SD-MoE: Spectral Decomposition for Effective Expert Specialization
作者: Ruijun Huang, Fang Dong, Xin Zhang, Hengjie Cao, Zhendong Huang, Anrui Chen, Jixian Zhou, Mengyi Chen, Yifeng Yang, Mingzhi Dong, Yujiang Wang, Jinlong Hou, Qin Lv, Robert P. Dick, Yuan Cheng, Fan Yang, Tun Lu, Chun Zhang, Li Shang
分类: cs.LG, cs.AI
发布日期: 2026-02-13
💡 一句话要点
SD-MoE:通过谱分解实现专家高效特化,提升MoE模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 专家特化 谱分解 参数解耦 梯度解耦 大型语言模型 条件计算 模型优化
📋 核心要点
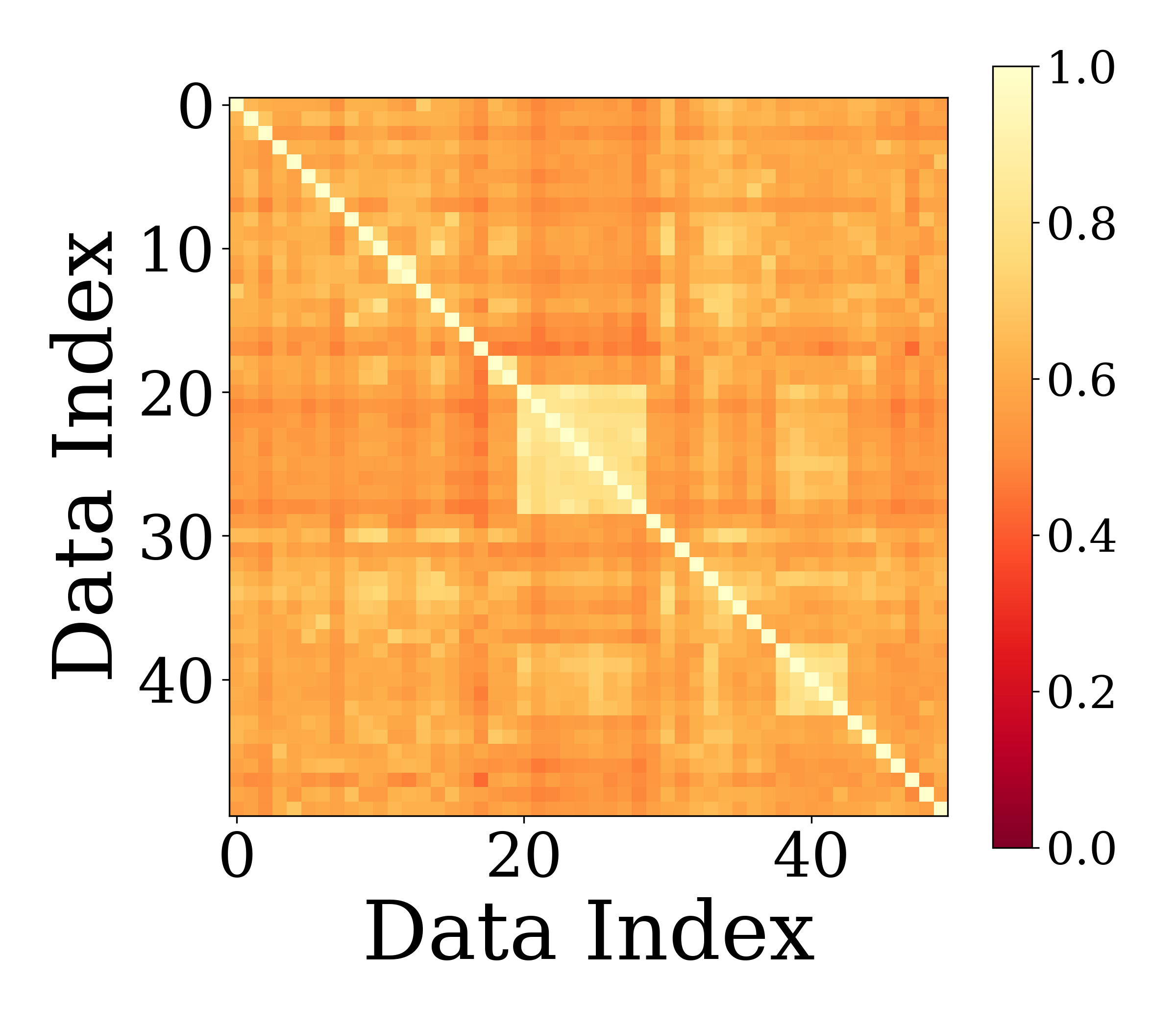
