Improving HPC Code Generation Capability of LLMs via Online Reinforcement Learning with Real-Machine Benchmark Rewards
作者: Ryo Mikasa, Shun-ichiro Hayashi, Daichi Mukunoki, Tetsuya Hoshino, Takahiro Katagiri
分类: cs.LG
发布日期: 2026-02-12
💡 一句话要点
提出基于真实超算反馈的在线强化学习方法,提升LLM生成高性能HPC代码能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 高性能计算 代码生成 运行时性能 在线学习 超算 代码优化
📋 核心要点
- 现有LLM代码生成能力强,但难以保证生成代码在高性能计算(HPC)领域的运行时性能。
- 提出在线强化学习方法,利用超算直接反馈代码运行时性能(GFLOPS)作为奖励,优化LLM代码生成。
- 引入分阶段质量多样性(SQD)算法,逐步调整优化策略,使模型从多角度学习代码优化,提升泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面表现出强大的能力,但生成的代码的运行时性能无法保证,并且很少有尝试使用运行时性能作为奖励在HPC领域训练LLMs。我们提出了一种在线强化学习方法,该方法在超级计算机上执行LLM生成的代码,并直接将测量的运行时性能(GFLOPS)反馈作为奖励。我们进一步引入了一种分阶段质量多样性(SQD)算法,该算法逐步改变每个问题允许的优化技术,使模型能够从不同的角度学习代码优化。我们构建了一个分布式系统,将GPU训练集群与CPU基准测试集群连接起来,并使用Group Relative Policy Optimization(GRPO)在双精度矩阵乘法任务上训练Qwen2.5 Coder 14B。通过两个实验,我们表明,将运行时性能反馈与分阶段优化相结合的强化学习可以提高LLMs的HPC代码生成能力。
🔬 方法详解
问题定义:论文旨在解决LLM生成的代码在HPC领域性能不足的问题。现有方法缺乏有效的运行时性能反馈机制,难以指导LLM生成高性能代码。直接在真实硬件上进行评估成本高昂,且探索空间巨大,难以有效训练模型。
核心思路:论文的核心思路是利用在线强化学习,将LLM生成的代码部署到真实超算上运行,并将运行时的性能指标(GFLOPS)作为奖励信号反馈给LLM,从而指导LLM生成更高效的代码。同时,引入分阶段质量多样性(SQD)算法,逐步探索不同的优化策略,提高模型的泛化能力和鲁棒性。
技术框架:该方法构建了一个分布式系统,包含一个GPU训练集群和一个CPU基准测试集群。LLM在GPU集群上进行训练,生成的代码被发送到CPU集群进行基准测试,测试结果(GFLOPS)作为奖励信号反馈给LLM。训练过程使用Group Relative Policy Optimization (GRPO) 算法。SQD算法在训练过程中逐步调整允许的优化技术,例如循环展开、向量化等。
关键创新:该方法最重要的创新点在于将真实硬件的运行时性能直接作为奖励信号,用于训练LLM。这克服了传统方法中缺乏真实反馈的问题,能够更有效地指导LLM生成高性能代码。SQD算法的引入,使得模型能够从不同的优化角度学习,提高了模型的泛化能力。
