Temperature as a Meta-Policy: Adaptive Temperature in LLM Reinforcement Learning
作者: Haoran Dang, Cuiling Lan, Hai Wan, Xibin Zhao, Yan Lu
分类: cs.LG
发布日期: 2026-02-12
备注: Accepted at ICLR 2026. 10 pages (main text) + supplementary material, 6 figures
💡 一句话要点
提出TAMPO,将温度控制视为元策略,自适应提升LLM强化学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 元学习 温度控制 自适应探索
📋 核心要点
- 传统强化学习中,LLM的温度超参数通常是静态或启发式调整,无法适应训练过程中的动态需求,限制了策略的改进。
- TAMPO将温度控制视为可学习的元策略,通过奖励高优势轨迹来优化温度分布,实现探索与策略改进的对齐。
- 实验表明,在数学推理任务上,TAMPO显著优于固定或启发式温度策略,验证了其有效性。
📝 摘要(中文)
本文提出了一种新的框架——温度自适应元策略优化(TAMPO),该框架将大型语言模型(LLM)中的温度控制重新定义为可学习的元策略。温度是LLM中的关键超参数,它控制文本生成过程中探索和利用之间的权衡。TAMPO通过分层的双循环过程运行:内循环使用元策略选择的温度采样轨迹来更新LLM策略(例如,使用GRPO);外循环通过奖励那些最大化高优势轨迹可能性的温度来更新候选温度上的分布。这种轨迹引导、奖励驱动的机制实现了在线自适应,无需额外的rollout,直接将探索与策略改进对齐。在五个数学推理基准测试中,TAMPO优于使用固定或启发式温度的基线,证明了温度作为LLM强化学习中自适应探索的有效可学习元策略。
🔬 方法详解
问题定义:论文旨在解决LLM强化学习中,温度超参数难以动态调整的问题。现有的方法通常采用固定的温度值或启发式的调整策略,无法根据训练的进程自适应地调整探索和利用的平衡,导致策略改进受限。
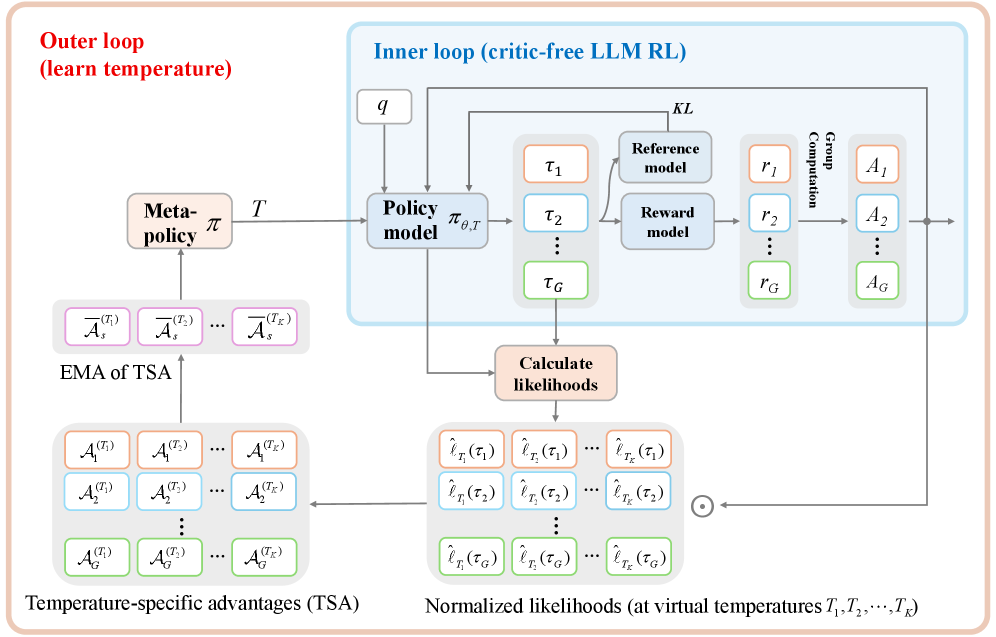
核心思路:论文的核心思路是将温度控制视为一个元策略,通过强化学习的方法学习一个策略来选择合适的温度。这个元策略的目标是最大化高优势轨迹的概率,从而引导LLM进行更有效的探索。
技术框架:TAMPO采用分层的双循环结构。内循环使用元策略选择的温度对LLM策略进行更新(例如,使用GRPO等算法)。外循环则根据内循环产生的轨迹,评估不同温度下的策略表现,并更新元策略,使其倾向于选择能够产生高优势轨迹的温度。
关键创新:TAMPO的关键创新在于将温度控制从一个静态的超参数调整问题,转化为一个动态的元学习问题。通过学习一个元策略来控制温度,可以实现对探索和利用的自适应平衡,从而提高强化学习的效率和性能。与现有方法相比,TAMPO无需额外rollout,直接利用已有的轨迹信息进行元策略的更新。
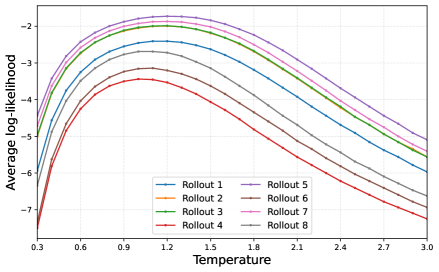
关键设计:TAMPO的关键设计包括:1) 使用优势函数来评估轨迹的质量,并以此作为元策略的奖励信号;2) 使用分布来表示候选温度,并通过更新分布来优化元策略;3) 采用在线学习的方式,在训练过程中不断更新元策略,使其能够适应LLM策略的变化。
🖼️ 关键图片
📊 实验亮点
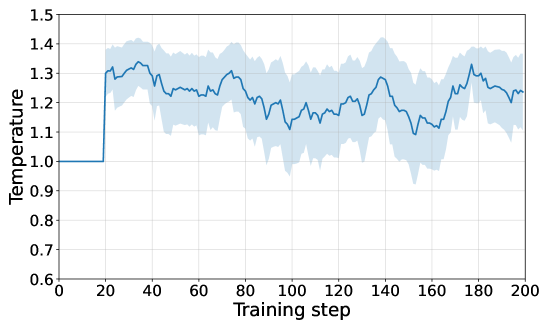
