PASCAL: A Phase-Aware Scheduling Algorithm for Serving Reasoning-based Large Language Models
作者: Eunyeong Cho, Jehyeon Bang, Ranggi Hwang, Minsoo Rhu
分类: cs.LG, cs.AR
发布日期: 2026-02-12
备注: Accepted for publication at the 32nd IEEE International Symposium on High-Performance Computer Architecture (HPCA-32), 2026
💡 一句话要点
PASCAL:一种面向推理型大语言模型的阶段感知调度算法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理服务 调度算法 阶段感知 首个token生成时间 服务质量 GPU资源管理
📋 核心要点
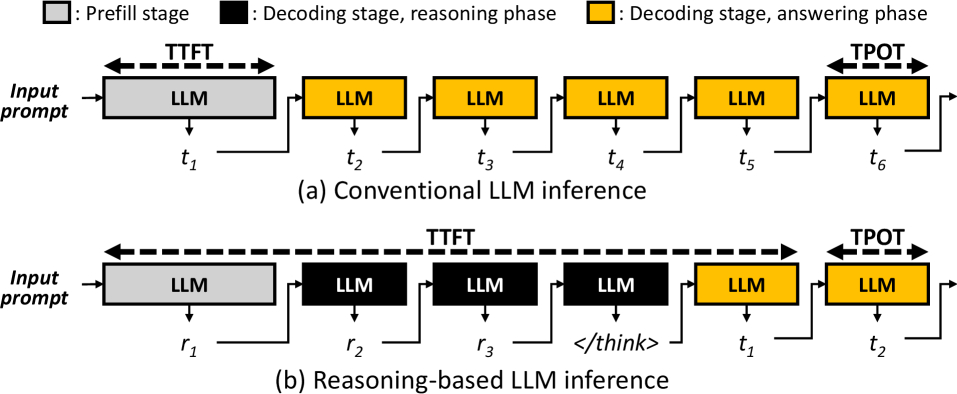
- 推理型LLM的推理阶段延长导致TTFT增加,现有框架未能区分推理和回答阶段,GPU内存受限时性能下降。
- PASCAL算法优先调度推理阶段以减少TTFT,并在回答阶段采用受控抢占和token步调以保证用户体验。
- 实验表明,PASCAL能显著降低尾部TTFT,同时维持回答阶段的服务质量,验证了阶段感知调度的有效性。
📝 摘要(中文)
随着基于思维链(CoT)推理的推理型大语言模型的出现,其扩展的推理阶段延迟了用户可见的输出并增加了首个token生成时间(TTFT),从而带来了新的服务挑战。现有的LLM服务框架未能区分推理和回答阶段,导致在GPU内存约束下性能下降。我们提出了PASCAL,一种阶段感知的调度算法,它优先考虑推理以减少TTFT,同时在回答期间使用受控的抢占和token步调来保持体验质量(QoE)。我们的分层调度器将实例级放置与实例内执行相结合,并支持在阶段边界进行动态迁移,以平衡负载并减少干扰。在使用DeepSeek-R1-Distill-Qwen-32B的基准测试中,PASCAL将尾部TTFT降低了高达72%,同时保持了回答阶段的服务水平目标(SLO)的达成,证明了阶段感知调度对于推理型LLM部署的重要性。
🔬 方法详解
问题定义:论文旨在解决推理型大语言模型(LLM)服务中的性能瓶颈,尤其是在GPU内存受限的情况下。现有LLM服务框架无法区分推理阶段和回答阶段,导致推理阶段的延迟直接影响用户体验,表现为首个token生成时间(TTFT)过长。这种延迟对于需要复杂推理的LLM应用尤为明显,现有方法无法有效优化。
核心思路:PASCAL的核心思路是采用阶段感知的调度策略,区分LLM的推理阶段和回答阶段,并针对性地进行优化。通过优先调度推理阶段,可以尽快生成首个token,从而降低TTFT,提升用户体验。同时,在回答阶段,通过受控的抢占和token步调,避免因过度优化推理阶段而影响回答阶段的性能。
技术框架:PASCAL采用分层调度器架构,包含实例级放置和实例内执行两个层次。实例级放置负责将请求分配到不同的GPU实例上,以实现负载均衡。实例内执行则负责在单个GPU实例上调度请求的执行顺序,区分推理阶段和回答阶段,并采用不同的调度策略。此外,PASCAL还支持在阶段边界进行动态迁移,允许将请求从一个GPU实例迁移到另一个GPU实例,以进一步优化负载均衡和资源利用率。
关键创新:PASCAL的关键创新在于其阶段感知的调度策略。与现有方法不同,PASCAL能够区分LLM的推理阶段和回答阶段,并针对性地进行优化。这种阶段感知的能力使得PASCAL能够更有效地利用GPU资源,降低TTFT,并提升用户体验。此外,PASCAL的分层调度器架构和动态迁移机制也为实现高效的LLM服务提供了灵活的手段。
关键设计:PASCAL的关键设计包括:1) 推理阶段优先调度策略,确保推理任务尽快完成;2) 回答阶段的受控抢占机制,避免过度抢占导致回答延迟;3) Token步调机制,平滑输出token,提升用户体验;4) 动态迁移策略,根据GPU负载动态调整任务分配。具体参数设置和损失函数细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PASCAL在DeepSeek-R1-Distill-Qwen-32B模型上,将尾部TTFT降低了高达72%,同时保持了回答阶段的服务水平目标(SLO)的达成。这表明PASCAL能够有效优化推理型LLM的服务性能,提升用户体验,验证了阶段感知调度策略的有效性。具体的基线对比和详细的实验设置未知。
🎯 应用场景
PASCAL适用于需要复杂推理的大语言模型服务场景,例如智能客服、问答系统、代码生成等。通过降低TTFT,提升用户体验,并提高GPU资源利用率,降低服务成本。未来可应用于更大规模、更复杂的LLM部署,并与其他优化技术(如模型压缩、量化)相结合,进一步提升性能。
📄 摘要(原文)
The emergence of reasoning-based LLMs leveraging Chain-of-Thought (CoT) inference introduces new serving challenges, as their extended reasoning phases delay user-visible output and inflate Time-To-First-Token (TTFT). Existing LLM serving frameworks fail to distinguish between reasoning and answering phases, leading to performance degradation under GPU memory constraints. We present PASCAL, a phase-aware scheduling algorithm that prioritizes reasoning to reduce TTFT while using controlled preemption and token pacing during answering to preserve Quality-of-Experience (QoE). Our hierarchical scheduler combines instance-level placement with intra-instance execution and enables dynamic migration at phase boundaries to balance load and reduce interference. Across benchmarks using DeepSeek-R1-Distill-Qwen-32B, PASCAL reduces tail TTFT by up to 72% while maintaining answering phase SLO attainment, demonstrating the importance of phase-aware scheduling for reasoning-based LLM deployment.