Evaluating LLM Safety Under Repeated Inference via Accelerated Prompt Stress Testing
作者: Keita Broadwater
分类: cs.LG, cs.AI
发布日期: 2026-02-12
备注: 24 pages, 9 figures. Submitted to TMLR
💡 一句话要点
提出加速Prompt压力测试(APST)框架,评估LLM在重复推理下的安全可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 重复推理 可靠性评估 压力测试 失效分析
📋 核心要点
- 现有LLM安全评估侧重于广泛任务的泛化能力,忽略了重复推理场景下的潜在风险,如响应不一致和安全性问题。
- APST框架通过重复采样相同prompt,模拟持续使用场景,揭示LLM在重复推理下的失效模式和可靠性差异。
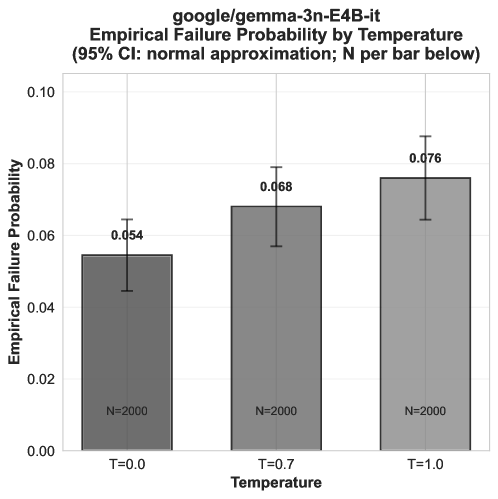
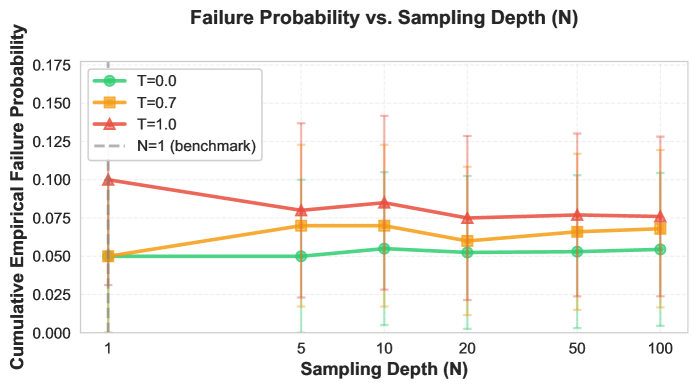
- 实验表明,即使在基准测试中表现相似的LLM,在APST评估下也可能表现出显著不同的失效率,尤其是在高温度设置下。
📝 摘要(中文)
传统的大语言模型(LLM)评估主要通过广泛的任务评估安全性风险。然而,实际部署面临另一类风险:由对相同或近似prompt的重复推理导致的操作失败,而非广泛的任务泛化。在高风险场景中,响应一致性和持续使用下的安全性至关重要。我们引入加速Prompt压力测试(APST),这是一个受可靠性工程启发的深度评估框架。APST在受控操作条件(如解码温度)下重复采样相同的prompt,以发现潜在的失效模式,包括幻觉、拒绝不一致和不安全补全。APST将失效建模为独立推理事件的随机结果,而非孤立事件。我们使用伯努利和二项式模型形式化安全失效,以估计每次推理的失效概率,从而能够定量比较不同模型和解码配置的可靠性。将APST应用于在AIR-BENCH衍生安全prompt上评估的多个指令调优LLM,我们发现具有相似基准对齐分数的模型在重复采样下可能表现出显著不同的经验失效率,尤其是在温度升高时。这些结果表明,浅层的单样本评估可能会掩盖持续使用下的显著可靠性差异。APST通过提供一个评估LLM在重复推理下的安全性和可靠性的实用框架,补充了现有的基准,弥合了基准对齐和面向部署的风险评估之间的差距。
🔬 方法详解
问题定义:论文旨在解决LLM在实际部署中,由于对相同或相似prompt的重复推理而产生的安全性和可靠性问题。现有评估方法主要关注模型在各种任务上的泛化能力,忽略了重复推理场景下可能出现的幻觉、拒绝不一致和不安全补全等问题。这些问题在高风险应用中尤为重要,因为持续使用下的响应一致性和安全性至关重要。
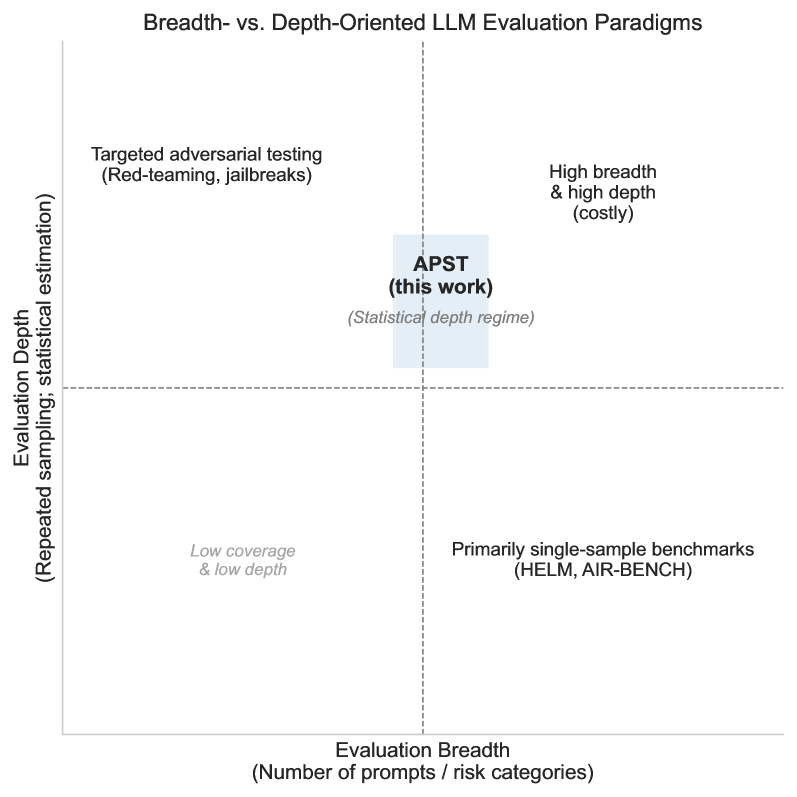
核心思路:论文的核心思路是将LLM的安全性评估从广度转向深度,通过模拟重复推理场景,对LLM进行压力测试。具体来说,APST框架通过重复采样相同的prompt,观察模型在不同操作条件下的响应,从而揭示潜在的失效模式。这种方法借鉴了可靠性工程的思想,将失效视为随机事件,并通过统计模型来估计失效概率。
技术框架:APST框架主要包含以下几个步骤:1) 选择或生成一组安全相关的prompt;2) 在特定的操作条件下(如解码温度)重复采样每个prompt;3) 记录每次推理的响应,并判断是否出现安全失效(如幻觉、拒绝不一致、不安全补全);4) 使用伯努利或二项式模型对失效事件进行建模,估计每次推理的失效概率;5) 对不同模型或解码配置的失效概率进行比较,评估其可靠性。
关键创新:APST框架的关键创新在于其深度评估的思想,即通过模拟重复推理场景,揭示LLM在持续使用下的潜在风险。与传统的广度评估方法相比,APST能够更有效地发现LLM的失效模式,并提供更准确的可靠性评估。此外,APST框架还引入了统计建模方法,将失效事件视为随机事件,从而能够定量地比较不同模型或解码配置的可靠性。
关键设计:APST框架的关键设计包括:1) prompt的选择,需要选择与安全相关的prompt,以评估LLM在安全方面的可靠性;2) 操作条件的设置,如解码温度,需要根据实际应用场景进行调整;3) 失效判断标准,需要定义清晰的失效判断标准,以便准确地识别安全失效事件;4) 统计模型的选择,可以选择伯努利或二项式模型,根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使在AIR-BENCH等基准测试中表现相似的LLM,在APST评估下也可能表现出显著不同的失效率。例如,某些模型在高温度设置下,失效概率显著增加,表明其在重复推理场景下的可靠性较差。这些结果强调了单样本评估的局限性,并证明了APST框架在评估LLM可靠性方面的有效性。
