Krause Synchronization Transformers
作者: Jingkun Liu, Yisong Yue, Max Welling, Yue Song
分类: cs.LG, cs.AI
发布日期: 2026-02-12
备注: Project page: https://jingkun-liu.github.io/krause-sync-transformers/
💡 一句话要点
提出Krause注意力机制,通过局部同步缓解Transformer中的表征坍塌问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 注意力机制 表征坍塌 局部同步 有界置信度 深度学习 序列建模
📋 核心要点
- Transformer自注意力机制易导致表征坍塌和注意力沉没,影响模型性能。
- Krause注意力机制通过局部同步替代全局混合,缓解注意力集中问题。
- 实验表明,该方法在视觉、生成和语言模型任务上均有提升,计算成本更低。
📝 摘要(中文)
Transformer中的自注意力机制依赖于全局归一化的softmax权重,导致所有token在每一层都竞争影响力。这种交互模式在深度上会引发强烈的同步动态,倾向于收敛到主导模式,这种行为与表征坍塌和注意力沉没现象有关。我们引入了Krause注意力,这是一种受有界置信度共识动态启发的注意力机制。Krause注意力用基于距离的、局部化的、选择性稀疏的交互取代了基于相似性的全局聚合,从而促进了结构化的局部同步,而不是全局混合。我们将这种行为与最近将Transformer动态建模为相互作用的粒子系统的理论联系起来,并展示了有界置信度交互如何自然地缓和注意力集中并减轻注意力沉没。将交互限制在局部邻域也将运行时复杂度从序列长度的二次方降低到线性。在视觉(CIFAR/ImageNet上的ViT)、自回归生成(MNIST/CIFAR-10)和大型语言模型(Llama/Qwen)上的实验表明,在计算量大幅减少的情况下,性能得到了持续提升,突出了有界置信度动态作为一种可扩展且有效的注意力归纳偏置。
🔬 方法详解
问题定义:Transformer中的自注意力机制采用全局softmax权重,使得所有token竞争注意力资源,导致表征坍塌(representation collapse)和注意力沉没(attention sink)问题。这些问题限制了模型的表达能力和泛化性能,尤其是在深层Transformer中更为显著。现有方法通常采用正则化或dropout等手段来缓解,但效果有限,且缺乏理论支撑。
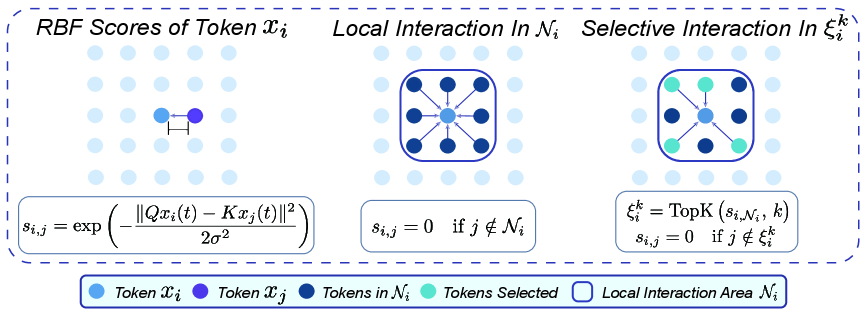
核心思路:Krause注意力机制的核心思想是借鉴有界置信度共识动态(bounded-confidence consensus dynamics),用局部交互代替全局交互。具体来说,每个token只关注与其距离在一定范围内的其他token,避免了全局竞争,促进了局部同步。这种局部交互方式可以有效缓解注意力集中问题,防止模型过早收敛到单一模式。
技术框架:Krause注意力机制替换了标准Transformer中的自注意力模块。其主要流程如下:1) 计算token之间的距离(例如,欧氏距离);2) 根据距离设定一个阈值,只有距离小于阈值的token才进行交互;3) 对选定的token计算注意力权重,并进行加权聚合。整个过程无需全局softmax归一化,而是采用局部归一化或直接使用距离作为权重。
关键创新:Krause注意力机制的关键创新在于引入了有界置信度共识动态到Transformer的注意力机制中。与传统的全局注意力机制相比,Krause注意力机制具有以下本质区别:1) 局部性:只关注局部邻域内的token;2) 选择性:根据距离选择参与交互的token;3) 非全局归一化:避免了全局竞争,促进了局部同步。
关键设计:Krause注意力机制的关键设计包括:1) 距离度量方式的选择(欧氏距离、余弦距离等);2) 距离阈值的设定(固定值或自适应学习);3) 注意力权重的计算方式(基于距离的线性或非线性函数);4) 局部归一化的方式(例如,对邻域内的权重进行归一化)。论文中可能还涉及一些超参数的调整,例如邻域大小、权重函数的参数等。
