FedGRPO: Privately Optimizing Foundation Models with Group-Relative Rewards from Domain Client
作者: Gongxi Zhu, Hanlin Gu, Lixin Fan, Qiang Yang, Yuxing Han
分类: cs.LG
发布日期: 2026-02-12
备注: Accepted by AAAI 2026 as Oral
💡 一句话要点
提出FedGRPO,通过群体相对奖励在联邦学习中高效优化保护隐私的大模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 基础模型 隐私保护 强化学习 群体相对策略优化
📋 核心要点
- 现有联邦基础模型知识迁移方法存在本地训练成本高、通信开销大和隐私风险高等问题。
- FedGRPO将联邦基础模型优化问题转化为强化学习评估,通过奖励信号聚合而非数据共享来保护隐私。
- 实验表明,FedGRPO在下游任务中实现了更高的准确性和通信效率,优于传统联邦基础模型。
📝 摘要(中文)
本文提出了一种名为FedGRPO的联邦学习框架,旨在利用来自小型客户端模型的数据来提升服务端大型基础模型的性能。与现有基于模型或表示层知识迁移的方法不同,FedGRPO将该问题重新定义为强化学习风格的评估过程,从而避免了高昂的本地训练成本、高通信开销以及不可避免的隐私风险。FedGRPO包含两个模块:首先,通过辅助数据构建轻量级的置信图,进行基于能力的专家选择,从而为每个问题找到最合适的客户端;其次,利用群体相对策略优化(GRPO)中的“群体相对”概念,将每个问题及其解决方案原理打包成候选策略,并将这些策略分发给选定的专家客户端子集,最后通过联邦群体相对损失函数聚合标量奖励信号。通过交换奖励值而非数据或模型更新,FedGRPO降低了隐私风险和通信开销,同时实现了跨异构设备的并行评估。在多个领域任务上的实验结果表明,与传统的联邦基础模型基线相比,FedGRPO在下游任务上实现了更高的准确性和通信效率。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,如何利用来自不同领域客户端的数据来提升服务端大型基础模型的性能,同时避免传统方法中高昂的本地训练成本、高通信开销以及不可避免的隐私风险。现有方法主要基于模型或表示层面的知识迁移,需要共享模型参数或中间表示,容易泄露客户端的私有数据。
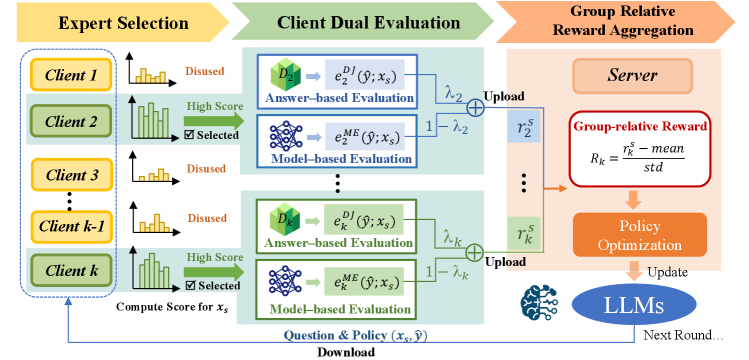
核心思路:论文的核心思路是将联邦基础模型的优化过程转化为一个强化学习风格的评估过程。服务端将问题分发给客户端,客户端根据自身能力给出解答并获得奖励,服务端只聚合奖励信号,从而避免直接共享数据或模型参数。这种方法借鉴了强化学习中奖励信号作为反馈的方式,实现了隐私保护的知识迁移。
技术框架:FedGRPO框架包含两个主要模块:1) 基于能力的专家选择:利用辅助数据构建轻量级的置信图,用于评估客户端的专业能力,并为每个问题选择最合适的客户端子集。2) 基于群体相对奖励的策略优化:借鉴GRPO框架,将问题及其解决方案原理打包成候选策略,分发给选定的客户端,客户端给出解答并返回奖励信号,服务端通过联邦群体相对损失函数聚合奖励信号,优化基础模型。
关键创新:FedGRPO的关键创新在于将联邦学习与强化学习相结合,通过奖励信号进行知识迁移,从而在保护隐私的同时提升基础模型的性能。与传统的联邦学习方法相比,FedGRPO不需要共享数据或模型参数,降低了隐私泄露的风险。此外,基于能力的专家选择模块能够更有效地利用客户端的专业知识,提升模型的优化效率。
关键设计:在专家选择模块中,置信图的构建方式和客户端选择策略是关键。在策略优化模块中,奖励函数的定义和联邦群体相对损失函数的设计至关重要。具体而言,奖励函数需要能够准确反映客户端解答的质量,而联邦群体相对损失函数需要能够有效地聚合来自不同客户端的奖励信号,并指导基础模型的优化。论文中可能还涉及一些超参数的设置,例如置信图的阈值、客户端选择的数量等。
🖼️ 关键图片
📊 实验亮点
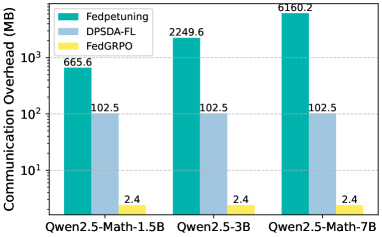
