SkillRater: Untangling Capabilities in Multimodal Data
作者: Naveen Sahi, Jeremy Dohmann, Armen Aghajanyan, Akshat Shrivastava
分类: cs.LG
发布日期: 2026-02-12
💡 一句话要点
SkillRater:解耦多模态数据中的能力,提升视觉语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 数据筛选 元学习 多模态学习 能力解耦
📋 核心要点
- 现有数据筛选方法使用单一质量评分,无法有效处理需要多种能力的训练任务。
- SkillRater将数据质量分解为多个能力维度,为每个维度训练专门的评分器。
- 实验表明,SkillRater在视觉理解、OCR和STEM推理任务上显著优于传统方法。
📝 摘要(中文)
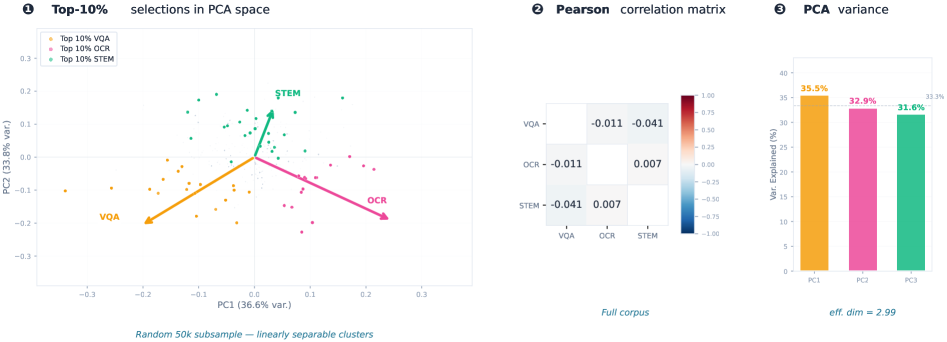
数据筛选方法通常为样本分配单一质量评分。我们认为这种标量框架存在根本性局限:当训练需要多个不同的能力时,单一的评分器无法同时最大化所有能力的有用信号。质量最好被理解为多维的,每个维度对应于模型必须获得的能力。我们提出了SkillRater,一个将数据过滤分解为专门评分器的框架——每个能力一个评分器,每个评分器通过元学习在不相交的验证目标上进行训练——并通过渐进式选择规则组合它们的分数:在每个训练阶段,如果任何评分器将样本的排名高于随时间收紧的阈值,则保留该样本,从而在早期保持多样性,而在后期专注于高价值样本。我们在视觉语言模型上验证了这种方法,将质量分解为三个能力维度:视觉理解、OCR和STEM推理。在20亿参数规模下,SkillRater在保留的基准测试中,视觉理解能力提高了5.63%,OCR提高了2.00%,STEM提高了3.53%。学习到的评分器信号几乎是正交的,这证实了解耦捕获了真正独立的质量维度,并解释了为什么它优于未经过滤的训练和单一的学习过滤。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型训练中,使用单一质量评分进行数据筛选的局限性问题。现有方法无法有效区分和利用数据中蕴含的不同类型知识,导致模型在多个能力上难以同时优化。例如,一个图像可能包含丰富的视觉信息,但OCR质量较差,单一评分无法有效区分这些差异,从而影响模型训练。
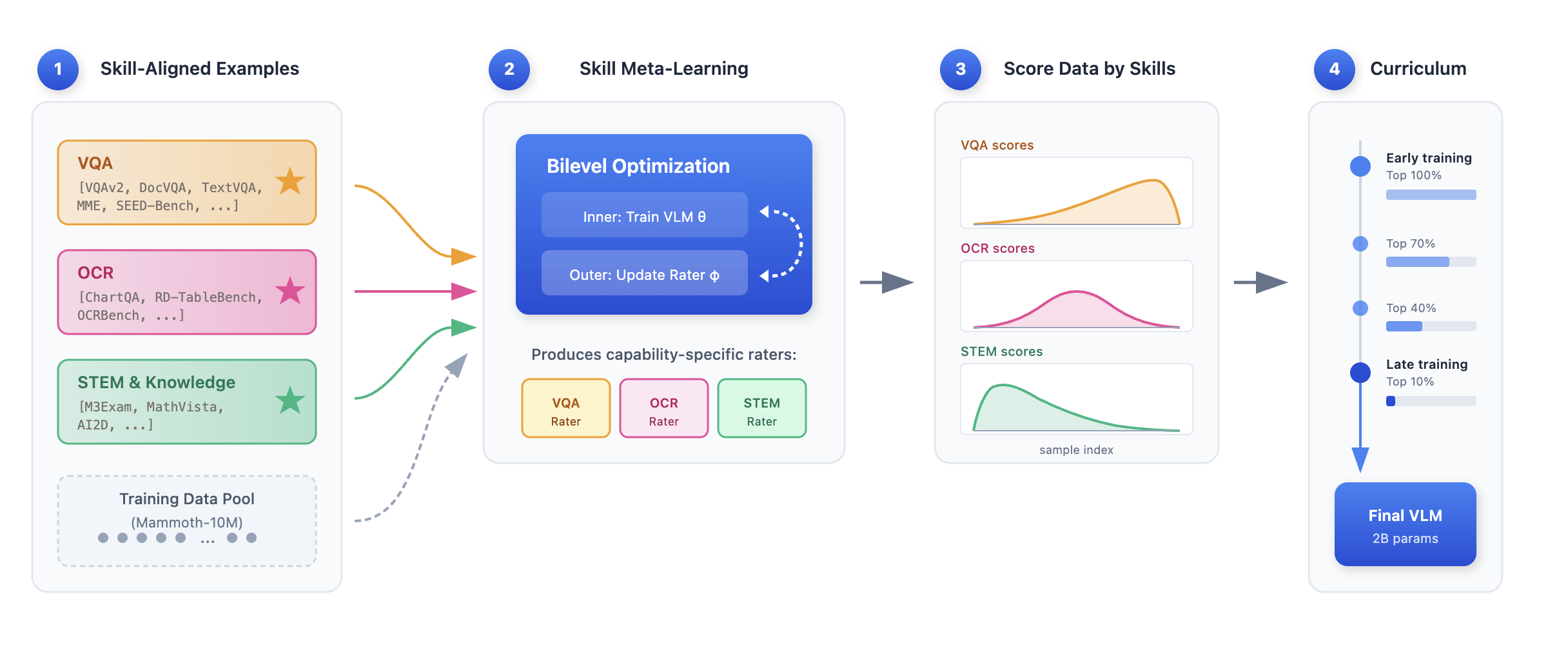
核心思路:SkillRater的核心思路是将数据质量解耦为多个能力维度,例如视觉理解、OCR和STEM推理。针对每个能力维度,训练一个专门的评分器,用于评估数据在该维度上的质量。通过这种方式,可以更精细地控制数据的选择,从而更好地训练模型在各个能力上的表现。
