It's TIME: Towards the Next Generation of Time Series Forecasting Benchmarks
作者: Zhongzheng Qiao, Sheng Pan, Anni Wang, Viktoriya Zhukova, Yong Liu, Xudong Jiang, Qingsong Wen, Mingsheng Long, Ming Jin, Chenghao Liu
分类: cs.LG
发布日期: 2026-02-12
备注: The source code will be released on GitHub shortly
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
TIME:面向下一代时间序列预测基准,解决现有基准的数据、任务和评估局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 基准测试 零样本学习 数据质量 任务制定
📋 核心要点
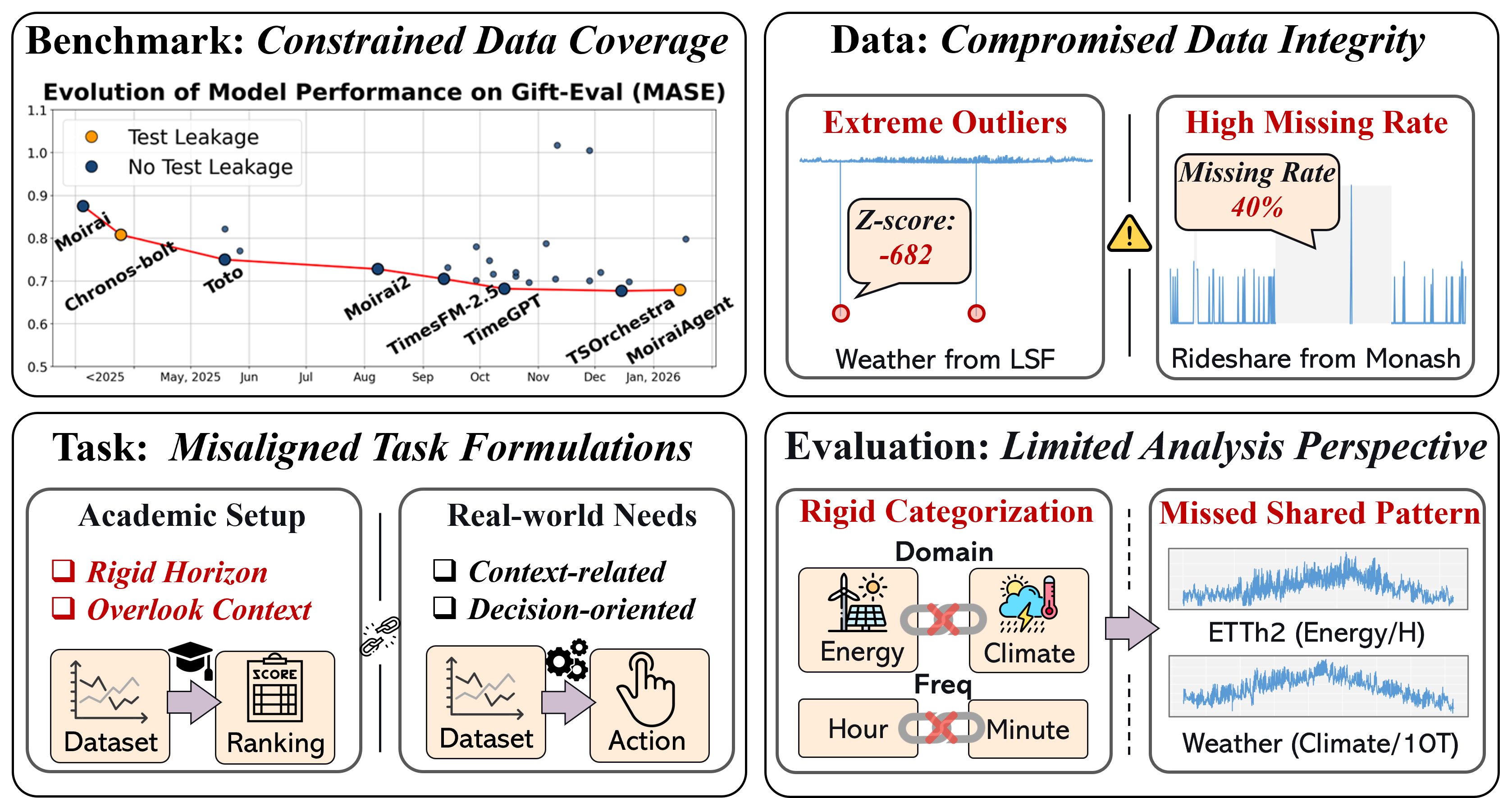
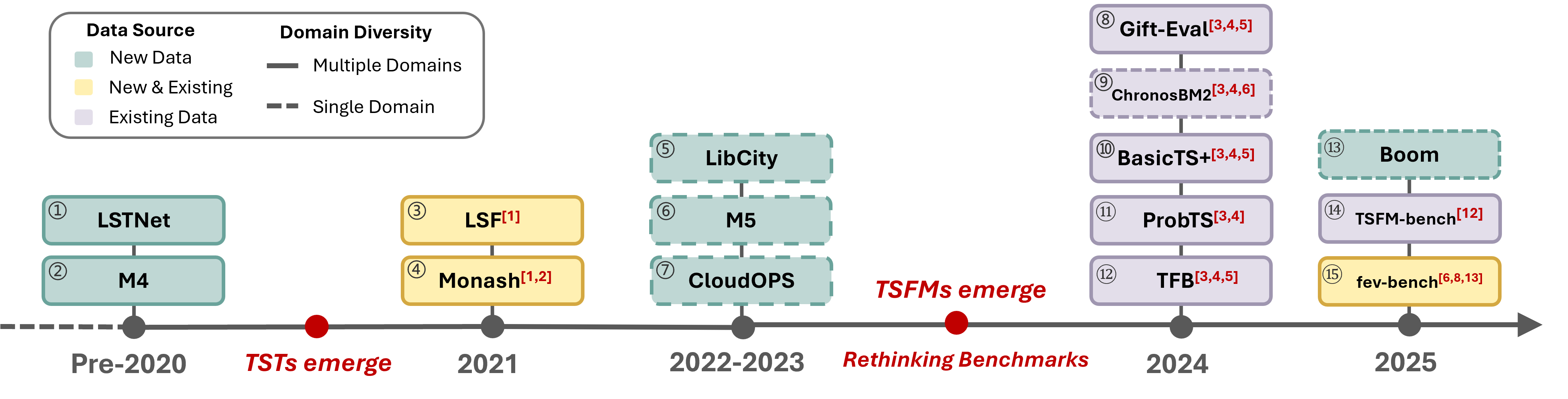
- 现有时间序列预测基准存在数据陈旧、质量不高、任务设置脱离实际以及评估方式单一等问题。
- TIME基准通过构建全新的数据集、严格的数据质量控制流程以及贴合实际应用的任务设置来解决上述问题。
- TIME基准引入了模式级别的评估视角,并构建了多粒度的排行榜,以便更全面地评估和分析模型性能。
📝 摘要(中文)
时间序列基础模型(TSFMs)正在革新预测领域,从特定数据集建模转向可泛化的任务评估。然而,现有基准在四个维度上存在局限性:受限的数据组成(主要依赖重复使用的遗留数据源)、受损的数据完整性(缺乏严格的质量保证)、错位的任务制定(脱离现实世界背景)以及僵化的分析视角(掩盖了可泛化的见解)。为了弥合这些差距,我们推出了TIME,这是一个下一代以任务为中心的基准,包含50个全新的数据集和98个预测任务,专为严格的零样本TSFM评估而设计,避免数据泄露。通过整合大型语言模型和人类专业知识,我们建立了一个严格的“人在环路”基准构建流程,以确保高数据完整性,并通过将预测配置与实际操作要求和变量可预测性对齐来重新定义任务制定。