Multi-Agent Model-Based Reinforcement Learning with Joint State-Action Learned Embeddings
作者: Zhizun Wang, David Meger
分类: cs.LG, cs.MA
发布日期: 2026-02-13
备注: 22 pages
💡 一句话要点
提出基于联合状态-动作学习嵌入的多智能体模型强化学习框架,提升协作效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 模型强化学习 状态-动作嵌入 变分自编码器 协作策略 部分可观测环境 世界模型
📋 核心要点
- 现有方法在部分可观测和高动态多智能体环境中,难以学习到信息丰富的表征,导致训练效率低下。
- 论文提出一种基于模型的强化学习框架,通过联合状态-动作表征学习和想象roll-out,提升智能体的协作能力。
- 在多个多智能体基准测试中,该方法优于现有算法,验证了联合状态-动作学习嵌入在多智能体环境中的有效性。
📝 摘要(中文)
本文提出了一种新颖的基于模型的强化学习框架,用于解决多智能体在部分可观测和高度动态环境中进行协调的问题。该框架将联合状态-动作表征学习与想象roll-out相结合,以实现数据高效的训练。具体而言,设计了一个使用变分自编码器训练的世界模型,并利用状态-动作学习嵌入(SALE)对其进行增强。SALE被注入到想象模块(用于预测未来roll-out)和联合智能体网络(其个体动作值通过混合网络组合以估计联合动作值函数)中。通过将想象轨迹与基于SALE的动作值相结合,智能体能够更深入地理解其选择如何影响集体结果,从而在有限的真实环境交互下改进长期规划和优化。在包括星际争霸II微操、多智能体MuJoCo和基于等级的觅食挑战等多个基准测试中的实验结果表明,该方法相对于基线算法具有一致的优势,并突出了联合状态-动作学习嵌入在多智能体模型范式中的有效性。
🔬 方法详解
问题定义:在部分可观测和高度动态的多智能体环境中,如何让多个智能体高效地学习协作策略是一个挑战。现有方法通常难以学习到充分表达环境信息的表征,导致样本效率低,难以适应复杂环境。尤其是在真实交互受限的情况下,如何利用有限的数据进行有效的学习至关重要。
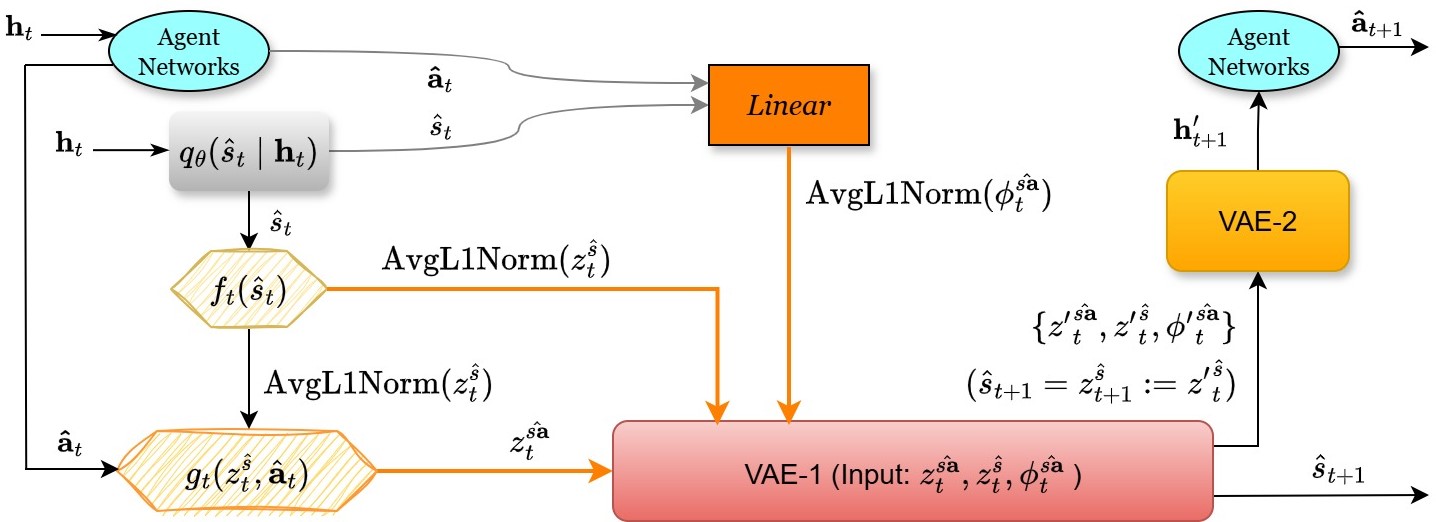
核心思路:论文的核心思路是将联合状态-动作表征学习与基于模型的强化学习相结合。通过学习一个世界模型来预测环境的未来状态,并利用状态-动作学习嵌入(SALE)来增强该模型。SALE能够捕捉智能体动作对环境状态的影响,从而帮助智能体更好地理解其行为与集体结果之间的关系。这种方法允许智能体在想象环境中进行roll-out,从而在有限的真实交互下进行更有效的学习。
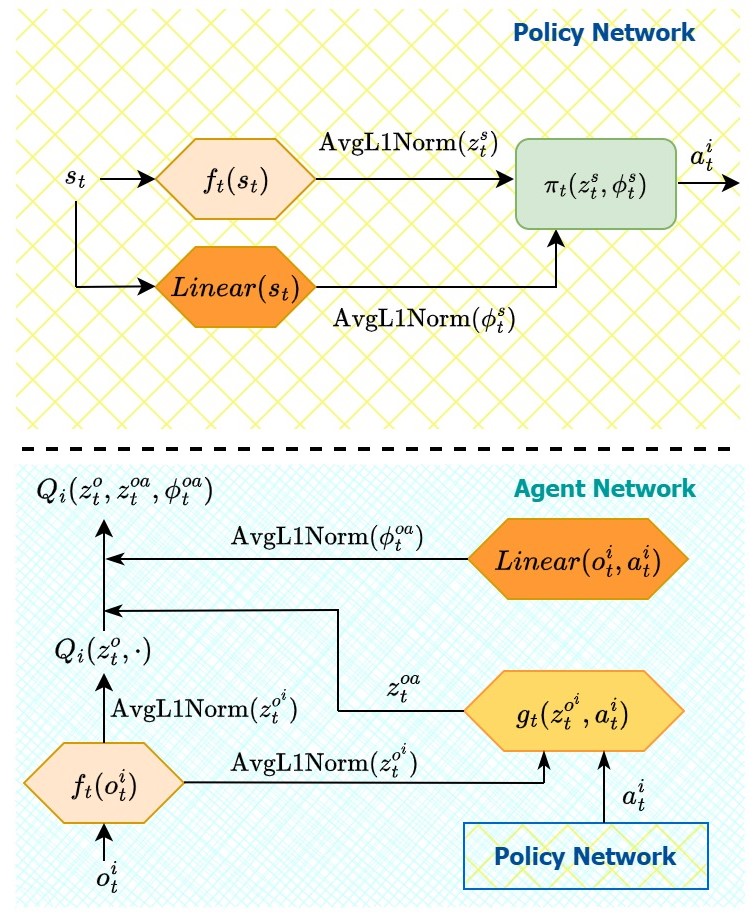
技术框架:该框架包含以下几个主要模块:1) 世界模型:使用变分自编码器(VAE)训练,用于预测环境的未来状态。2) 状态-动作学习嵌入(SALE):学习状态和动作的联合表征,捕捉动作对状态的影响。3) 想象模块:利用世界模型和SALE生成想象轨迹,模拟智能体在不同动作下的未来状态。4) 联合智能体网络:使用混合网络将个体动作值组合成联合动作值函数,评估联合动作的价值。整体流程是,智能体首先通过真实环境交互收集数据,然后利用这些数据训练世界模型和SALE。接着,智能体利用世界模型和SALE生成想象轨迹,并使用联合智能体网络评估这些轨迹的价值,从而更新策略。
关键创新:该论文的关键创新在于将状态-动作学习嵌入(SALE)引入到基于模型的多智能体强化学习框架中。与传统的基于模型的强化学习方法相比,SALE能够更有效地捕捉智能体动作对环境状态的影响,从而提高学习效率和性能。此外,该方法还通过将SALE注入到想象模块和联合智能体网络中,实现了想象轨迹与动作价值的有效结合。
