On the Complexity of Offline Reinforcement Learning with $Q^\star$-Approximation and Partial Coverage
作者: Haolin Liu, Braham Snyder, Chen-Yu Wei
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-12
💡 一句话要点
提出新的框架以解决离线强化学习中的复杂性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Q学习 样本复杂度 决策估计 贝尔曼完备性 部分覆盖 信息论
📋 核心要点
- 现有的离线强化学习方法在部分覆盖情况下的样本效率未得到充分理论支持,尤其是$Q^ ext{star}$可实现性和贝尔曼完备性是否足够的问题。
- 论文提出了一个通用框架,利用信息论下界和决策估计系数,系统性地分析$Q^ ext{star}$函数类的复杂性,进而改进了样本复杂度的界限。
- 通过引入新的二阶性能差异引理,论文在部分覆盖下实现了软$Q$学习的样本复杂度从$ε^{-4}$到$ε^{-2}$的显著提升,且首次分析了CQL的更广泛适用性。
📝 摘要(中文)
我们研究了在$Q^ ext{star}$-近似和部分覆盖下的离线强化学习,这一设置激励了如保守$Q$学习(CQL)等实用算法,但理论关注有限。我们通过建立信息论下界,否定了$Q^ ext{star}$可实现性和贝尔曼完备性对样本效率的充分性。进一步地,我们引入了一个通用框架,表征给定$Q^ ext{star}$函数类的内在复杂性,并提出了新的二阶性能差异引理,首次在部分覆盖下为软$Q$学习提供了$ε^{-2}$的样本复杂度,改进了现有的$ε^{-4}$界限。此外,我们还首次分析了在$Q^ ext{star}$可实现性和贝尔曼完备性下的CQL,超越了表格情况的限制。
🔬 方法详解
问题定义:本论文旨在解决离线强化学习在部分覆盖情况下的样本效率问题,现有方法在理论上未能充分探讨$Q^ ext{star}$可实现性和贝尔曼完备性对样本效率的影响。
核心思路:论文通过建立信息论下界,否定了现有理论的充分性,并引入一个通用框架来表征$Q^ ext{star}$函数类的复杂性,以此为基础改进样本复杂度的界限。
技术框架:整体架构包括信息论下界的建立、决策估计系数的引入以及二阶性能差异引理的开发,模块化现有的$Q^ ext{star}$估计程序,形成一个系统的分析工具。
关键创新:论文的主要创新在于首次提出了在部分覆盖下的软$Q$学习的$ε^{-2}$样本复杂度,显著优于之前的$ε^{-4}$界限,同时去除了对额外在线交互的需求。
