RAM-Net: Expressive Linear Attention with Selectively Addressable Memory
作者: Kaicheng Xiao, Haotian Li, Liran Dong, Guoliang Xing
分类: cs.LG, cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出RAM-Net,通过可选择寻址的显式记忆增强线性注意力的表达能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 记忆网络 长程依赖 稀疏寻址 检索任务
📋 核心要点
- 线性注意力模型存在将无限历史压缩到固定大小的记忆中,导致表达能力受限和信息丢失的问题。
- RAM-Net通过将输入映射到高维稀疏向量作为显式地址,选择性地访问大规模记忆状态,实现高效的记忆访问。
- 实验表明,RAM-Net在长程检索任务中超越了现有方法,并在语言建模和常识推理任务中表现出竞争力。
📝 摘要(中文)
线性注意力架构虽然提供了高效的推理能力,但将无界历史压缩到固定大小的记忆中,固有地限制了表达能力并导致信息丢失。为了解决这个限制,我们引入了随机存取记忆网络(RAM-Net),这是一种旨在弥合全注意力表示能力和线性模型记忆效率之间差距的新型架构。RAM-Net 的核心是将输入映射到高维稀疏向量,作为显式地址,允许模型选择性地访问大规模记忆状态。这种设计实现了指数级的状态大小扩展,而无需额外的参数,从而显著减轻了信号干扰并提高了检索保真度。此外,固有的稀疏性确保了卓越的计算效率,因为状态更新仅限于最少的条目。大量实验表明,RAM-Net 在细粒度的长程检索任务中始终优于最先进的基线,并在标准语言建模和零样本常识推理基准测试中实现了具有竞争力的性能,验证了其以显著降低的计算开销捕获复杂依赖关系的卓越能力。
🔬 方法详解
问题定义:现有线性注意力模型为了提高计算效率,通常会将所有历史信息压缩到一个固定大小的记忆中。这种压缩过程不可避免地会导致信息损失,限制了模型捕捉长程依赖关系和复杂模式的能力。尤其是在需要精细化检索的任务中,这种信息损失会严重影响模型的性能。
核心思路:RAM-Net的核心思想是引入一个可选择寻址的外部记忆模块,允许模型根据输入动态地选择需要访问的记忆单元。通过将输入映射到高维稀疏向量作为记忆地址,模型可以有效地扩展记忆容量,并在需要时精确地检索相关信息。这种设计旨在在计算效率和表达能力之间取得平衡。
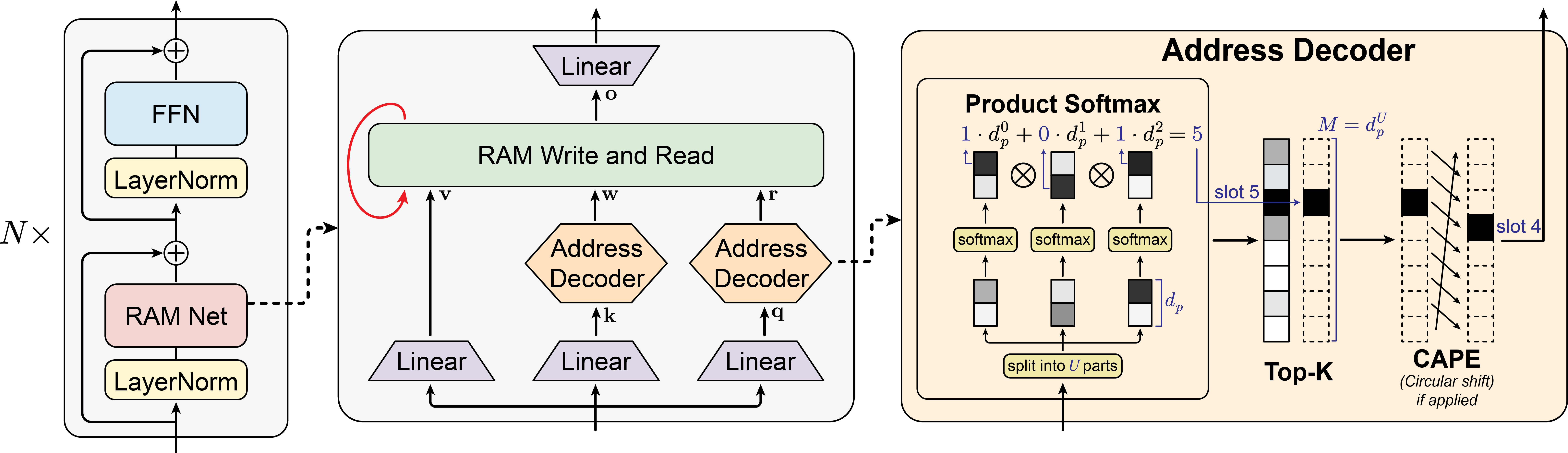
技术框架:RAM-Net的整体架构包括以下几个主要模块:1) 输入编码器:将输入序列编码成高维向量表示。2) 地址生成器:将编码后的输入映射到高维稀疏向量,作为记忆地址。3) 记忆模块:存储和更新记忆状态,并根据地址选择性地读取记忆内容。4) 输出解码器:将读取的记忆内容和输入编码进行融合,生成最终的输出。整个流程可以看作是一个动态寻址的读写过程,模型根据输入动态地选择需要访问和更新的记忆单元。
关键创新:RAM-Net最重要的创新点在于其可选择寻址的记忆机制。与传统的线性注意力模型不同,RAM-Net不依赖于固定大小的记忆压缩,而是通过稀疏寻址的方式访问一个大规模的外部记忆。这种设计允许模型在不增加过多计算负担的情况下,有效地扩展记忆容量,并提高检索的准确性。此外,稀疏寻址本身也带来了计算效率的提升。
关键设计:地址生成器是RAM-Net的关键组件之一,它负责将输入映射到高维稀疏向量。论文中可能使用了哈希函数或者其他稀疏编码技术来实现这一映射。损失函数的设计也至关重要,可能包括检索损失和重建损失等,以鼓励模型学习到有效的记忆表示和寻址策略。具体的网络结构细节(例如编码器和解码器的类型、记忆模块的实现方式等)未知,但这些细节都会影响模型的最终性能。