🖼️ 关键图片

📊 实验亮点
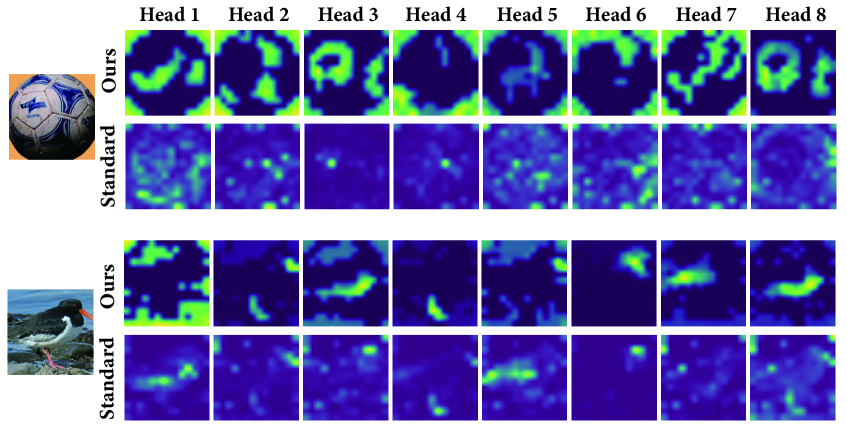
实验结果表明,Krause注意力机制在多个任务上取得了显著的性能提升。例如,在CIFAR/ImageNet上的ViT模型中,使用Krause注意力机制可以提高分类精度,同时降低计算成本。在MNIST/CIFAR-10上的自回归生成任务中,使用Krause注意力机制可以生成更高质量的图像。在Llama/Qwen等大型语言模型中,使用Krause注意力机制可以提高模型的生成能力和理解能力,同时减少计算资源消耗。具体性能数据和提升幅度需要在论文中查找。
🎯 应用场景
Krause注意力机制具有广泛的应用前景,可以应用于各种需要处理长序列数据的任务中,例如自然语言处理、计算机视觉、语音识别等。尤其是在需要关注局部信息、避免全局竞争的场景下,Krause注意力机制可以发挥更大的优势。例如,在图像分割任务中,可以利用Krause注意力机制关注像素之间的局部关系,提高分割精度。在机器翻译任务中,可以利用Krause注意力机制关注源语言和目标语言之间的局部对应关系,提高翻译质量。
📄 摘要(原文)
Self-attention in Transformers relies on globally normalized softmax weights, causing all tokens to compete for influence at every layer. When composed across depth, this interaction pattern induces strong synchronization dynamics that favor convergence toward a dominant mode, a behavior associated with representation collapse and attention sink phenomena. We introduce Krause Attention, a principled attention mechanism inspired by bounded-confidence consensus dynamics. Krause Attention replaces similarity-based global aggregation with distance-based, localized, and selectively sparse interactions, promoting structured local synchronization instead of global mixing. We relate this behavior to recent theory modeling Transformer dynamics as interacting particle systems, and show how bounded-confidence interactions naturally moderate attention concentration and alleviate attention sinks. Restricting interactions to local neighborhoods also reduces runtime complexity from quadratic to linear in sequence length. Experiments across vision (ViT on CIFAR/ImageNet), autoregressive generation (MNIST/CIFAR-10), and large language models (Llama/Qwen) demonstrate consistent gains with substantially reduced computation, highlighting bounded-confidence dynamics as a scalable and effective inductive bias for attention.