关键设计:论文使用Qwen2.5 Coder 14B作为基础LLM,并使用GRPO算法进行强化学习训练。奖励函数直接使用GFLOPS值。SQD算法通过预定义的优化技术集合,在训练过程中逐步增加允许使用的优化技术,从而引导模型探索不同的优化策略。具体参数设置和网络结构细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片

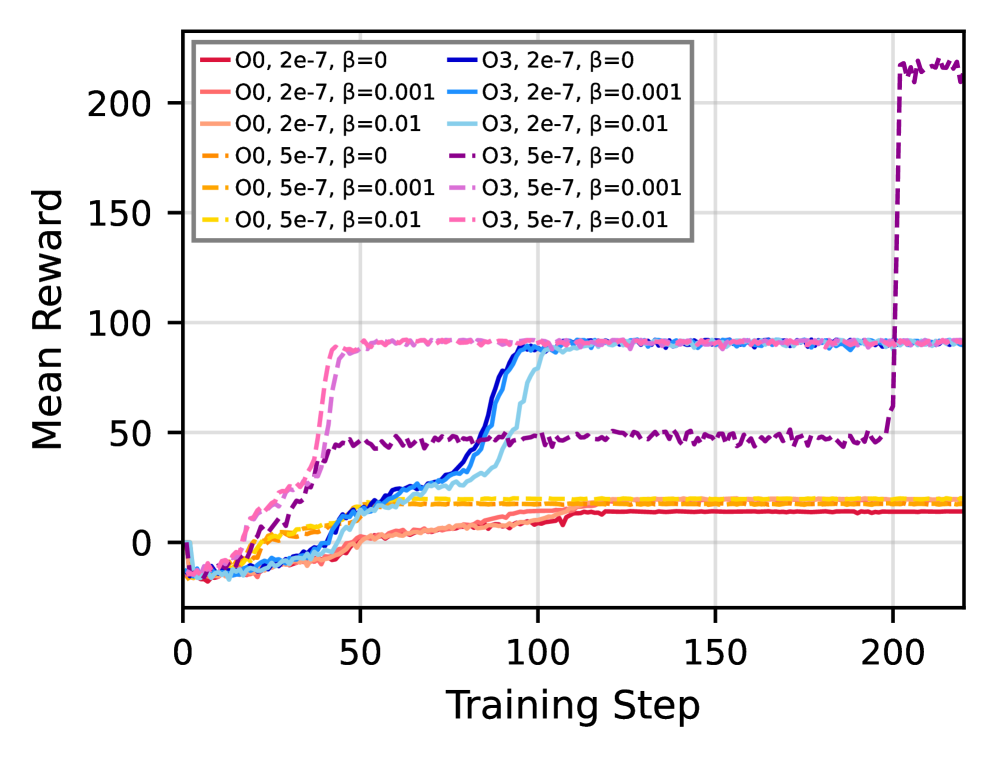
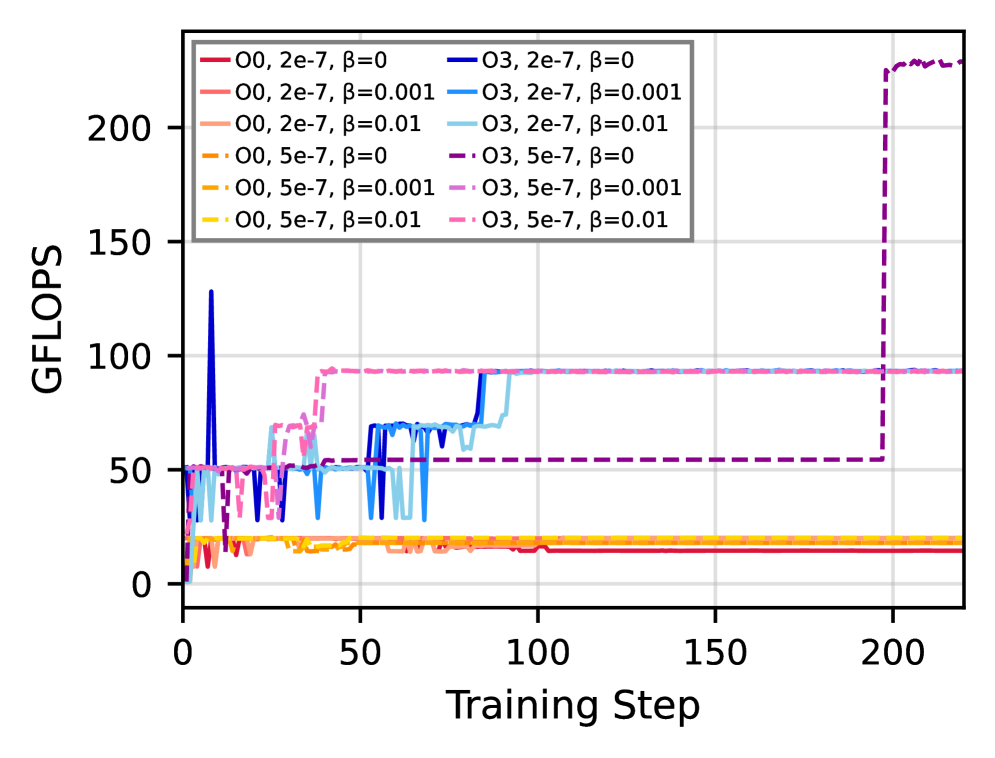
📊 实验亮点
实验结果表明,结合运行时性能反馈和分阶段优化的强化学习方法,能够有效提高LLM的HPC代码生成能力。具体性能数据和对比基线未在摘要中给出,属于未知信息。但论文强调了该方法在提升代码性能方面的潜力。
🎯 应用场景
该研究成果可应用于高性能计算领域,帮助开发者利用LLM自动生成高性能代码,加速科学计算、工程仿真等任务。通过在线强化学习和真实硬件反馈,可以显著提升LLM生成代码的效率和质量,降低人工优化成本,并推动HPC应用的普及。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong code generation capabilities, yet the runtime performance of generated code is not guaranteed, and there have been few attempts to train LLMs using runtime performance as a reward in the HPC domain. We propose an online reinforcement learning approach that executes LLM-generated code on a supercomputer and directly feeds back the measured runtime performance (GFLOPS) as a reward. We further introduce a Staged Quality-Diversity (SQD) algorithm that progressively varies the permitted optimization techniques on a per-problem basis, enabling the model to learn code optimization from diverse perspectives. We build a distributed system connecting a GPU training cluster with a CPU benchmarking cluster, and train Qwen2.5 Coder 14B on a double-precision matrix multiplication task using Group Relative Policy Optimization (GRPO). Through two experiments, we show that reinforcement learning combining runtime performance feedback with staged optimization can improve the HPC code generation capability of LLMs.