Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training
作者: Miaosen Zhang, Yishan Liu, Shuxia Lin, Xu Yang, Qi Dai, Chong Luo, Weihao Jiang, Peng Hou, Anxiang Zeng, Xin Geng, Baining Guo
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于分布判别理论的On-Policy SFT框架,提升LLM泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 监督微调 强化学习 大型语言模型 分布判别理论 同分布微调
📋 核心要点
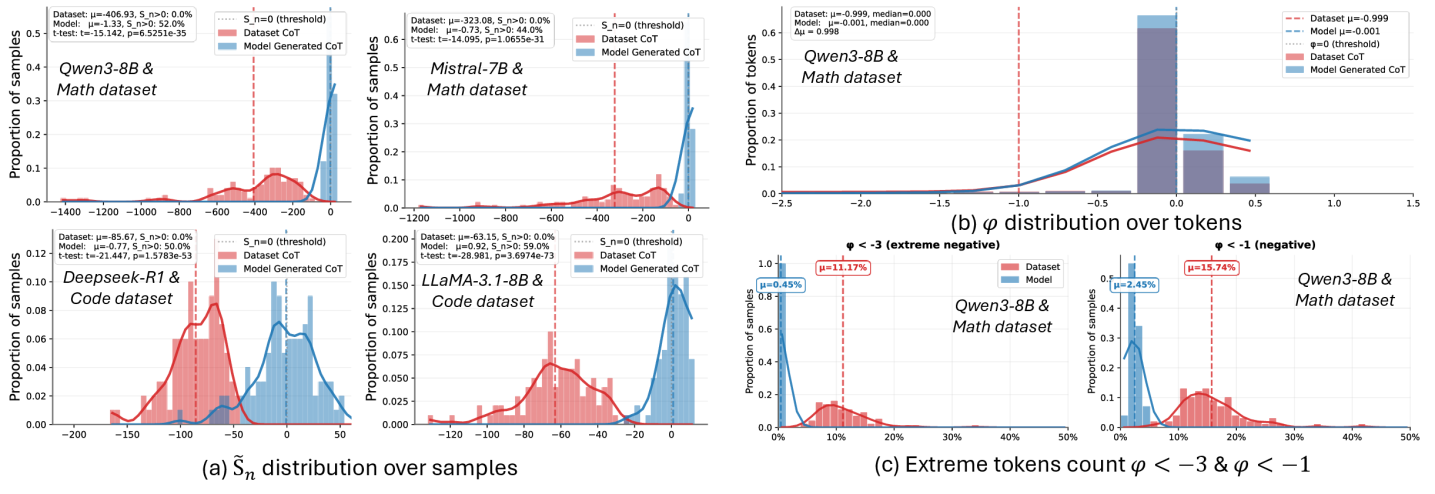
- 现有SFT方法泛化能力弱于RL,主要原因是SFT使用off-policy数据,与模型分布不一致。
- 提出分布判别理论(DDT),并基于此设计同分布微调(IDFT)和提示解码两种技术,实现On-Policy SFT。
- 实验表明,该框架在保持SFT效率的同时,泛化性能可与DPO和SimPO等离线RL算法媲美。
📝 摘要(中文)
监督微调(SFT)在计算上高效,但与强化学习(RL)相比,泛化能力通常较差。这种差距主要源于RL对on-policy数据的使用。本文提出了一个框架,通过实现On-Policy SFT来弥合这一差距。首先,提出了 extbf{ extit{分布判别理论(DDT)}},它解释并量化了数据与模型诱导分布之间的一致性。利用DDT,引入了两种互补技术:(i) extbf{ extit{同分布微调(IDFT)}},一种损失层面的方法,用于增强SFT的泛化能力;(ii) extbf{ extit{提示解码}},一种数据层面的技术,可以将训练语料库重新对齐到模型的分布。大量实验表明,该框架在泛化性能上与DPO和SimPO等著名的离线RL算法相当,同时保持了SFT流程的效率。因此,所提出的框架在RL不可行的领域提供了一种实用的替代方案。
🔬 方法详解
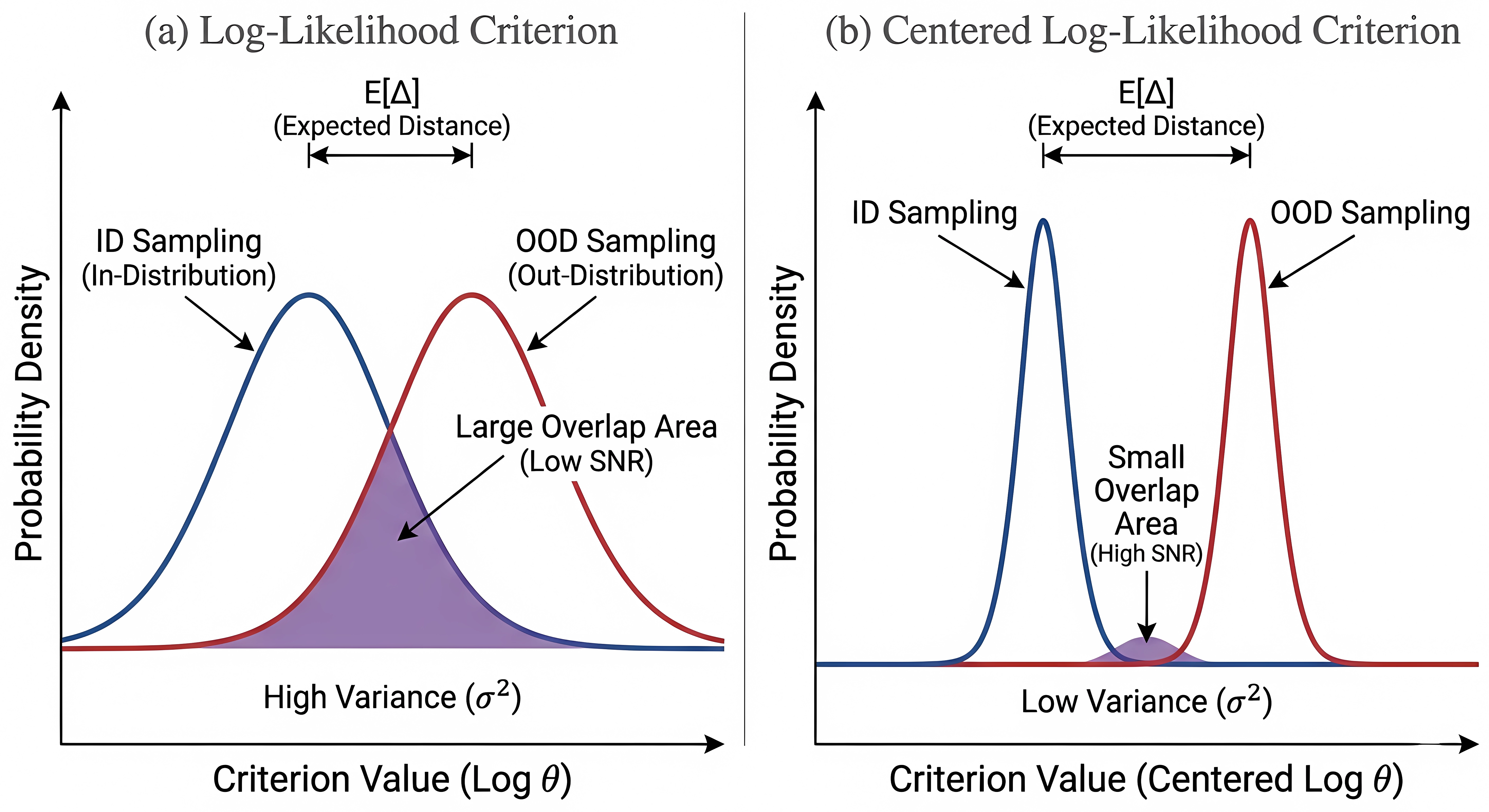
问题定义:现有监督微调(SFT)方法虽然计算效率高,但在大型语言模型(LLM)的训练中,其泛化能力通常不如强化学习(RL)方法。主要痛点在于SFT使用的数据分布与模型自身的分布存在偏差,即off-policy数据问题,导致模型在训练数据上表现良好,但在未见过的数据上表现不佳。
