How Sampling Shapes LLM Alignment: From One-Shot Optima to Iterative Dynamics
作者: Yurong Chen, Yu He, Michael I. Jordan, Fan Yao
分类: cs.LG, cs.GT
发布日期: 2026-02-12
💡 一句话要点
研究采样策略对LLM对齐的影响,揭示迭代对齐中的稳定性和风险
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM对齐 偏好学习 采样策略 迭代动态 稳定性分析
📋 核心要点
- 现有LLM对齐方法依赖采样响应的成对比较,但采样和参考策略的选择缺乏理论理解,存在潜在风险。
- 论文通过理论分析,揭示了采样策略(如实例相关采样和on-policy采样)对LLM对齐效果和稳定性的影响。
- 实验验证了理论分析的有效性,表明特定的采样策略可能导致模型性能下降或不稳定,为实际应用提供了指导。
📝 摘要(中文)
本文研究了采样方法对大型语言模型(LLM)与人类偏好对齐的影响。通过Identity Preference Optimization框架,揭示了实例相关的采样能够增强排序保证,而有偏的on-policy采样可能导致过度集中。进一步分析了迭代对齐动态,即学习到的策略反馈到未来的采样和参考策略中。证明了这种动态在特定参数下可能表现出持续的振荡或熵坍塌,并确定了保证稳定性的机制。这些理论见解也适用于Direct Preference Optimization,表明所捕获的现象在更广泛的偏好对齐方法中是普遍存在的。最后,在真实偏好数据上的实验验证了这些发现。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法,如基于偏好学习的方法,依赖于从模型中采样候选响应,并根据人类偏好进行排序。然而,采样策略的选择(例如,如何选择用于比较的样本)以及参考策略(用于正则化学习过程)对最终对齐效果的影响缺乏深入的理论理解。现有的方法可能会因为不合理的采样策略导致模型性能下降,甚至出现训练不稳定等问题。
核心思路:本文的核心思路是通过理论分析,研究不同的采样策略如何影响基于偏好学习的LLM对齐过程。具体来说,论文关注两种采样策略:实例相关的采样(instance-dependent sampling)和on-policy采样。通过分析这两种采样策略对学习过程的影响,揭示了它们可能导致的潜在问题,并提出了相应的解决方案。论文还研究了迭代对齐动态,即学习到的策略反过来影响未来的采样和参考策略,并分析了这种动态可能导致的稳定性和风险。
技术框架:论文主要采用理论分析的方法,结合实验验证。首先,在Identity Preference Optimization (IPO) 框架下,对不同的采样策略进行理论分析,推导出相应的性能保证和稳定性条件。然后,将理论分析的结果推广到Direct Preference Optimization (DPO) 框架,表明所提出的结论具有更广泛的适用性。最后,通过在真实偏好数据集上进行实验,验证了理论分析的有效性。
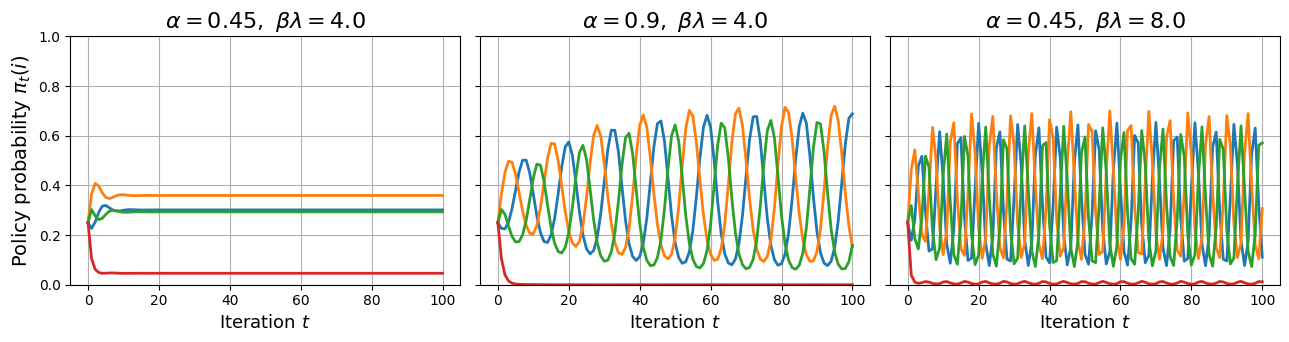
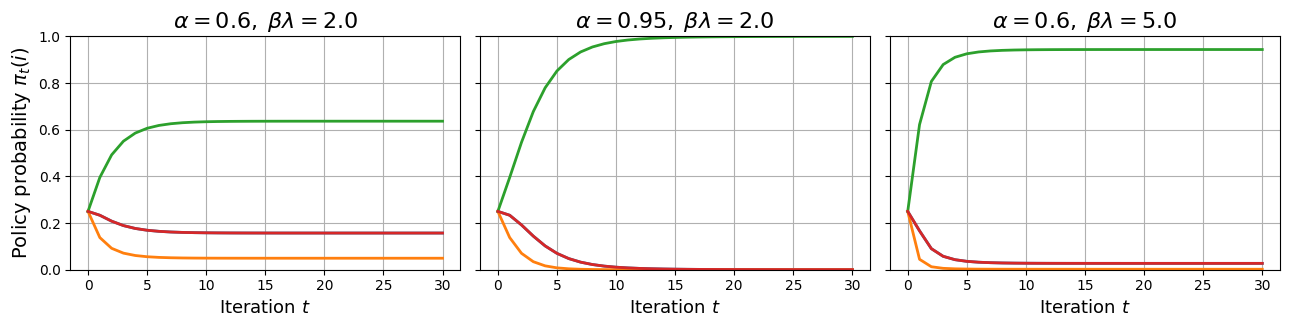
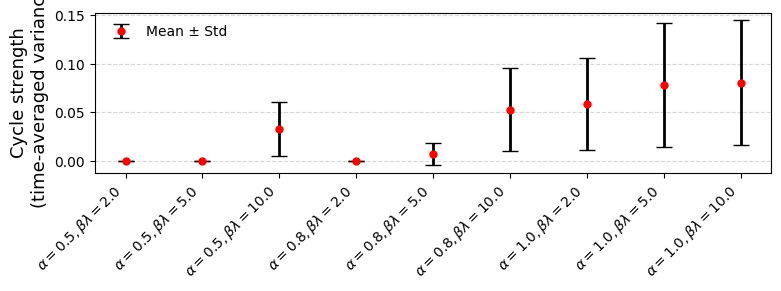
关键创新:论文的关键创新在于对采样策略在LLM对齐中的作用进行了深入的理论分析。具体来说,论文揭示了以下几个关键点:1) 实例相关的采样可以增强排序保证;2) 有偏的on-policy采样可能导致过度集中;3) 迭代对齐动态可能导致持续的振荡或熵坍塌。这些发现为LLM对齐方法的设计提供了新的视角和指导。
