On Robustness and Chain-of-Thought Consistency of RL-Finetuned VLMs
作者: Rosie Zhao, Anshul Shah, Xiaoyu Zhu, Xinke Deng, Zhongyu Jiang, Yang Yang, Joerg Liebelt, Arnab Mondal
分类: cs.LG
发布日期: 2026-02-13
💡 一句话要点
揭示RL微调视觉语言模型在推理一致性与鲁棒性上的脆弱性,并提出改进方向。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 强化学习微调 鲁棒性 推理一致性 忠实性 文本扰动 对抗性增强
📋 核心要点
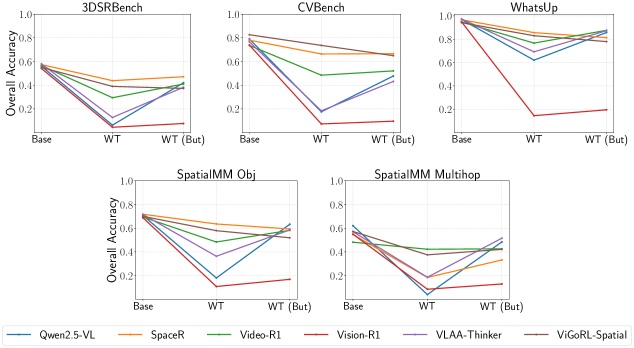
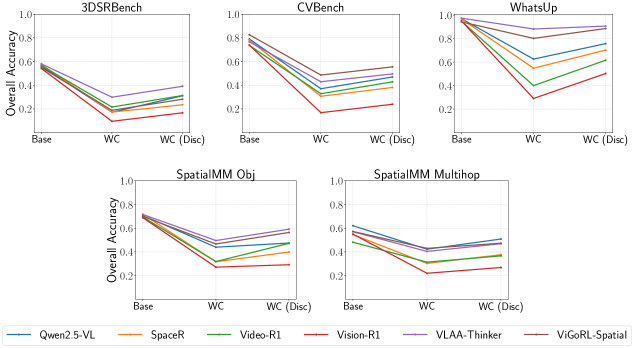
- 现有RL微调的VLM在视觉推理上存在弱视觉基础、幻觉和过度依赖文本线索等问题。
- 通过分析RL微调动态,揭示了准确性与推理忠实性之间的权衡,并提出了忠实性感知的奖励机制。
- 实验表明,对抗性增强虽能提升鲁棒性,但无法完全避免忠实性漂移,而忠实性奖励有助于恢复推理对齐。
📝 摘要(中文)
强化学习(RL)微调已成为增强大型语言模型(LLM)在推理密集型任务上的关键技术,并被扩展到视觉语言模型(VLM)。尽管RL微调的VLM在视觉推理基准测试中有所改进,但它们仍然容易受到弱视觉基础、幻觉和过度依赖文本线索的影响。研究表明,简单的、受控的文本扰动(误导性标题或不正确的思维链(CoT)轨迹)会导致鲁棒性和置信度大幅下降,并且在跨开源多模态推理模型中考虑CoT一致性时,这些影响更为明显。基于熵的指标进一步表明,这些扰动会重塑模型的不确定性和正确选项上的概率质量,从而暴露模型特定的错误校准趋势。为了更好地理解这些漏洞,进一步分析了RL微调的动态,并揭示了准确性-忠实性权衡:微调提高了基准准确性,但同时会削弱随附的CoT的可靠性及其对上下文变化的鲁棒性。虽然对抗性增强提高了鲁棒性,但它本身并不能阻止忠实性漂移。结合考虑忠实性的奖励可以恢复答案和推理之间的对齐,但当与增强结合使用时,训练可能会崩溃到捷径策略上,并且鲁棒性仍然难以捉摸。总之,这些发现突出了仅关注准确性的评估的局限性,并激发了训练和评估协议,这些协议共同强调正确性、鲁棒性和视觉基础推理的忠实性。
🔬 方法详解
问题定义:现有基于强化学习微调的视觉语言模型(VLM)在视觉推理任务中表现出一定的性能提升,但其鲁棒性和推理过程的可靠性仍然存在问题。具体来说,模型容易受到文本扰动的影响,例如误导性的标题或错误的思维链(CoT),导致性能显著下降,并且存在准确性与推理忠实性之间的矛盾。
核心思路:论文的核心思路是深入分析RL微调对VLM的影响,特别是对模型推理过程(CoT)的忠实性的影响。通过引入文本扰动来评估模型的鲁棒性,并使用熵等指标来衡量模型的不确定性。此外,论文提出了一个忠实性感知的奖励机制,旨在鼓励模型生成更可靠的推理过程,从而提高模型的整体性能。
技术框架:论文的研究框架主要包括以下几个部分:1)构建包含文本扰动的评估数据集,用于评估VLM的鲁棒性;2)使用基于熵的指标来分析模型在面对扰动时的不确定性变化;3)分析RL微调的动态,揭示准确性与推理忠实性之间的权衡;4)提出忠实性感知的奖励机制,并将其与对抗性增强相结合,以提高模型的鲁棒性和推理可靠性。
关键创新:论文最重要的技术创新点在于揭示了RL微调过程中准确性与推理忠实性之间的权衡关系。传统的RL微调往往只关注提高模型的准确性,而忽略了模型推理过程的可靠性。论文通过实验证明,单纯追求准确性可能会导致模型过度依赖文本线索,从而降低模型的鲁棒性和推理忠实性。
关键设计:论文的关键设计包括:1)设计了多种文本扰动策略,例如误导性标题和错误的CoT,用于评估模型的鲁棒性;2)使用交叉熵损失函数来衡量模型的预测准确性;3)引入忠实性奖励,鼓励模型生成与答案一致的推理过程;4)结合对抗性增强和忠实性奖励,以提高模型的鲁棒性和推理可靠性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,简单的文本扰动会导致VLM的鲁棒性和置信度显著下降。对抗性增强虽然可以提高鲁棒性,但无法完全避免忠实性漂移。引入忠实性感知的奖励机制可以恢复答案和推理之间的对齐,但与增强结合使用时,可能导致模型陷入捷径策略。这些发现强调了仅关注准确性的评估的局限性。
