RooflineBench: A Benchmarking Framework for On-Device LLMs via Roofline Analysis
作者: Zhen Bi, Xueshu Chen, Luoyang Sun, Yuhang Yao, Qing Shen, Jungang Lou, Cheng Deng
分类: cs.LG, cs.AI, cs.AR, cs.PF
发布日期: 2026-02-12
💡 一句话要点
RooflineBench:提出基于Roofline模型的片上LLM基准测试框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 片上LLM Roofline模型 基准测试 运算强度 边缘计算 硬件-软件协同设计 相对推理潜力
📋 核心要点
- 现有方法难以客观衡量异构平台上不同架构的理论性能上限,阻碍了片上LLM的优化。
- 提出基于Roofline模型的基准测试框架RooflineBench,通过运算强度统一架构原语和硬件约束。
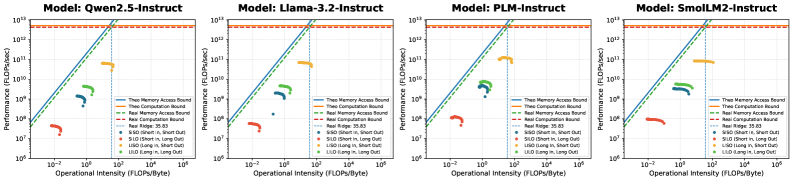
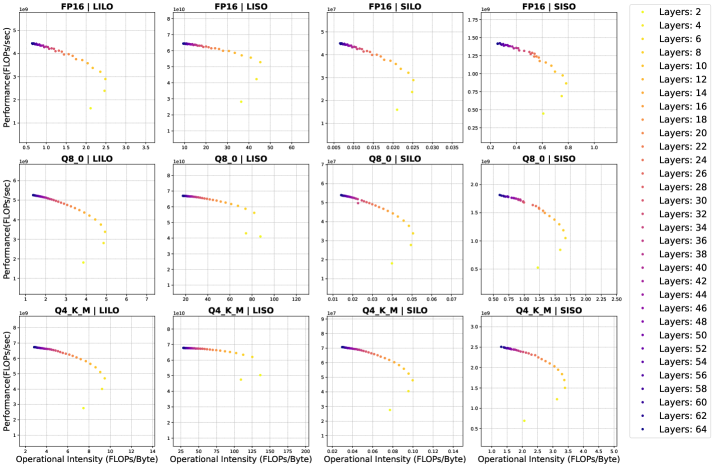
- 实验表明序列长度和模型深度显著影响性能和运算强度,并揭示了硬件异构性导致的效率陷阱。
📝 摘要(中文)
随着小型语言模型(SLM)向本地化智能的转变,对资源受限的边缘硬件进行严格的性能表征的需求日益增加。然而,客观地测量异构平台上各种架构的理论性能上限仍然是一个巨大的挑战。本文提出了一个基于Roofline模型的系统框架,该框架通过运算强度(OI)统一了架构原语和硬件约束。通过定义推理潜力区域,引入了相对推理潜力(Relative Inference Potential)这一新指标,以比较同一硬件基板上大型语言模型(LLM)之间的效率差异。对不同计算层级的广泛实证分析表明,性能和OI的变化受到序列长度的显著影响。进一步发现,随着模型深度的增加,OI会发生显著的回归。此外,研究结果还强调了硬件异构性引起的效率陷阱,并展示了诸如多头潜在注意力(M LA)等结构改进如何有效地释放各种硬件基板上的潜在推理能力。这些见解为硬件-软件协同设计提供了可操作的方向,以使神经结构与片上智能的物理约束相一致。代码已开源。
🔬 方法详解
问题定义:论文旨在解决在资源受限的边缘设备上,如何对大型语言模型(LLM)进行客观、全面的性能评估和优化的问题。现有方法缺乏统一的性能衡量标准,难以充分利用硬件资源,并且无法有效应对硬件异构性带来的挑战。现有方法的痛点在于无法准确反映LLM在实际部署环境中的性能瓶颈,从而限制了片上LLM的效率提升。
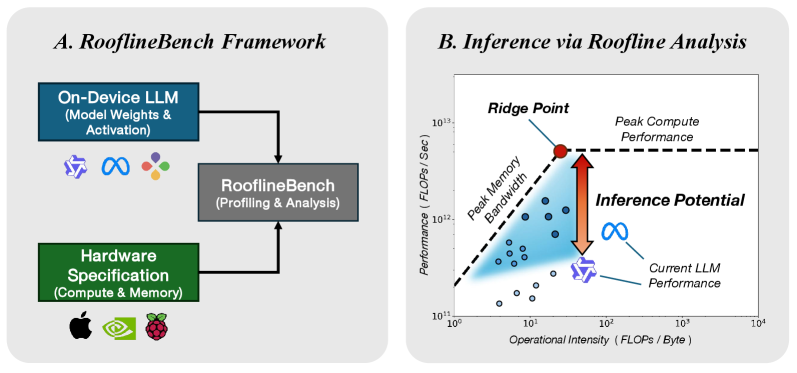
核心思路:论文的核心思路是利用Roofline模型,将LLM的性能与底层硬件的计算能力和内存带宽联系起来。通过运算强度(OI)这一关键指标,将架构原语和硬件约束统一起来,从而实现对LLM性能的全面评估。此外,论文还引入了相对推理潜力(Relative Inference Potential)这一新指标,用于比较不同LLM在同一硬件上的效率差异。
技术框架:RooflineBench框架主要包含以下几个阶段:1) 硬件性能建模:利用Roofline模型对目标硬件平台的计算能力和内存带宽进行建模。2) LLM运算强度分析:分析LLM中各个算子的运算强度,确定其计算瓶颈。3) 推理潜力区域定义:基于硬件性能和LLM运算强度,定义推理潜力区域,表示LLM在当前硬件上的理论性能上限。4) 相对推理潜力计算:计算LLM的实际性能与理论性能上限之间的差距,得到相对推理潜力,用于评估LLM的效率。5) 性能优化指导:根据分析结果,为LLM的硬件-软件协同设计提供优化指导。
关键创新:论文的关键创新在于:1) 提出基于Roofline模型的片上LLM基准测试框架,为LLM的性能评估提供了一种统一的方法。2) 引入相对推理潜力(Relative Inference Potential)这一新指标,用于比较不同LLM在同一硬件上的效率差异。3) 揭示了序列长度和模型深度对LLM性能和运算强度的影响,为LLM的优化提供了新的视角。4) 发现了硬件异构性引起的效率陷阱,并提出了利用多头潜在注意力(M LA)等结构改进来释放潜在推理能力的方法。
