DICE: Diffusion Large Language Models Excel at Generating CUDA Kernels
作者: Haolei Bai, Lingcheng Kong, Xueyi Chen, Jianmian Wang, Zhiqiang Tao, Huan Wang
分类: cs.LG, cs.CL
发布日期: 2026-02-12
💡 一句话要点
DICE:扩散大语言模型擅长生成CUDA内核,性能超越自回归模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CUDA内核生成 扩散模型 大语言模型 强化学习 代码生成 高性能计算 CuKe数据集
📋 核心要点
- CUDA内核生成任务面临专业性强、高质量训练数据匮乏的挑战,限制了扩散模型在该领域的应用。
- 论文提出DICE模型,通过CuKe数据集和BiC-RL训练框架,优化扩散模型在CUDA内核生成方面的性能。
- 实验结果表明,DICE模型在KernelBench上显著优于同等规模的自回归和扩散模型,达到新的SOTA。
📝 摘要(中文)
扩散大语言模型(dLLMs)由于其并行token生成能力,已成为自回归(AR)LLMs的一个引人注目的替代方案。这种范式特别适合代码生成,因为整体结构规划和非顺序细化至关重要。尽管有这种潜力,但为CUDA内核生成定制dLLMs仍然具有挑战性,这不仅受到高度专业化的阻碍,而且还受到高质量训练数据的严重缺乏的阻碍。为了应对这些挑战,我们构建了CuKe,这是一个增强的监督微调数据集,针对高性能CUDA内核进行了优化。在此基础上,我们提出了一个双阶段精选强化学习(BiC-RL)框架,包括CUDA内核填充阶段和端到端CUDA内核生成阶段。利用这个训练框架,我们引入了DICE,一系列为CUDA内核生成而设计的扩散大语言模型,跨越三个参数规模,1.7B、4B和8B。在KernelBench上的大量实验表明,DICE显著优于同等规模的自回归和扩散LLMs,为CUDA内核生成建立了一个新的最先进水平。
🔬 方法详解
问题定义:论文旨在解决CUDA内核自动生成的问题。现有方法,特别是基于自回归LLM的方法,在处理代码生成任务时,难以进行全局结构规划和非序列化的代码优化。此外,高质量的CUDA内核训练数据非常稀缺,限制了模型的性能。
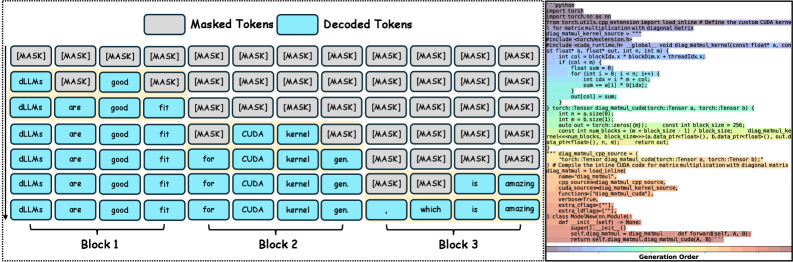
核心思路:论文的核心思路是利用扩散模型并行生成token的优势,结合高质量的CUDA内核数据集和专门设计的强化学习训练框架,来提升CUDA内核生成的质量和效率。扩散模型允许模型同时考虑整个代码结构,从而更好地进行全局优化。
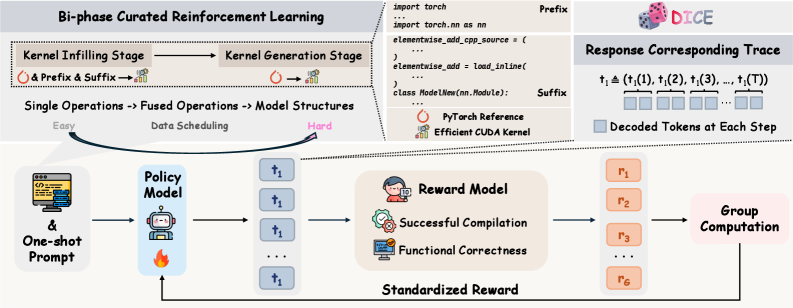
技术框架:DICE的整体框架包含以下几个关键部分:首先,构建CuKe数据集,这是一个专门为CUDA内核生成设计的增强型监督微调数据集。其次,提出BiC-RL(双阶段精选强化学习)框架,包含CUDA内核填充阶段和端到端CUDA内核生成阶段。最后,基于该框架训练DICE模型,该模型是一系列不同参数规模(1.7B、4B和8B)的扩散大语言模型。
关键创新:论文的关键创新在于:1) 构建了高质量的CuKe数据集,缓解了CUDA内核训练数据不足的问题;2) 提出了BiC-RL训练框架,该框架通过两阶段的强化学习,有效地提升了模型的生成能力;3) 将扩散模型应用于CUDA内核生成,利用其并行生成token的优势,实现了更好的全局优化。
关键设计:CuKe数据集通过数据增强和过滤,保证了数据的质量和多样性。BiC-RL框架中,CUDA内核填充阶段旨在让模型学习如何补全不完整的CUDA内核代码,而端到端CUDA内核生成阶段则旨在让模型从头开始生成完整的CUDA内核代码。具体损失函数和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
DICE模型在KernelBench基准测试中取得了显著的性能提升,超越了同等规模的自回归和扩散模型,确立了CUDA内核生成领域的新SOTA。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。但结论是DICE模型显著优于现有方法。
🎯 应用场景
DICE模型在高性能计算、嵌入式系统和人工智能加速等领域具有广泛的应用前景。它可以帮助开发者快速生成优化的CUDA内核代码,从而加速应用程序的开发和部署,并提高计算效率。未来,该技术有望应用于更复杂的异构计算平台,实现更高效的并行计算。
📄 摘要(原文)
Diffusion large language models (dLLMs) have emerged as a compelling alternative to autoregressive (AR) LLMs, owing to their capacity for parallel token generation. This paradigm is particularly well-suited for code generation, where holistic structural planning and non-sequential refinement are critical. Despite this potential, tailoring dLLMs for CUDA kernel generation remains challenging, obstructed not only by the high specialization but also by the severe lack of high-quality training data. To address these challenges, we construct CuKe, an augmented supervised fine-tuning dataset optimized for high-performance CUDA kernels. On top of it, we propose a bi-phase curated reinforcement learning (BiC-RL) framework consisting of a CUDA kernel infilling stage and an end-to-end CUDA kernel generation stage. Leveraging this training framework, we introduce DICE, a series of diffusion large language models designed for CUDA kernel generation, spanning three parameter scales, 1.7B, 4B, and 8B. Extensive experiments on KernelBench demonstrate that DICE significantly outperforms both autoregressive and diffusion LLMs of comparable scale, establishing a new state-of-the-art for CUDA kernel generation.