- MoE模型专家特化失败,专家功能相似或充当共享专家,限制模型容量和性能。
- 提出SD-MoE,通过谱分解解耦参数和梯度,促进专家特化。
- SD-MoE提升下游任务性能,计算开销小,易于集成到现有MoE架构。
📝 摘要(中文)
混合专家模型(MoE)通过条件计算诱导的专家特化来扩展大型语言模型。然而,实践中专家特化经常失败:一些专家在功能上变得相似,而另一些专家则充当事实上的共享专家,限制了有效容量和模型性能。本文从参数和梯度空间的谱角度进行分析,发现:(1)专家在其参数中共享高度重叠的主导谱分量;(2)由于人类语料库中普遍存在的低秩结构,主导梯度子空间在专家之间强烈对齐;(3)门控机制优先沿着这些主导方向路由输入,进一步限制了特化。为了解决这个问题,我们提出了谱解耦MoE(SD-MoE),它在谱空间中分解参数和梯度。SD-MoE提高了下游任务的性能,实现了有效的专家特化,只需极少的额外计算,并且可以无缝集成到包括Qwen和DeepSeek在内的各种现有MoE架构中。
🔬 方法详解
问题定义:MoE模型中的专家特化不足,导致专家功能冗余,部分专家退化为共享专家,无法有效利用模型容量。现有方法难以有效解耦专家,限制了模型性能的进一步提升。