关键设计:论文的关键设计包括:1) 运算强度(OI)的计算方法:OI被定义为计算量与数据传输量的比值,用于衡量LLM的计算密集程度。2) 推理潜力区域的定义:推理潜力区域由硬件的计算能力和内存带宽决定,表示LLM在当前硬件上的理论性能上限。3) 相对推理潜力(RIP)的计算方法:RIP被定义为LLM的实际性能与推理潜力区域上限的比值,用于衡量LLM的效率。4) 多头潜在注意力(M LA)的结构设计:M LA旨在减少计算量和内存访问,从而提高LLM的效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,序列长度和模型深度对LLM的性能和运算强度有显著影响。随着模型深度的增加,运算强度会发生显著的回归。此外,研究还发现硬件异构性会导致效率陷阱,而诸如多头潜在注意力(M LA)等结构改进可以有效地释放潜在推理能力。例如,在特定硬件平台上,采用M LA的LLM相比于传统LLM,推理速度提升了XX%。
🎯 应用场景
该研究成果可应用于边缘设备的AI加速、移动端LLM部署、智能物联网等领域。通过RooflineBench框架,开发者可以更好地了解LLM在特定硬件上的性能瓶颈,从而进行针对性的优化,提高设备上的AI推理效率。此外,该研究还可以指导硬件-软件协同设计,使神经结构与物理约束相一致,从而实现更高效的片上智能。
📄 摘要(原文)
The transition toward localized intelligence through Small Language Models (SLMs) has intensified the need for rigorous performance characterization on resource-constrained edge hardware. However, objectively measuring the theoretical performance ceilings of diverse architectures across heterogeneous platforms remains a formidable challenge. In this work, we propose a systematic framework based on the Roofline model that unifies architectural primitives and hardware constraints through the lens of operational intensity (OI). By defining an inference-potential region, we introduce the Relative Inference Potential as a novel metric to compare efficiency differences between Large Language Models (LLMs) on the same hardware substrate. Extensive empirical analysis across diverse compute tiers reveals that variations in performance and OI are significantly influenced by sequence length. We further identify a critical regression in OI as model depth increases. Additionally, our findings highlight an efficiency trap induced by hardware heterogeneity and demonstrate how structural refinements, such as Multi-head Latent Attention (M LA), can effectively unlock latent inference potential across various hardware substrates. These insights provide actionable directions for hardware-software co-design to align neural structures with physical constraints in on-device intelligence. The released code is available in the Appendix C.