关键设计:世界模型使用变分自编码器(VAE)进行训练,损失函数包括重构损失和KL散度损失。状态-动作学习嵌入(SALE)通过最小化预测状态与真实状态之间的差异进行训练。混合网络使用QMIX结构,将个体动作值组合成联合动作值函数。在训练过程中,使用TD-lambda算法更新联合智能体网络的参数。具体的参数设置(例如VAE的结构、SALE的维度、混合网络的层数等)需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
在星际争霸II微操、多智能体MuJoCo和基于等级的觅食挑战等多个基准测试中,该方法均优于现有算法。例如,在星际争霸II微操任务中,该方法相对于基线算法取得了显著的性能提升,证明了其在复杂多智能体环境中的有效性。具体提升幅度未知,但摘要中提到是“consistent gains”。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的场景,例如机器人协同操作、交通流量优化、资源分配、以及游戏AI等。通过学习高效的协作策略,可以显著提升系统的整体性能和效率,降低运营成本,并实现更智能化的决策。
📄 摘要(原文)
Learning to coordinate many agents in partially observable and highly dynamic environments requires both informative representations and data-efficient training. To address this challenge, we present a novel model-based multi-agent reinforcement learning framework that unifies joint state-action representation learning with imaginative roll-outs. We design a world model trained with variational auto-encoders and augment the model using the state-action learned embedding (SALE). SALE is injected into both the imagination module that forecasts plausible future roll-outs and the joint agent network whose individual action values are combined through a mixing network to estimate the joint action-value function. By coupling imagined trajectories with SALE-based action values, the agents acquire a richer understanding of how their choices influence collective outcomes, leading to improved long-term planning and optimization under limited real-environment interactions. Empirical studies on well-established multi-agent benchmarks, including StarCraft II Micro-Management, Multi-Agent MuJoCo, and Level-Based Foraging challenges, demonstrate consistent gains of our method over baseline algorithms and highlight the effectiveness of joint state-action learned embeddings within a multi-agent model-based paradigm.