此外,我们提出了一种新颖的模式级评估视角,超越了基于静态元标签的传统数据集级评估。通过利用结构化时间序列特征来表征内在的时间属性,这种方法提供了对跨不同模式的模型能力的通用见解。我们评估了12个具有代表性的TSFM,并建立了一个多粒度排行榜,以促进深入分析和可视化检查。排行榜可在https://huggingface.co/spaces/Real-TSF/TIME-leaderboard上找到。
🔬 方法详解
问题定义:现有时间序列预测基准的数据集通常是重复使用的旧数据,缺乏新鲜度和多样性。数据质量控制不足,存在数据泄露的风险。任务设置与实际应用场景脱节,无法有效评估模型在真实世界中的性能。评估方法过于依赖静态元标签,无法深入了解模型在不同时间序列模式下的表现。
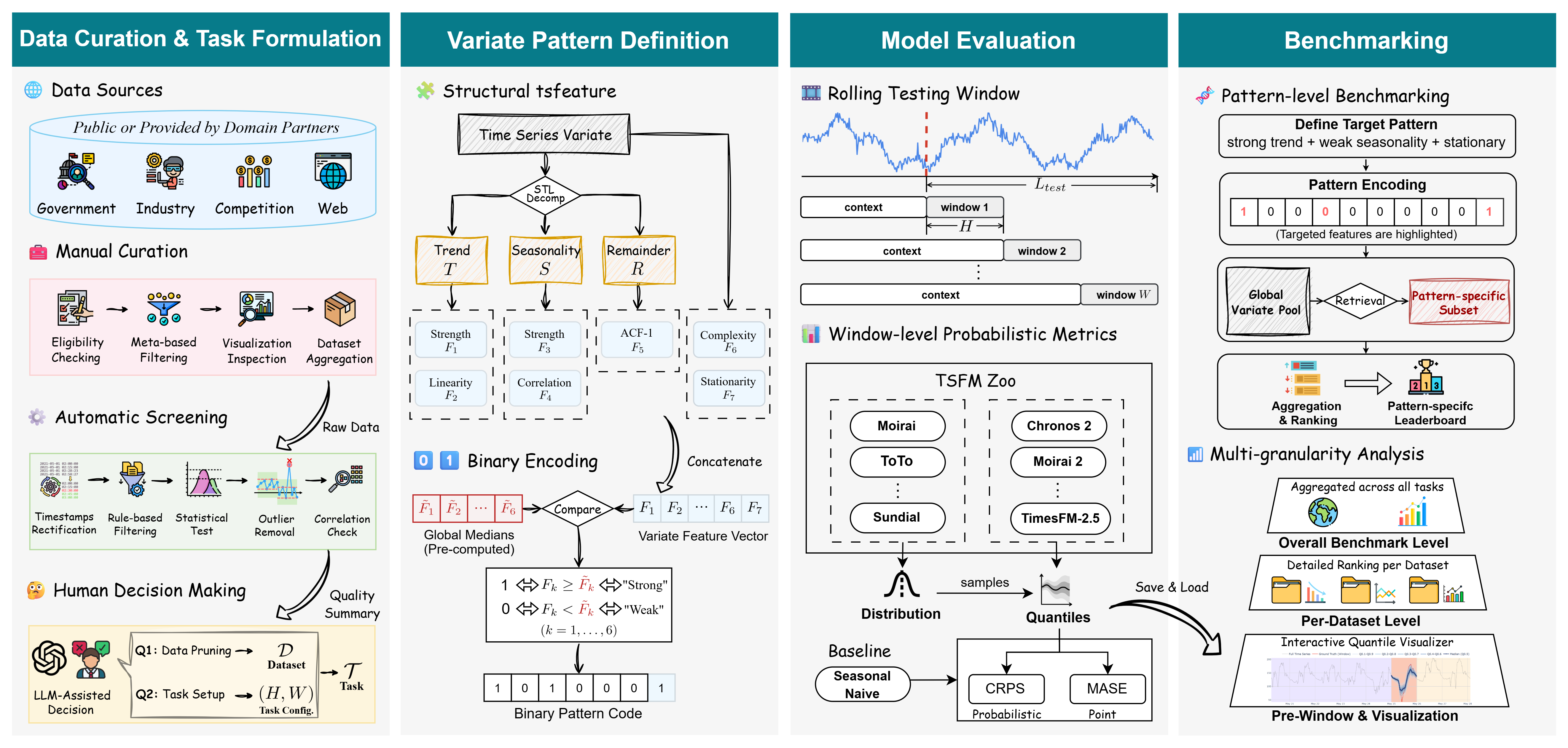
核心思路:TIME基准的核心思路是构建一个高质量、贴合实际、可泛化的时间序列预测评估平台。通过全新的数据集、严格的数据质量控制、实际的任务设置以及模式级别的评估视角,更全面地评估和分析时间序列预测模型的性能。
技术框架:TIME基准的构建流程包含以下几个主要阶段:1) 数据收集:收集50个全新的数据集,覆盖不同的领域和应用场景。2) 数据清洗:采用“人在环路”的方式,利用大型语言模型和人类专家进行数据清洗和质量控制,确保数据完整性和准确性。3) 任务定义:根据实际应用场景,定义98个预测任务,包括不同的预测长度、预测目标和约束条件。4) 模型评估:采用模式级别的评估视角,利用结构化时间序列特征来表征内在的时间属性,并构建多粒度的排行榜,以便更全面地评估和分析模型性能。
关键创新:TIME基准的关键创新在于:1) 全新的数据集:TIME基准使用全新的数据集,避免了数据重复使用和数据泄露的问题。2) 严格的数据质量控制:TIME基准采用“人在环路”的方式,确保数据质量。3) 贴合实际的任务设置:TIME基准的任务设置与实际应用场景紧密结合。4) 模式级别的评估视角:TIME基准引入了模式级别的评估视角,可以更深入地了解模型在不同时间序列模式下的表现。