🖼️ 关键图片

📊 实验亮点
RAM-Net 在细粒度的长程检索任务中显著超越了现有基线模型,证明了其在捕捉复杂依赖关系方面的优越性。此外,在标准语言建模和零样本常识推理基准测试中,RAM-Net 也取得了具有竞争力的性能,同时保持了较低的计算开销。这些实验结果表明,RAM-Net 是一种有效的、高效的记忆增强型注意力模型。
🎯 应用场景
RAM-Net 具有广泛的应用前景,尤其是在需要处理长序列和复杂依赖关系的任务中。例如,它可以应用于长文本理解、知识图谱推理、对话生成等领域。其高效的记忆访问机制使其在资源受限的环境中也具有优势,例如移动设备上的自然语言处理应用。未来,RAM-Net有望成为构建更智能、更高效的AI系统的关键组成部分。
📄 摘要(原文)
While linear attention architectures offer efficient inference, compressing unbounded history into a fixed-size memory inherently limits expressivity and causes information loss. To address this limitation, we introduce Random Access Memory Network (RAM-Net), a novel architecture designed to bridge the gap between the representational capacity of full attention and the memory efficiency of linear models. The core of RAM-Net maps inputs to high-dimensional sparse vectors serving as explicit addresses, allowing the model to selectively access a massive memory state. This design enables exponential state size scaling without additional parameters, which significantly mitigates signal interference and enhances retrieval fidelity. Moreover, the inherent sparsity ensures exceptional computational efficiency, as state updates are confined to minimal entries. Extensive experiments demonstrate that RAM-Net consistently surpasses state-of-the-art baselines in fine-grained long-range retrieval tasks and achieves competitive performance in standard language modeling and zero-shot commonsense reasoning benchmarks, validating its superior capability to capture complex dependencies with significantly reduced computational overhead.