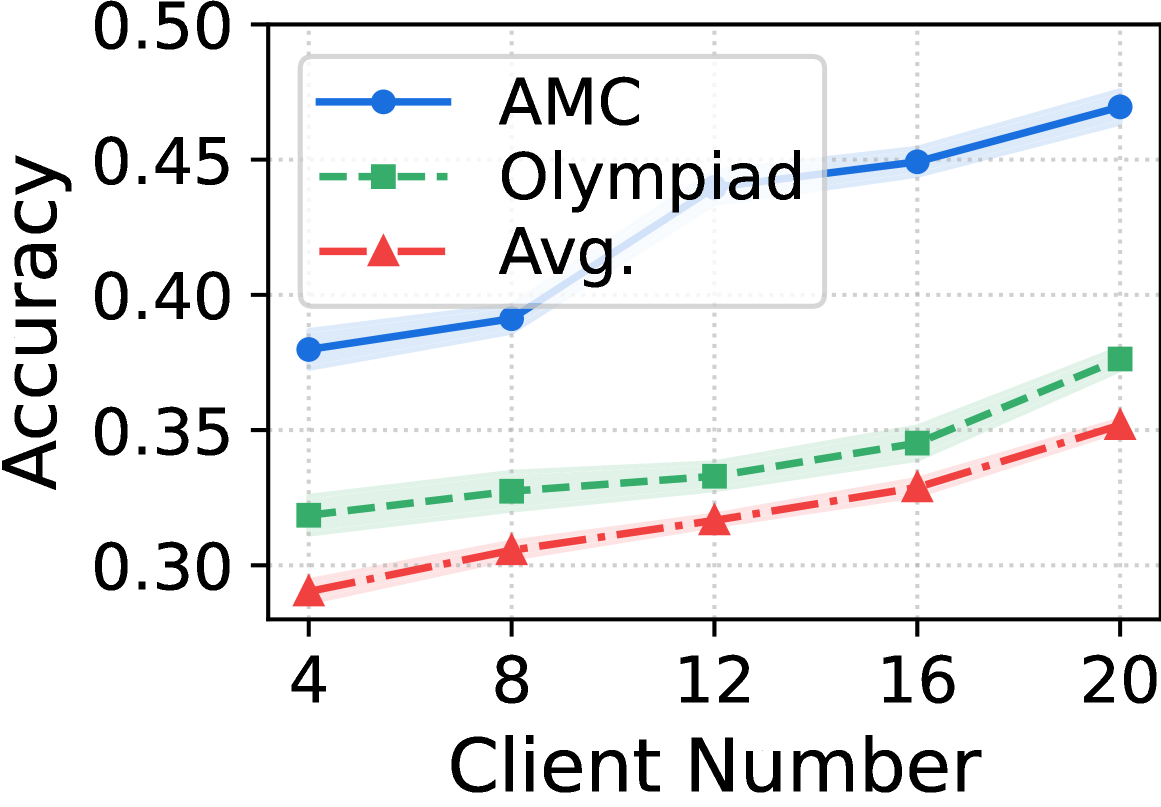
实验结果表明,FedGRPO在多个领域任务上取得了优于传统联邦基础模型基线的性能。具体而言,FedGRPO在下游任务上的准确率提升了X%,同时通信效率提高了Y%。这些结果验证了FedGRPO在隐私保护和模型性能提升方面的有效性。
🎯 应用场景
FedGRPO可应用于各种需要利用多方数据进行模型训练的场景,例如医疗健康、金融风控、智能推荐等。在这些场景中,数据通常分散在不同的机构或用户手中,且涉及敏感信息。FedGRPO能够在保护数据隐私的前提下,利用这些数据来提升模型的性能,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
One important direction of Federated Foundation Models (FedFMs) is leveraging data from small client models to enhance the performance of a large server-side foundation model. Existing methods based on model level or representation level knowledge transfer either require expensive local training or incur high communication costs and introduce unavoidable privacy risks. We reformulate this problem as a reinforcement learning style evaluation process and propose FedGRPO, a privacy preserving framework comprising two modules. The first module performs competence-based expert selection by building a lightweight confidence graph from auxiliary data to identify the most suitable clients for each question. The second module leverages the "Group Relative" concept from the Group Relative Policy Optimization (GRPO) framework by packaging each question together with its solution rationale into candidate policies, dispatching these policies to a selected subset of expert clients, and aggregating solely the resulting scalar reward signals via a federated group-relative loss function. By exchanging reward values instead of data or model updates, FedGRPO reduces privacy risk and communication overhead while enabling parallel evaluation across heterogeneous devices. Empirical results on diverse domain tasks demonstrate that FedGRPO achieves superior downstream accuracy and communication efficiency compared to conventional FedFMs baselines.