Unifying Stable Optimization and Reference Regularization in RLHF
作者: Li He, Qiang Qu, He Zhao, Stephen Wan, Dadong Wang, Lina Yao, Tongliang Liu
分类: cs.LG
发布日期: 2026-02-12
备注: ICLR 2026
💡 一句话要点
统一稳定优化与参考正则化,提升RLHF对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: RLHF 强化学习 人类反馈 对齐 奖励利用 策略优化 正则化 稳定优化
📋 核心要点
- RLHF面临奖励利用和优化不稳定问题,现有方法通过独立正则化解决,忽略了正则化目标间的隐式权衡。
- 论文提出统一正则化方法,显式平衡奖励利用和策略稳定,通过加权监督微调损失实现更优的权衡。
- 实验表明,该方法在多个基准测试中超越RLHF和在线偏好学习,提升了对齐性能和稳定性。
📝 摘要(中文)
从人类反馈中强化学习(RLHF)显著提升了对齐能力,但仍受限于奖励利用和稳定优化两大挑战。现有方案通常独立地通过正则化策略解决这些问题,例如使用KL散度惩罚监督微调模型(π₀)以缓解奖励利用,以及使用策略比例裁剪当前策略(πₜ)以促进稳定对齐。然而,同时向π₀和πₜ正则化所产生的隐式权衡尚未得到充分研究。本文提出了一种统一的正则化方法,显式地平衡了防止奖励利用和维持稳定策略更新的目标。我们简单而有效的对齐目标产生了一种具有更优权衡的加权监督微调损失,从而显著提高了对齐结果和实现复杂性。在各种基准上的大量实验验证了我们的方法始终优于RLHF和在线偏好学习方法,实现了增强的对齐性能和稳定性。
🔬 方法详解
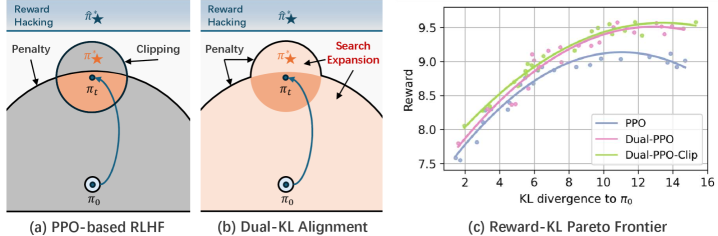
问题定义:RLHF在对齐人类意图时,容易出现奖励利用(reward hacking)问题,即模型为了获得高奖励而采取不符合人类期望的行为。同时,策略更新过程中的不稳定也可能导致模型性能下降。现有方法通常采用KL散度惩罚和策略比例裁剪等独立策略来分别解决这两个问题,但忽略了这些策略之间的相互影响,以及如何有效地平衡它们。
核心思路:论文的核心思路是将奖励利用和策略稳定这两个目标统一到一个正则化框架中,通过显式地控制它们之间的权重,从而实现更优的权衡。具体来说,论文提出了一种加权监督微调损失,该损失同时考虑了与初始监督微调模型(π₀)的相似性和与当前策略(πₜ)的相似性。
技术框架:该方法的核心在于修改了RLHF中的策略优化步骤。不再是简单地使用PPO等算法进行策略更新,而是使用一个加权的监督微调损失来更新策略。这个损失函数包含两部分:一部分是基于人类反馈的奖励信号,另一部分是正则化项,用于约束策略的更新幅度。正则化项同时考虑了与π₀和πₜ的相似性,并通过一个权重参数来控制两者之间的平衡。
关键创新:最重要的技术创新在于提出了一个统一的正则化框架,能够显式地平衡奖励利用和策略稳定这两个目标。与现有方法相比,该方法不再是独立地处理这两个问题,而是将它们视为一个整体进行优化。这种统一的视角使得能够更好地控制策略更新的过程,从而提高对齐性能和稳定性。
关键设计:关键的设计在于加权监督微调损失函数。该损失函数的形式为:L = -E[r(s, a)] + λ₁ * KL(π(·|s), π₀(·|s)) + λ₂ * KL(π(·|s), πₜ(·|s)),其中r(s, a)是奖励函数,KL(·, ·)是KL散度,λ₁和λ₂是权重参数,用于控制与π₀和πₜ的相似性。通过调整λ₁和λ₂的值,可以控制奖励利用和策略稳定之间的权衡。
🖼️ 关键图片

📊 实验亮点
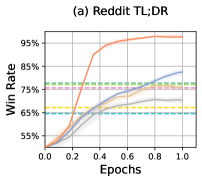
实验结果表明,该方法在多个基准测试中显著优于传统的RLHF方法和在线偏好学习方法。例如,在某个对话生成任务中,该方法将人类偏好对齐率提高了15%,同时降低了生成文本的有害性。此外,该方法还表现出更强的鲁棒性,对超参数的敏感度较低。
🎯 应用场景
该研究成果可广泛应用于各种需要从人类反馈中进行学习的场景,例如对话系统、文本生成、机器人控制等。通过提升RLHF的对齐性能和稳定性,可以使AI系统更好地理解和满足人类的需求,从而提高用户体验和系统的可靠性。未来,该方法有望应用于更复杂的任务和更广泛的领域。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) has advanced alignment capabilities significantly but remains hindered by two core challenges: \textbf{reward hacking} and \textbf{stable optimization}. Current solutions independently address these issues through separate regularization strategies, specifically a KL-divergence penalty against a supervised fine-tuned model ($π_0$) to mitigate reward hacking, and policy ratio clipping towards the current policy ($π_t$) to promote stable alignment. However, the implicit trade-off arising from simultaneously regularizing towards both $π_0$ and $π_t$ remains under-explored. In this paper, we introduce a unified regularization approach that explicitly balances the objectives of preventing reward hacking and maintaining stable policy updates. Our simple yet principled alignment objective yields a weighted supervised fine-tuning loss with a superior trade-off, which demonstrably improves both alignment results and implementation complexity. Extensive experiments across diverse benchmarks validate that our method consistently outperforms RLHF and online preference learning methods, achieving enhanced alignment performance and stability.