证器的基线方法。这表明VI-CuRL能够有效地稳定训练过程,并提升模型的推理能力。具体的性能提升幅度未知,但论文强调了其稳定性和一致性。
🎯 应用场景
VI-CuRL具有广泛的应用前景,可以应用于各种需要大型语言模型进行推理的场景,例如问答系统、文本摘要、机器翻译等。该方法尤其适用于缺乏外部验证器的场景,可以有效提升模型的推理能力和泛化性能。未来,该方法还可以与其他技术相结合,例如知识图谱、注意力机制等,进一步提升模型的性能。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a dominant paradigm for enhancing Large Language Models (LLMs) reasoning, yet its reliance on external verifiers limits its scalability. Recent findings suggest that RLVR primarily functions by eliciting latent capabilities, motivating the development of verifier-free algorithms. However, in such settings, standard methods like Group Relative Policy Optimization face a critical challenge: destructive gradient variance that often leads to training collapse. To address this issue, we introduceVerifier-Independent Curriculum Reinforcement Learning (VI-CuRL), a framework that leverages the model's intrinsic confidence to construct a curriculum independent from external verifiers. By prioritizing high-confidence samples, VI-CuRL effectively manages the bias-variance trade-off, specifically targeting the reduction of action and problem variance. We provide a rigorous theoretical analysis, proving that our estimator guarantees asymptotic unbiasedness. Empirically, VI-CuRL promotes stability and consistently outperforms verifier-independent baselines across six challenging benchmarks with/without verifiers.