核心思路:论文的核心思路是从谱的角度分析专家参数和梯度的分布,发现专家之间存在高度重叠的主导谱分量,以及梯度子空间的强烈对齐。通过在谱空间中解耦参数和梯度,可以有效促进专家特化,提高模型性能。这样设计的目的是为了减少专家之间的冗余,鼓励专家学习不同的特征,从而提升模型的表达能力。
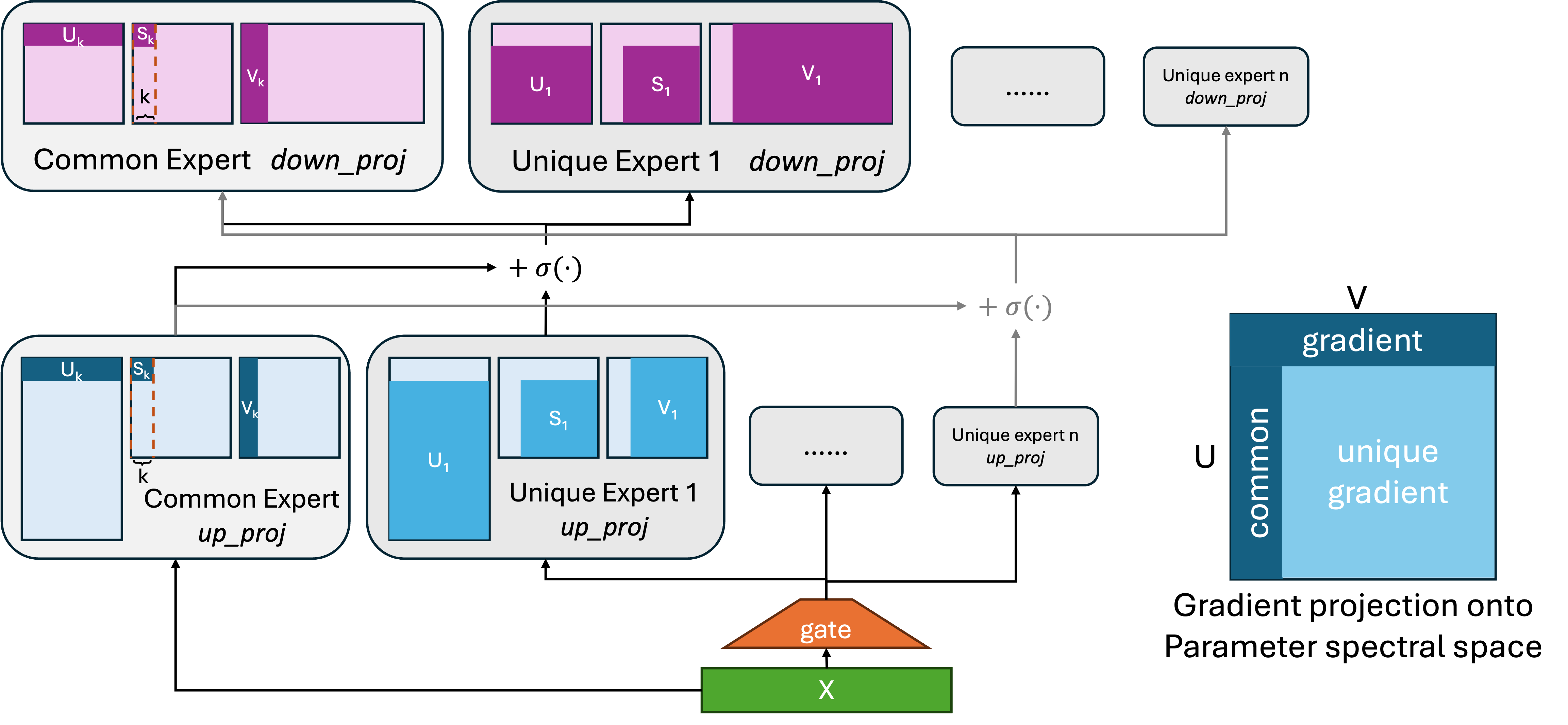
技术框架:SD-MoE的核心在于谱分解模块,该模块被集成到现有的MoE架构中。整体流程包括:1)对专家参数进行谱分解,得到谱分量;2)对梯度进行谱分解,得到梯度谱分量;3)在谱空间中对参数和梯度进行解耦操作;4)将解耦后的参数和梯度用于模型训练。该框架可以无缝集成到各种MoE架构中,例如Qwen和DeepSeek。
关键创新:SD-MoE的关键创新在于提出了谱解耦的概念,并将其应用于MoE模型的专家特化。与现有方法不同,SD-MoE不是直接在参数空间进行操作,而是在谱空间中解耦参数和梯度,从而更有效地促进专家特化。这种方法能够更好地利用模型的容量,提高模型的表达能力。
