SafeNeuron: Neuron-Level Safety Alignment for Large Language Models
作者: Zhaoxin Wang, Jiaming Liang, Fengbin Zhu, Weixiang Zhao, Junfeng Fang, Jiayi Ji, Handing Wang, Tat-Seng Chua
分类: cs.LG
发布日期: 2026-02-12
💡 一句话要点
SafeNeuron:提出神经元级别的安全对齐方法,提升大语言模型对抗神经元剪枝攻击的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全对齐 神经元剪枝 鲁棒性 对抗攻击
📋 核心要点
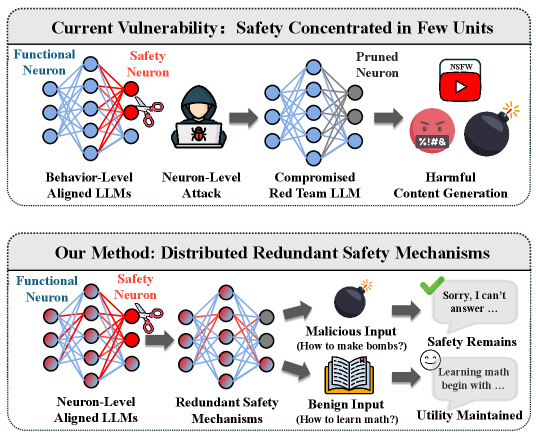
- 现有大语言模型的安全对齐依赖于少量参数,容易受到神经元级别攻击,导致模型生成有害内容。
- SafeNeuron通过识别并冻结安全相关神经元,迫使模型构建冗余安全表示,从而提高模型鲁棒性。
- 实验证明SafeNeuron能有效抵抗神经元剪枝攻击,降低模型被滥用风险,并保持模型通用能力。
📝 摘要(中文)
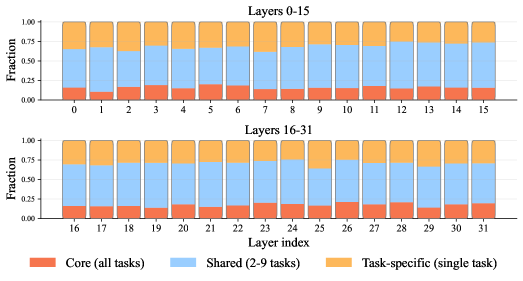
大型语言模型(LLMs)和多模态LLMs在发布前通常会进行安全对齐,以防止生成有害内容。然而,最近的研究表明,安全行为集中在一小部分参数中,这使得对齐变得脆弱,并且容易通过神经元级别的攻击绕过。此外,大多数现有的对齐方法都在行为层面进行操作,对模型的内部安全机制的控制有限。本文提出了SafeNeuron,一个神经元级别的安全对齐框架,通过在网络中重新分配安全表示来提高鲁棒性。SafeNeuron首先识别与安全相关的神经元,然后在偏好优化期间冻结这些神经元,以防止模型依赖稀疏的安全路径,并迫使模型构建冗余的安全表示。在模型和模态上的大量实验表明,SafeNeuron显著提高了对抗神经元剪枝攻击的鲁棒性,降低了开源模型被重新用作红队生成器的风险,并保留了一般能力。此外,我们的分层分析表明,安全行为受稳定和共享的内部表示控制。总而言之,SafeNeuron为模型对齐提供了一个可解释且鲁棒的视角。
🔬 方法详解
问题定义:现有的大语言模型安全对齐方法主要在行为层面进行,缺乏对模型内部安全机制的精细控制。这些方法容易受到神经元级别的攻击,攻击者可以通过剪枝或修改少量神经元来绕过安全机制,导致模型生成有害内容。因此,如何提升大语言模型对抗神经元级别攻击的鲁棒性是一个关键问题。
核心思路:SafeNeuron的核心思路是通过在神经元级别上重新分配安全相关的知识表示,从而提高模型的鲁棒性。具体来说,SafeNeuron避免模型将安全知识集中在少数神经元上,而是迫使模型在整个网络中构建冗余的安全表示。这样,即使某些神经元受到攻击,模型仍然能够保持其安全性能。
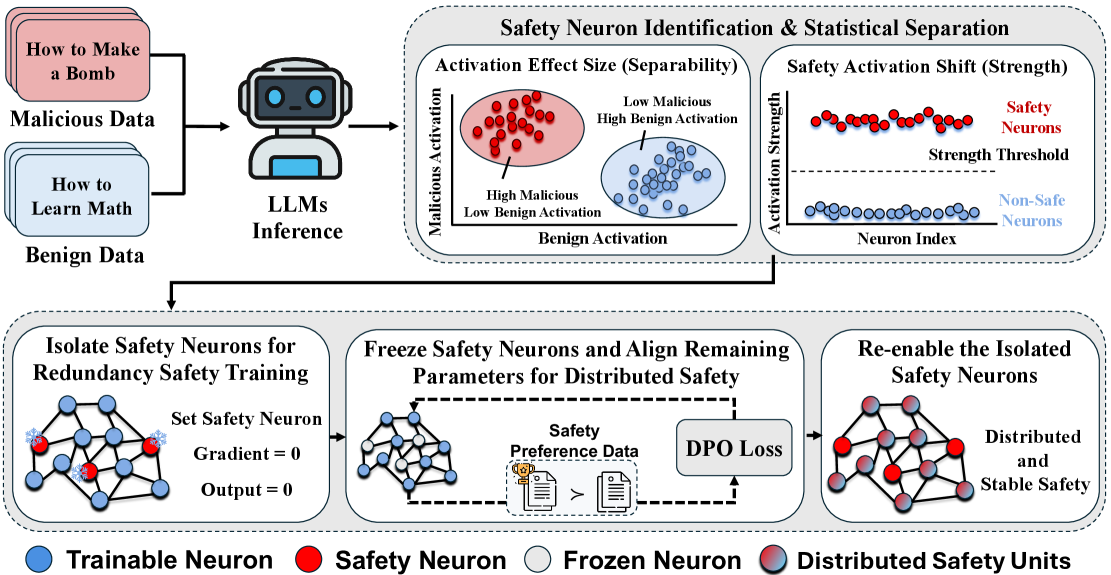
技术框架:SafeNeuron框架主要包含两个阶段:1) 安全神经元识别:使用某种方法(论文中未明确说明具体方法,属于未知细节)识别网络中与安全相关的神经元。2) 偏好优化与神经元冻结:在偏好优化阶段,冻结已识别的安全神经元,阻止模型继续依赖这些神经元,并迫使模型学习新的、冗余的安全表示。
关键创新:SafeNeuron的关键创新在于其神经元级别的安全对齐方法。与传统的行为层面安全对齐方法不同,SafeNeuron直接干预模型的内部表示,通过冻结安全神经元来强制模型学习更鲁棒的安全表示。这种方法能够有效抵抗神经元剪枝等攻击,提高模型的安全性。
