Constraint-Rectified Training for Efficient Chain-of-Thought
作者: Qinhang Wu, Sen Lin, Ming Zhang, Yingbin Liang, Ness B. Shroff
分类: cs.LG, cs.CL
发布日期: 2026-02-13
💡 一句话要点
提出约束校正训练(CRT),提升思维链(CoT)推理效率并控制推理长度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 高效推理 约束优化 语言模型 后训练
📋 核心要点
- 现有CoT方法推理链过长,导致推理成本高昂,且存在冗余步骤,影响效率。
- 提出约束校正训练(CRT)框架,通过约束优化,在保证准确率的前提下,最小化推理长度。
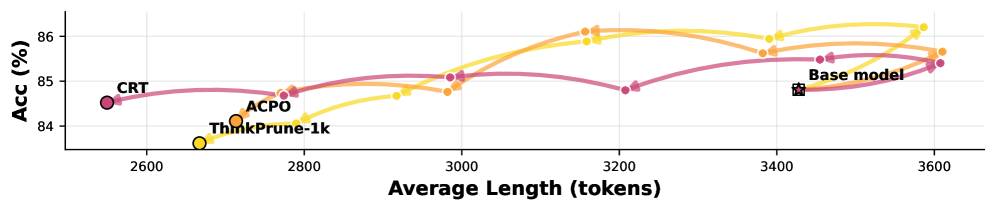
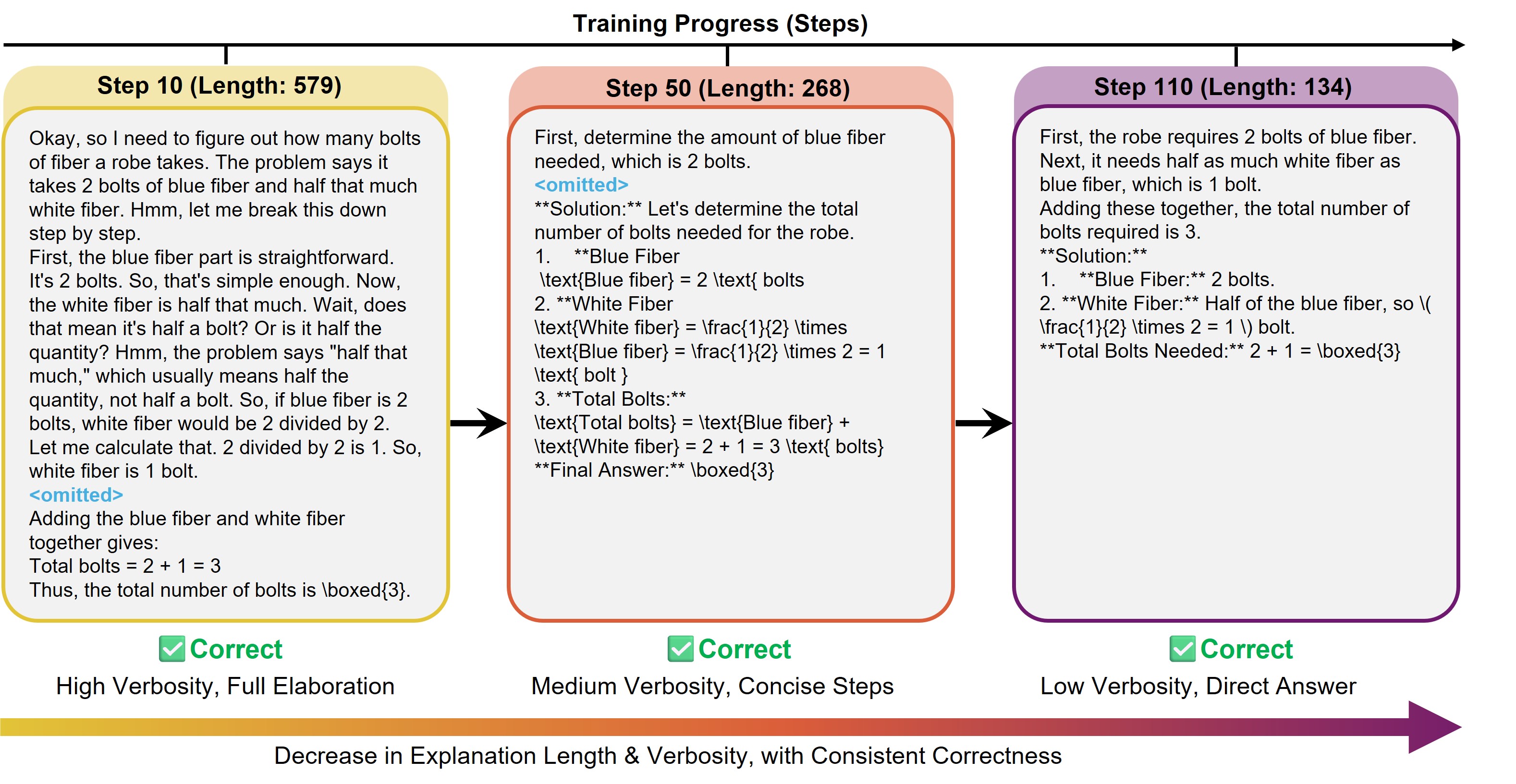
- 实验表明,CRT能有效减少token使用,保持答案质量,并降低语言冗余,实现更高效推理。
📝 摘要(中文)
思维链(CoT)显著增强了大型语言模型(LLM)的推理能力,特别是与基于强化学习(RL)的后训练方法结合使用时。更长的推理过程可以提高答案质量并解锁自我纠正等能力,但也会导致高昂的推理成本,并经常引入冗余步骤,即过度思考。最近的研究试图开发高效的推理策略,在推理长度和准确性之间取得平衡,无论是通过长度感知的奖励设计还是基于提示的校准。然而,这些基于启发式的方法可能会遭受严重的准确性下降,并且对超参数非常敏感。为了解决这些问题,我们引入了CRT(约束校正训练),这是一个基于参考保护约束优化的原则性后训练框架,为高效推理提供了一个更稳定和可解释的公式。CRT在最小化推理长度和仅在性能低于参考值时校正准确性之间交替进行,从而能够稳定有效地修剪冗余推理。我们进一步使用两阶段训练方案扩展了CRT,该方案首先发现最短的可靠推理模式,然后在学习到的长度预算下细化准确性,从而防止冗长CoT的重新出现。我们的综合评估表明,该框架始终如一地减少了token使用量,同时在稳健可靠的水平上保持了答案质量。进一步的分析表明,CRT不仅通过缩短响应来提高推理效率,还通过减少内部语言冗余来提高推理效率,从而产生了一种新的评估指标。此外,基于CRT的训练自然会产生一系列中间检查点,这些检查点跨越了一系列解释长度,同时保持了正确性,从而可以在不重新训练的情况下对推理详细程度进行细粒度控制。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中思维链(CoT)推理过程效率低下的问题。现有方法,如长度感知的奖励设计或基于提示的校准,在平衡推理长度和准确性方面存在不足,容易出现准确性下降,并且对超参数敏感。过度思考和冗余步骤导致推理成本增加,限制了CoT在实际应用中的可行性。
核心思路:论文的核心思路是通过约束优化来控制推理长度,同时保证推理的准确性。具体来说,引入参考保护约束优化,在推理性能低于参考值时,校正准确性,否则最小化推理长度。这种方法旨在稳定地修剪冗余推理步骤,从而提高推理效率。
技术框架:CRT框架包含两个主要阶段。第一阶段,发现最短的可靠推理模式。第二阶段,在学习到的长度预算下细化准确性,防止冗长CoT的重新出现。整个训练过程在最小化推理长度和校正准确性之间交替进行,通过参考值来指导优化过程。
关键创新:CRT的关键创新在于其基于参考保护约束优化的后训练框架。与启发式方法不同,CRT提供了一种更稳定和可解释的公式,用于高效推理。此外,两阶段训练方案能够有效地防止冗余推理的重新出现。
关键设计:CRT使用参考值作为约束条件,指导推理长度的优化。损失函数的设计需要在保证准确性的前提下,尽可能地减少推理长度。具体的参数设置和网络结构的选择取决于具体的LLM和任务,但CRT框架本身提供了一种通用的优化策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CRT能够显著减少token使用量,同时保持答案质量。与现有方法相比,CRT在推理效率和准确性之间取得了更好的平衡。此外,CRT还能够降低内部语言冗余,并生成一系列具有不同解释长度的中间检查点,从而实现对推理详细程度的细粒度控制。
🎯 应用场景
该研究成果可应用于各种需要高效推理的场景,例如问答系统、对话机器人和智能助手。通过控制推理长度,可以降低计算成本,提高响应速度,并提升用户体验。此外,该方法还可以用于训练更小、更高效的语言模型,使其能够在资源受限的环境中运行。