关键设计:论文的理论分析主要基于Identity Preference Optimization (IPO) 框架,该框架通过最小化一个损失函数来学习一个策略,该损失函数基于人类对不同响应的偏好。论文分析了损失函数中采样策略的选择对学习过程的影响,并推导出了相应的性能保证和稳定性条件。在实验部分,论文使用了真实的人类偏好数据集,并比较了不同采样策略下的模型性能。论文还研究了不同的正则化参数对模型稳定性的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不合理的采样策略会导致模型性能下降,甚至出现训练不稳定的情况。例如,有偏的on-policy采样可能导致模型过度集中于某些特定的响应,从而降低模型的泛化能力。通过采用实例相关的采样策略,可以提高模型的排序准确率,并增强模型的鲁棒性。此外,实验还验证了理论分析中关于迭代对齐动态的结论,表明合适的参数选择可以保证模型的稳定性。
🎯 应用场景
该研究成果可应用于提升大型语言模型与人类价值观和偏好对齐的可靠性和稳定性。通过选择合适的采样策略,可以避免模型过度集中或出现不稳定的行为,从而提高LLM在对话系统、内容生成等领域的应用效果。此外,该研究也为未来LLM对齐方法的设计提供了理论指导。
📄 摘要(原文)
Standard methods for aligning large language models with human preferences learn from pairwise comparisons among sampled candidate responses and regularize toward a reference policy. Despite their effectiveness, the effects of sampling and reference choices are poorly understood theoretically. We investigate these effects through Identity Preference Optimization, a widely used preference alignment framework, and show that proper instance-dependent sampling can yield stronger ranking guarantees, while skewed on-policy sampling can induce excessive concentration under structured preferences. We then analyze iterative alignment dynamics in which the learned policy feeds back into future sampling and reference policies, reflecting a common practice of model-generated preference data. We prove that these dynamics can exhibit persistent oscillations or entropy collapse for certain parameter choices, and characterize regimes that guarantee stability. Our theoretical insights extend to Direct Preference Optimization, indicating the phenomena we captured are common to a broader class of preference-alignment methods. Experiments on real-world preference data validate our findings.