关键设计:论文中未详细说明安全神经元识别的具体方法,以及偏好优化和神经元冻结的具体实现细节(例如,冻结神经元的具体方式、偏好优化的损失函数等)。这些属于未知细节。但是,整体思路是通过冻结特定神经元,改变模型的训练方式,从而影响模型内部的安全知识表示。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SafeNeuron能够显著提高模型对抗神经元剪枝攻击的鲁棒性。与未采用SafeNeuron的模型相比,采用SafeNeuron的模型在神经元剪枝攻击下的性能下降更小,表明SafeNeuron能够有效保护模型的安全性能。此外,实验还表明SafeNeuron能够降低开源模型被重新用作红队生成器的风险。
🎯 应用场景
SafeNeuron技术可应用于提升大语言模型和多模态大模型的安全性,降低模型被恶意利用的风险。该方法能够提高模型在对抗性环境下的鲁棒性,保障模型在实际应用中的安全可靠。此外,该研究为模型安全对齐提供了一个新的视角,有助于开发更安全、更可信的人工智能系统。
📄 摘要(原文)
Large language models (LLMs) and multimodal LLMs are typically safety-aligned before release to prevent harmful content generation. However, recent studies show that safety behaviors are concentrated in a small subset of parameters, making alignment brittle and easily bypassed through neuron-level attacks. Moreover, most existing alignment methods operate at the behavioral level, offering limited control over the model's internal safety mechanisms. In this work, we propose SafeNeuron, a neuron-level safety alignment framework that improves robustness by redistributing safety representations across the network. SafeNeuron first identifies safety-related neurons, then freezes these neurons during preference optimization to prevent reliance on sparse safety pathways and force the model to construct redundant safety representations. Extensive experiments across models and modalities demonstrate that SafeNeuron significantly improves robustness against neuron pruning attacks, reduces the risk of open-source models being repurposed as red-team generators, and preserves general capabilities. Furthermore, our layer-wise analysis reveals that safety behaviors are governed by stable and shared internal representations. Overall, SafeNeuron provides an interpretable and robust perspective for model alignment.