技术框架:SkillRater框架包含以下主要模块:1) 能力定义:确定需要模型具备的关键能力。2) 评分器训练:为每个能力训练一个专门的评分器,评分器通过元学习在不相交的验证目标上进行训练。3) 渐进式选择:在训练过程中,根据评分器的输出,逐步筛选数据。早期阶段,保留所有评分器评分较高的样本,以保持数据多样性;后期阶段,提高评分阈值,专注于高质量样本。4) 模型训练:使用筛选后的数据训练视觉语言模型。
关键创新:SkillRater的关键创新在于将数据质量解耦为多个能力维度,并为每个维度训练专门的评分器。这种方法能够更精细地控制数据的选择,从而更好地训练模型在各个能力上的表现。与现有方法的本质区别在于,SkillRater不再使用单一的质量评分,而是使用多个评分器来评估数据的不同方面。
关键设计:SkillRater的关键设计包括:1) 元学习:使用元学习训练评分器,使其能够快速适应新的数据集和任务。2) 渐进式选择规则:设计渐进式选择规则,以在训练早期保持数据多样性,并在后期专注于高质量样本。具体而言,每个训练阶段,一个样本被保留,如果任何评分器将其排名高于一个阈值,该阈值随时间收紧。3) 评分器架构:评分器可以使用各种神经网络架构,例如Transformer或CNN。论文中未明确说明评分器具体架构,属于未知信息。
🖼️ 关键图片
📊 实验亮点
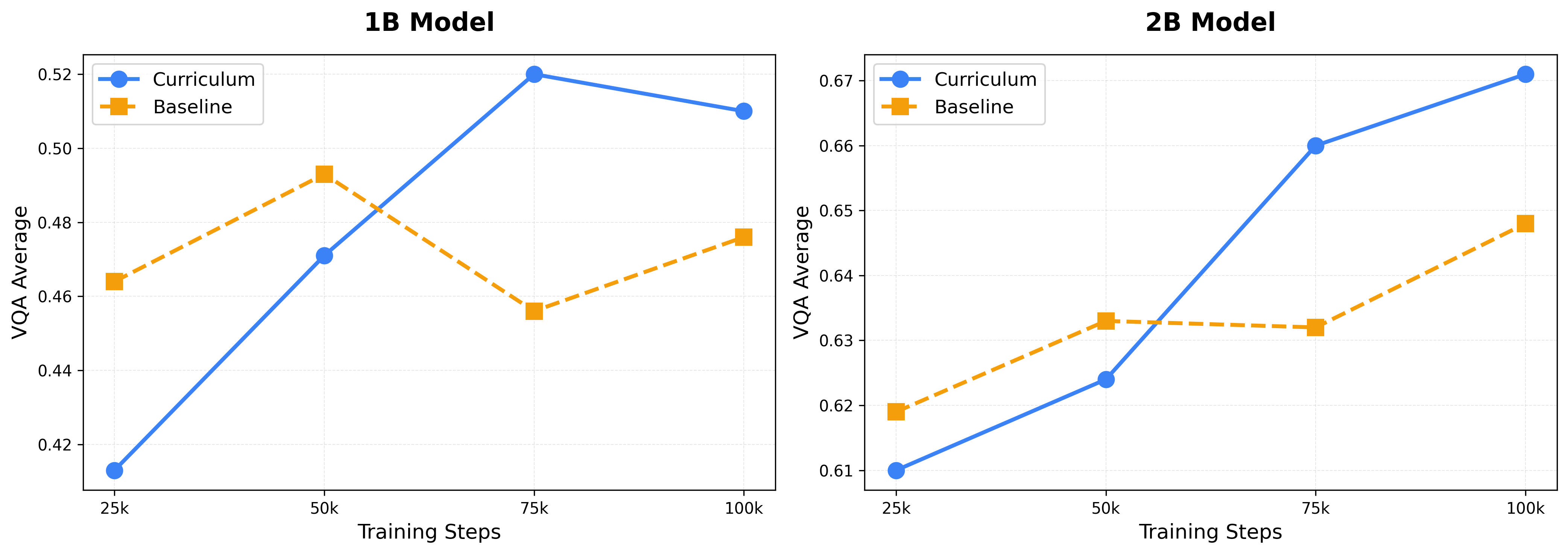
SkillRater在20亿参数的视觉语言模型上进行了验证,结果表明,在视觉理解能力上提升了5.63%,在OCR能力上提升了2.00%,在STEM推理能力上提升了3.53%。这些结果表明,SkillRater能够有效提升模型在各个能力上的表现,并且优于未经过滤的训练和单一的学习过滤方法。学习到的评分器信号是近乎正交的,验证了解耦的有效性。
🎯 应用场景
SkillRater可应用于各种视觉语言模型的训练,尤其是在需要模型具备多种不同能力的场景下。例如,可以用于训练能够理解复杂文档、进行科学推理或处理多语言文本的模型。该方法能够有效提升模型在各个能力上的表现,从而提高模型的整体性能和泛化能力。未来,SkillRater可以扩展到其他模态的数据,例如音频和视频,从而构建更强大的多模态学习系统。
📄 摘要(原文)
Data curation methods typically assign samples a single quality score. We argue this scalar framing is fundamentally limited: when training requires multiple distinct capabilities, a monolithic scorer cannot maximize useful signals for all of them simultaneously. Quality is better understood as multidimensional, with each dimension corresponding to a capability the model must acquire. We introduce SkillRater, a framework that decomposes data filtering into specialized raters - one per capability, each trained via meta-learning on a disjoint validation objective - and composes their scores through a progressive selection rule: at each training stage, a sample is retained if any rater ranks it above a threshold that tightens over time, preserving diversity early while concentrating on high-value samples late. We validate this approach on vision language models, decomposing quality into three capability dimensions: visual understanding, OCR, and STEM reasoning. At 2B parameters, SkillRater improves over unfiltered baselines by 5.63% on visual understanding, 2.00% on OCR, and 3.53% on STEM on held out benchmarks. The learned rater signals are near orthogonal, confirming that the decomposition captures genuinely independent quality dimensions and explaining why it outperforms both unfiltered training and monolithic learned filtering.