🎯 应用场景
该研究成果可应用于提升视觉语言模型在各种实际场景中的可靠性,例如自动驾驶、智能客服、医疗诊断等。通过提高模型对噪声数据的鲁棒性和推理过程的忠实性,可以减少模型出错的概率,从而提高系统的整体性能和安全性。此外,该研究还可以促进对齐人类价值观的AI系统的发展。
📄 摘要(原文)
Reinforcement learning (RL) fine-tuning has become a key technique for enhancing large language models (LLMs) on reasoning-intensive tasks, motivating its extension to vision language models (VLMs). While RL-tuned VLMs improve on visual reasoning benchmarks, they remain vulnerable to weak visual grounding, hallucinations, and over-reliance on textual cues. We show that simple, controlled textual perturbations--misleading captions or incorrect chain-of-thought (CoT) traces--cause substantial drops in robustness and confidence, and that these effects are more pronounced when CoT consistency is taken into account across open-source multimodal reasoning models. Entropy-based metrics further show that these perturbations reshape model uncertainty and probability mass on the correct option, exposing model-specific trends in miscalibration. To better understand these vulnerabilities, we further analyze RL fine-tuning dynamics and uncover an accuracy-faithfulness trade-off: fine-tuning raises benchmark accuracy, but can simultaneously erode the reliability of the accompanying CoT and its robustness to contextual shifts. Although adversarial augmentation improves robustness, it does not by itself prevent faithfulness drift. Incorporating a faithfulness-aware reward can restore alignment between answers and reasoning, but when paired with augmentation, training risks collapsing onto shortcut strategies and robustness remains elusive. Together, these findings highlight the limitations of accuracy-only evaluations and motivate training and assessment protocols that jointly emphasize correctness, robustness, and the faithfulness of visually grounded reasoning.