关键设计:在技术细节上,论文设计了新的损失函数和参数设置,以适应决策估计系数的计算,并确保在不同的$Q^ ext{star}$估计程序中具有良好的适应性。
🖼️ 关键图片
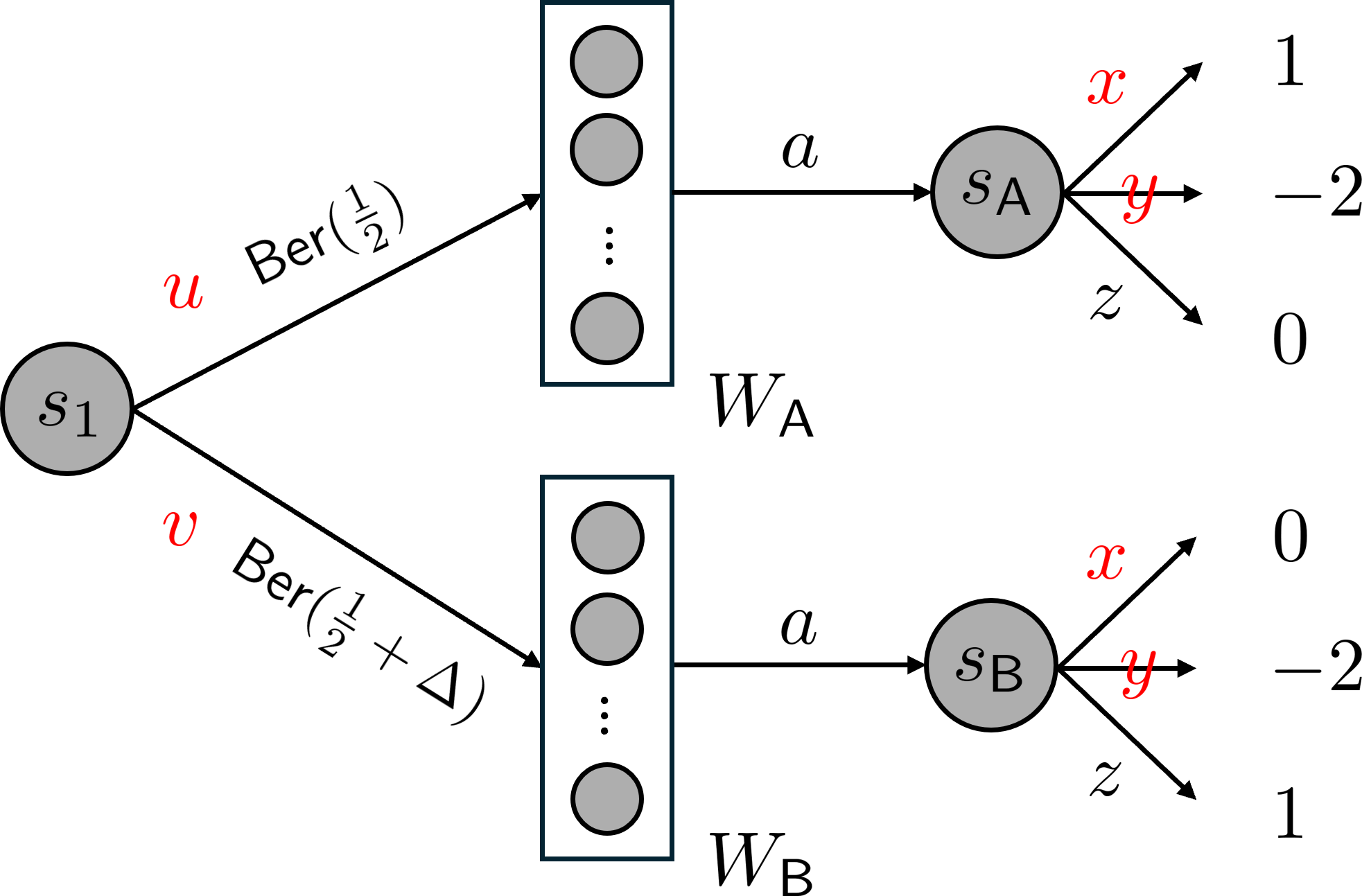
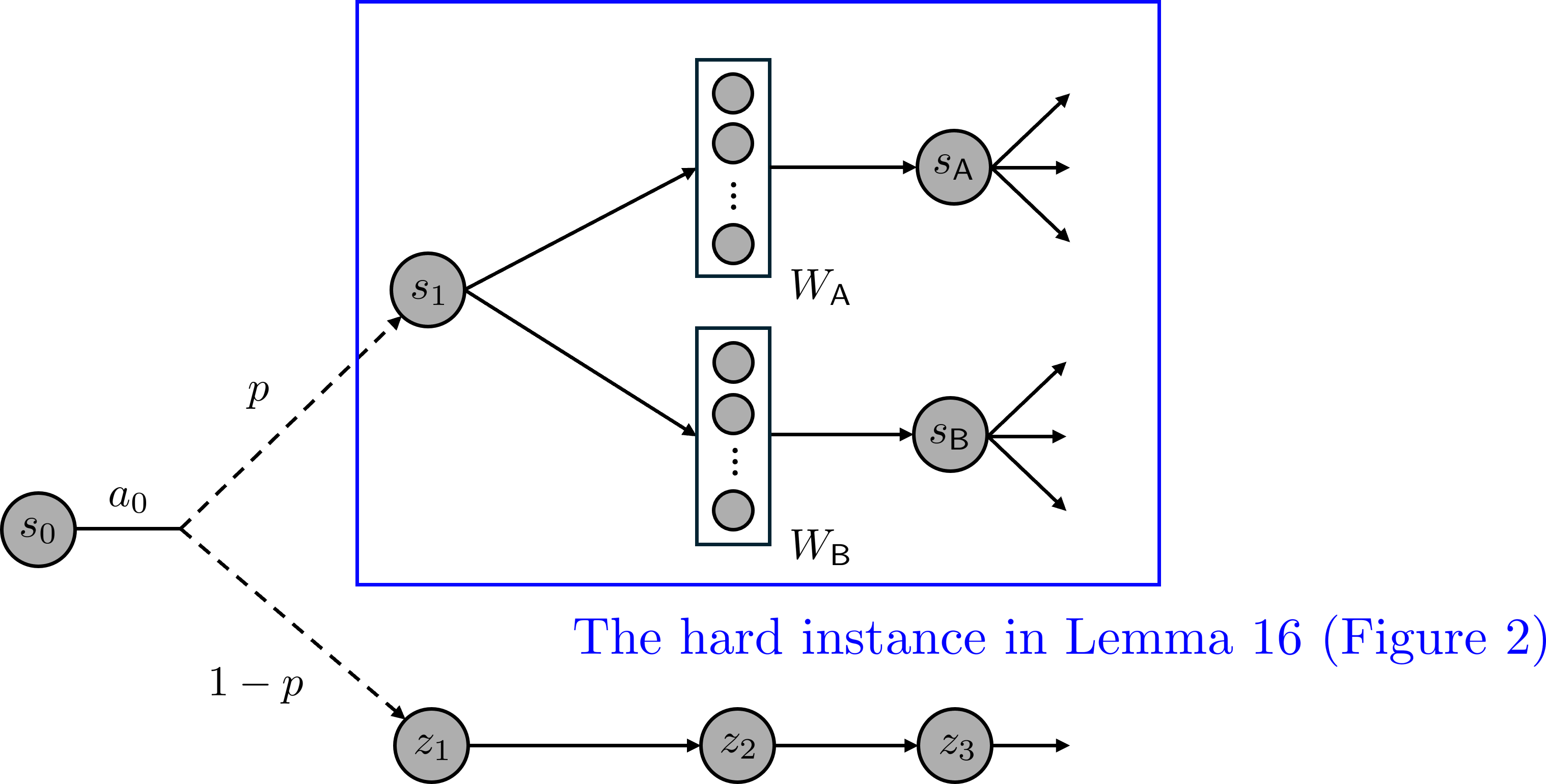

📊 实验亮点
论文的实验结果显示,新的二阶性能差异引理使得软$Q$学习的样本复杂度从$ε^{-4}$提升至$ε^{-2}$,在部分覆盖的情况下显著提高了学习效率。此外,首次对CQL在更广泛条件下的适用性进行了分析,拓展了其应用范围。
🎯 应用场景
该研究的潜在应用领域包括机器人控制、自动驾驶、医疗决策等需要高效决策的场景。通过提升离线强化学习的样本效率,能够在实际应用中减少对在线交互的依赖,从而降低成本和风险,具有重要的实际价值和未来影响。
📄 摘要(原文)
We study offline reinforcement learning under $Q^\star$-approximation and partial coverage, a setting that motivates practical algorithms such as Conservative $Q$-Learning (CQL; Kumar et al., 2020) but has received limited theoretical attention. Our work is inspired by the following open question: "Are $Q^\star$-realizability and Bellman completeness sufficient for sample-efficient offline RL under partial coverage?" We answer in the negative by establishing an information-theoretic lower bound. Going substantially beyond this, we introduce a general framework that characterizes the intrinsic complexity of a given $Q^\star$ function class, inspired by model-free decision-estimation coefficients (DEC) for online RL (Foster et al., 2023b; Liu et al., 2025b). This complexity recovers and improves the quantities underlying the guarantees of Chen and Jiang (2022) and Uehara et al. (2023), and extends to broader settings. Our decision-estimation decomposition can be combined with a wide range of $Q^\star$ estimation procedures, modularizing and generalizing existing approaches. Beyond the general framework, we make further contributions: By developing a novel second-order performance difference lemma, we obtain the first $ε^{-2}$ sample complexity under partial coverage for soft $Q$-learning, improving the $ε^{-4}$ bound of Uehara et al. (2023). We remove Chen and Jiang's (2022) need for additional online interaction when the value gap of $Q^\star$ is unknown. We also give the first characterization of offline learnability for general low-Bellman-rank MDPs without Bellman completeness (Jiang et al., 2017; Du et al., 2021; Jin et al., 2021), a canonical setting in online RL that remains unexplored in offline RL except for special cases. Finally, we provide the first analysis for CQL under $Q^\star$-realizability and Bellman completeness beyond the tabular case.