关键设计:TIME基准的关键设计包括:1) 数据集的多样性:TIME基准的数据集覆盖不同的领域和应用场景,包括金融、交通、能源等。2) 任务设置的灵活性:TIME基准的任务设置允许用户自定义预测长度、预测目标和约束条件。3) 评估指标的全面性:TIME基准采用多种评估指标,包括均方误差、平均绝对误差等,以全面评估模型性能。4) 排行榜的可视化:TIME基准的排行榜提供可视化界面,方便用户查看和比较不同模型的性能。
🖼️ 关键图片
📊 实验亮点
TIME基准评估了12个具有代表性的TSFM,并建立了一个多粒度排行榜。实验结果表明,现有TSFM在TIME基准上的表现参差不齐,表明TIME基准能够有效区分不同模型的性能。TIME基准的模式级别评估视角能够更深入地了解模型在不同时间序列模式下的表现,为模型改进提供了新的思路。
🎯 应用场景
TIME基准可应用于时间序列预测模型的开发、评估和选择。研究人员和工程师可以使用TIME基准来评估其模型的性能,并与其他模型进行比较。企业可以使用TIME基准来选择最适合其业务需求的预测模型。TIME基准的推出将促进时间序列预测领域的发展,并推动更多实际应用。
📄 摘要(原文)
Time series foundation models (TSFMs) are revolutionizing the forecasting landscape from specific dataset modeling to generalizable task evaluation. However, we contend that existing benchmarks exhibit common limitations in four dimensions: constrained data composition dominated by reused legacy sources, compromised data integrity lacking rigorous quality assurance, misaligned task formulations detached from real-world contexts, and rigid analysis perspectives that obscure generalizable insights. To bridge these gaps, we introduce TIME, a next-generation task-centric benchmark comprising 50 fresh datasets and 98 forecasting tasks, tailored for strict zero-shot TSFM evaluation free from data leakage. Integrating large language models and human expertise, we establish a rigorous human-in-the-loop benchmark construction pipeline to ensure high data integrity and redefine task formulation by aligning forecasting configurations with real-world operational requirements and variate predictability. Furthermore, we propose a novel pattern-level evaluation perspective that moves beyond traditional dataset-level evaluations based on static meta labels. By leveraging structural time series features to characterize intrinsic temporal properties, this approach offers generalizable insights into model capabilities across diverse patterns. We evaluate 12 representative TSFMs and establish a multi-granular leaderboard to facilitate in-depth analysis and visualized inspection. The leaderboard is available at https://huggingface.co/spaces/Real-TSF/TIME-leaderboard.