在五个数学推理基准测试中,TAMPO显著优于使用固定或启发式温度的基线方法。实验结果表明,TAMPO能够有效地学习到合适的温度策略,从而提高LLM在复杂推理任务中的性能。具体的性能提升数据需要在论文中查找。
🎯 应用场景
TAMPO方法具有广泛的应用前景,可以应用于各种需要LLM进行策略学习的任务中,例如机器人控制、对话生成、代码生成等。通过自适应地调整温度,可以提高LLM在这些任务中的探索效率和性能,使其能够更好地适应不同的环境和目标。
📄 摘要(原文)
Temperature is a crucial hyperparameter in large language models (LLMs), controlling the trade-off between exploration and exploitation during text generation. High temperatures encourage diverse but noisy outputs, while low temperatures produce focused outputs but may cause premature convergence. Yet static or heuristic temperature schedules fail to adapt to the dynamic demands of reinforcement learning (RL) throughout training, often limiting policy improvement. We propose Temperature Adaptive Meta Policy Optimization (TAMPO), a new framework that recasts temperature control as a learnable meta-policy. TAMPO operates through a hierarchical two-loop process. In the inner loop, the LLM policy is updated (e.g., using GRPO) with trajectories sampled at the temperature selected by the meta-policy. In the outer loop, meta-policy updates the distribution over candidate temperatures by rewarding those that maximize the likelihood of high-advantage trajectories. This trajectory-guided, reward-driven mechanism enables online adaptation without additional rollouts, directly aligning exploration with policy improvement. On five mathematical reasoning benchmarks, TAMPO outperforms baselines using fixed or heuristic temperatures, establishing temperature as an effective learnable meta-policy for adaptive exploration in LLM reinforcement learning. Accepted at ICLR 2026.