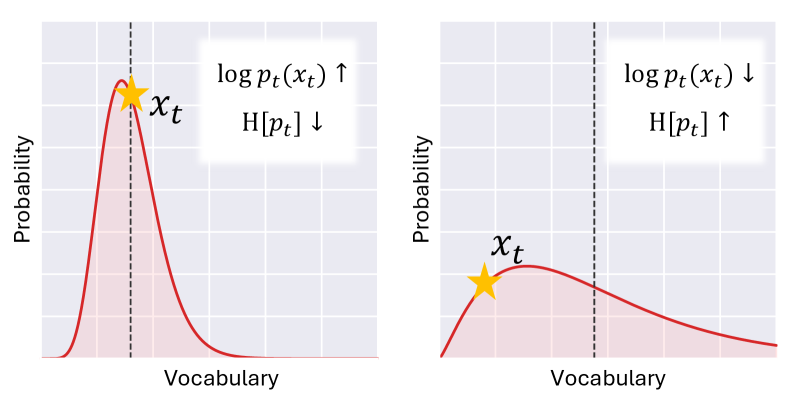
核心思路:论文的核心思路是通过使SFT过程尽可能地接近on-policy学习,从而提升模型的泛化能力。具体来说,就是缩小训练数据分布与模型自身分布之间的差距。论文提出了分布判别理论(DDT)来量化这种差距,并基于DDT设计了两种互补的技术:同分布微调(IDFT)和提示解码。
技术框架:整体框架包含两个主要组成部分:(1)同分布微调(IDFT):在损失函数层面,通过引入额外的正则化项,鼓励模型生成的分布与训练数据分布对齐,从而提高模型的泛化能力。(2)提示解码:在数据层面,通过修改训练数据,使其更符合模型自身的分布。具体来说,使用模型生成一些提示信息,然后将这些提示信息添加到原始训练数据中,从而使训练数据更接近模型自身的分布。
关键创新:最重要的技术创新点在于提出了分布判别理论(DDT),DDT提供了一种量化数据分布与模型分布之间差异的理论框架,为后续的同分布微调和提示解码提供了理论基础。与现有方法相比,DDT不仅关注数据的质量,更关注数据与模型之间的对齐程度。
关键设计:(1) 同分布微调(IDFT)的损失函数设计:在标准的SFT损失函数基础上,增加一个正则化项,该正则化项用于衡量模型生成分布与训练数据分布之间的差异。正则化项的具体形式可以根据DDT进行选择。(2) 提示解码的具体实现:使用模型生成一些高质量的提示信息,然后将这些提示信息添加到原始训练数据中。提示信息的生成方式和添加方式需要仔细设计,以确保提示信息能够有效地引导模型学习。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的On-Policy SFT框架在泛化性能上与DPO和SimPO等著名的离线RL算法相当,同时保持了SFT流程的效率。这意味着该框架可以在不牺牲计算效率的前提下,显著提升LLM的泛化能力。具体性能提升数据未知,但论文强调了与DPO和SimPO的竞争力。
🎯 应用场景
该研究成果可广泛应用于各种需要大型语言模型进行文本生成、对话系统、机器翻译等任务的场景。尤其是在数据获取成本高昂或难以进行强化学习的领域,On-Policy SFT框架提供了一种高效且实用的替代方案,可以显著提升模型的泛化能力和实际应用效果。未来,该方法有望推动LLM在更多实际场景中的应用。
📄 摘要(原文)
Supervised fine-tuning (SFT) is computationally efficient but often yields inferior generalization compared to reinforcement learning (RL). This gap is primarily driven by RL's use of on-policy data. We propose a framework to bridge this chasm by enabling On-Policy SFT. We first present \textbf{\textit{Distribution Discriminant Theory (DDT)}}, which explains and quantifies the alignment between data and the model-induced distribution. Leveraging DDT, we introduce two complementary techniques: (i) \textbf{\textit{In-Distribution Finetuning (IDFT)}}, a loss-level method to enhance generalization ability of SFT, and (ii) \textbf{\textit{Hinted Decoding}}, a data-level technique that can re-align the training corpus to the model's distribution. Extensive experiments demonstrate that our framework achieves generalization performance on par with prominent offline RL algorithms, including DPO and SimPO, while maintaining the efficiency of an SFT pipeline. The proposed framework thus offers a practical alternative in domains where RL is infeasible. We open-source the code here: https://github.com/zhangmiaosen2000/Towards-On-Policy-SFT