关键设计:SD-MoE的关键设计包括:1)选择合适的谱分解方法,例如奇异值分解(SVD);2)设计有效的解耦操作,例如正交化或稀疏化;3)调整谱分解的参数,例如保留的谱分量数量;4)设计合适的损失函数,以鼓励专家特化。具体参数设置和网络结构的选择取决于具体的MoE架构和下游任务。
🖼️ 关键图片
📊 实验亮点
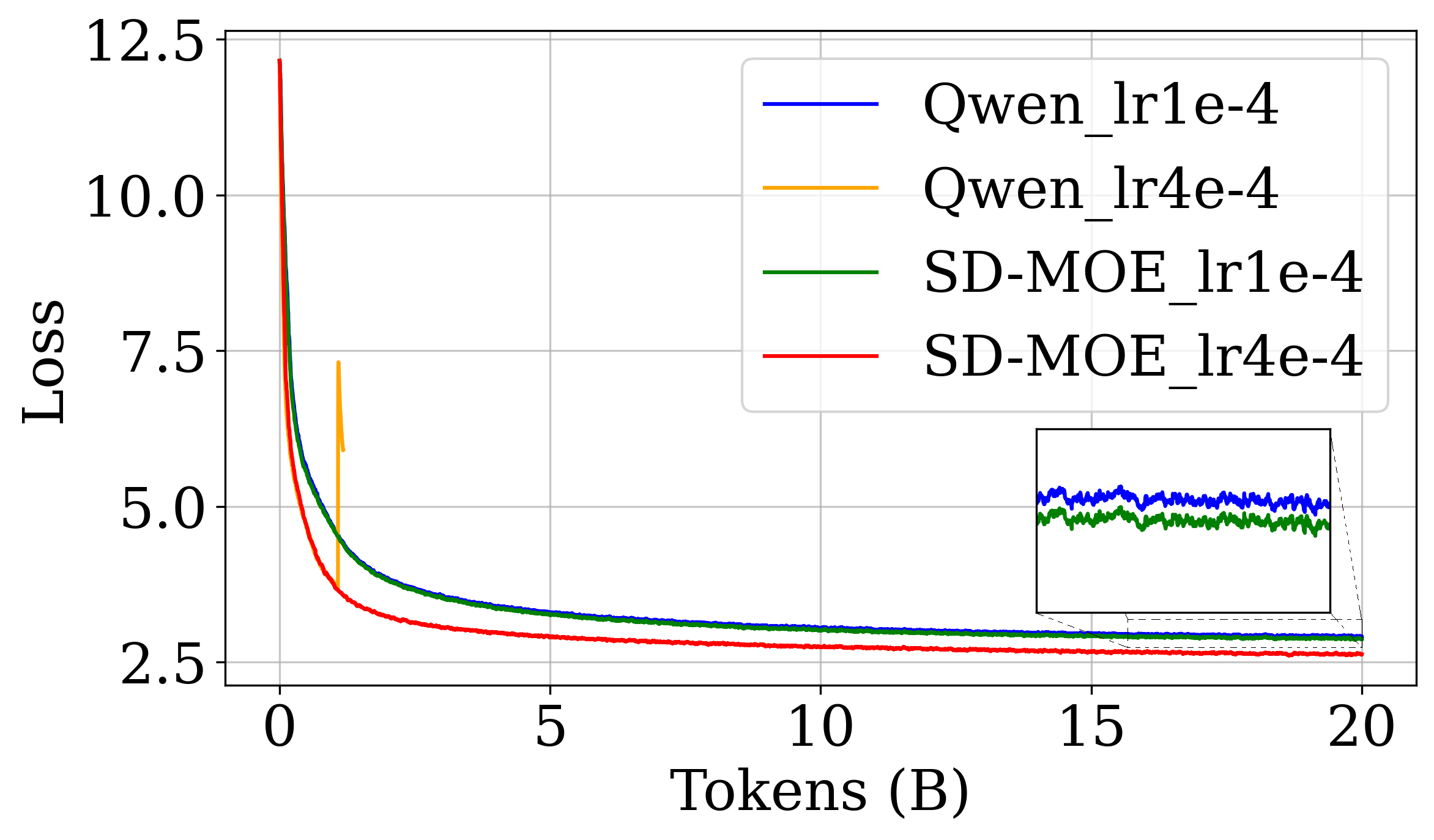
论文实验结果表明,SD-MoE在多个下游任务上取得了显著的性能提升。例如,在Qwen和DeepSeek等MoE模型上集成SD-MoE后,模型性能得到了明显改善,同时计算开销增加很少。具体性能数据和提升幅度在论文中有详细展示。
🎯 应用场景
SD-MoE可应用于各种需要大规模语言模型的场景,例如机器翻译、文本生成、对话系统等。通过提升MoE模型的性能,SD-MoE可以提高这些应用的质量和效率。该研究的潜在价值在于降低模型训练成本,提升模型泛化能力,并推动大型语言模型在实际应用中的普及。
📄 摘要(原文)
Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.