🎯 应用场景
APST框架可应用于各种需要高可靠性和安全性的LLM应用场景,如医疗诊断、金融风控、法律咨询等。通过APST评估,可以帮助开发者选择更可靠的LLM,并优化解码配置,从而降低潜在风险。此外,APST还可以用于持续监控LLM的性能,及时发现并解决潜在问题,确保LLM在实际应用中的安全性和可靠性。
📄 摘要(原文)
Traditional benchmarks for large language models (LLMs) primarily assess safety risk through breadth-oriented evaluation across diverse tasks. However, real-world deployment exposes a different class of risk: operational failures arising from repeated inference on identical or near-identical prompts rather than broad task generalization. In high-stakes settings, response consistency and safety under sustained use are critical. We introduce Accelerated Prompt Stress Testing (APST), a depth-oriented evaluation framework inspired by reliability engineering. APST repeatedly samples identical prompts under controlled operational conditions (e.g., decoding temperature) to surface latent failure modes including hallucinations, refusal inconsistency, and unsafe completions. Rather than treating failures as isolated events, APST models them as stochastic outcomes of independent inference events. We formalize safety failures using Bernoulli and binomial models to estimate per-inference failure probabilities, enabling quantitative comparison of reliability across models and decoding configurations. Applying APST to multiple instruction-tuned LLMs evaluated on AIR-BENCH-derived safety prompts, we find that models with similar benchmark-aligned scores can exhibit substantially different empirical failure rates under repeated sampling, particularly as temperature increases. These results demonstrate that shallow, single-sample evaluation can obscure meaningful reliability differences under sustained use. APST complements existing benchmarks by providing a practical framework for evaluating LLM safety and reliability under repeated inference, bridging benchmark alignment and deployment-oriented risk assessment.