📄 摘要(原文)
Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), especially when combined with reinforcement learning (RL) based post-training methods. While longer reasoning traces can improve answer quality and unlock abilities such as self-correction, they also incur high inference costs and often introduce redundant steps, known as overthinking. Recent research seeks to develop efficient reasoning strategies that balance reasoning length and accuracy, either through length-aware reward design or prompt-based calibration. However, these heuristic-based approaches may suffer from severe accuracy drop and be very sensitive to hyperparameters. To address these problems, we introduce CRT (Constraint-Rectified Training), a principled post-training framework based on reference-guarded constrained optimization, yielding a more stable and interpretable formulation for efficient reasoning. CRT alternates between minimizing reasoning length and rectifying accuracy only when performance falls below the reference, enabling stable and effective pruning of redundant reasoning. We further extend CRT with a two-stage training scheme that first discovers the shortest reliable reasoning patterns and then refines accuracy under a learnt length budget, preventing the re-emergence of verbose CoT. Our comprehensive evaluation shows that this framework consistently reduces token usage while maintaining answer quality at a robust and reliable level. Further analysis reveals that CRT improves reasoning efficiency not only by shortening responses but also by reducing internal language redundancy, leading to a new evaluation metric. Moreover, CRT-based training naturally yields a sequence of intermediate checkpoints that span a spectrum of explanation lengths while preserving correctness, enabling fine-grained control over reasoning verbosity without retraining.