TabICLv2: A better, faster, scalable, and open tabular foundation model
作者: Jingang Qu, David Holzmüller, Gaël Varoquaux, Marine Le Morvan
分类: cs.LG
发布日期: 2026-02-11
🔗 代码/项目: GITHUB
💡 一句话要点
TabICLv2:一种更优、更快、可扩展且开放的表格数据基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据建模 基础模型 上下文学习 合成数据生成 可扩展注意力 Muon优化器 预训练 泛化能力
📋 核心要点
- 现有表格数据模型在处理大规模数据集时,泛化能力和训练效率面临挑战,需要更高效的预训练和模型架构。
- TabICLv2通过创新的合成数据生成、可扩展的softmax注意力机制和优化的预训练协议,提升模型性能和泛化能力。
- 实验表明,TabICLv2在TabArena和TALENT基准测试中超越了现有最佳模型,且计算效率更高,适用于更大规模的数据集。
📝 摘要(中文)
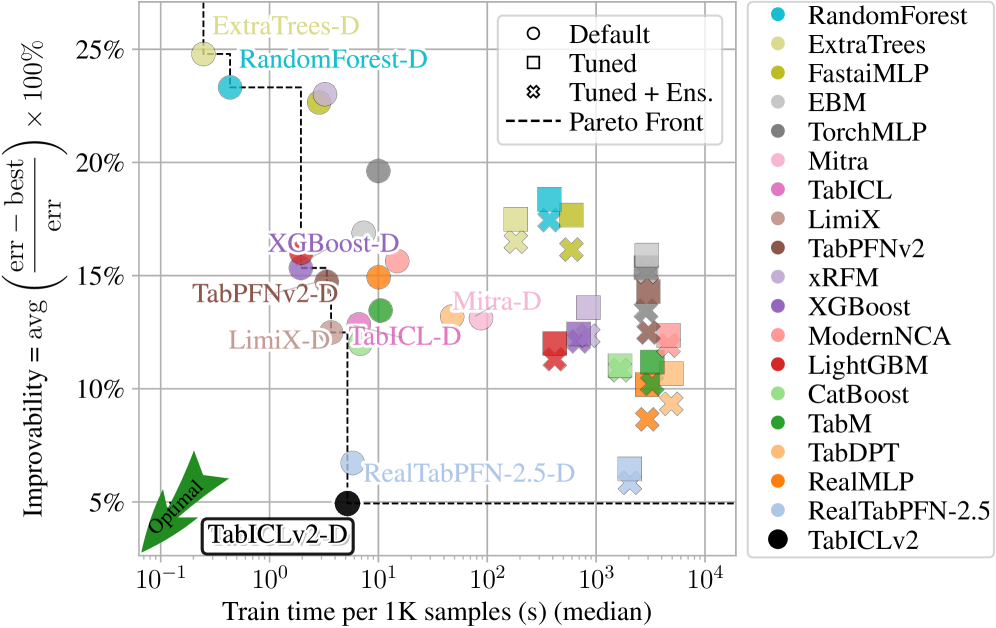
本文提出TabICLv2,一种用于回归和分类的先进表格数据基础模型。该模型基于三个关键要素:(1) 为高预训练多样性设计的新型合成数据生成引擎;(2) 多项架构创新,包括一种新的可扩展softmax注意力机制,可在不进行过长序列预训练的情况下,提高对更大数据集的泛化能力;(3) 优化的预训练协议,特别是用Muon优化器取代AdamW。在TabArena和TALENT基准测试中,未经任何调整的TabICLv2超越了当前最先进的RealTabPFN-2.5(经过超参数调整、集成和在真实数据上微调)。TabICLv2仅需适度的预训练计算量,即可在50GB GPU内存下有效地泛化到百万级数据集,同时比RealTabPFN-2.5更快。论文提供了广泛的消融研究来量化这些贡献,并承诺开放研究,首先在https://github.com/soda-inria/tabicl发布推理代码和模型权重,随后发布合成数据引擎和预训练代码。
🔬 方法详解
问题定义:表格数据建模旨在从结构化数据中学习预测模型。现有方法,如梯度提升树,在小数据集上表现良好,但在大数据集上,基于上下文学习的表格基础模型(如TabPFNv2和TabICL)展现出优势。然而,这些模型仍然面临着泛化能力、训练效率和计算资源消耗等问题,尤其是在处理百万级别的数据集时。
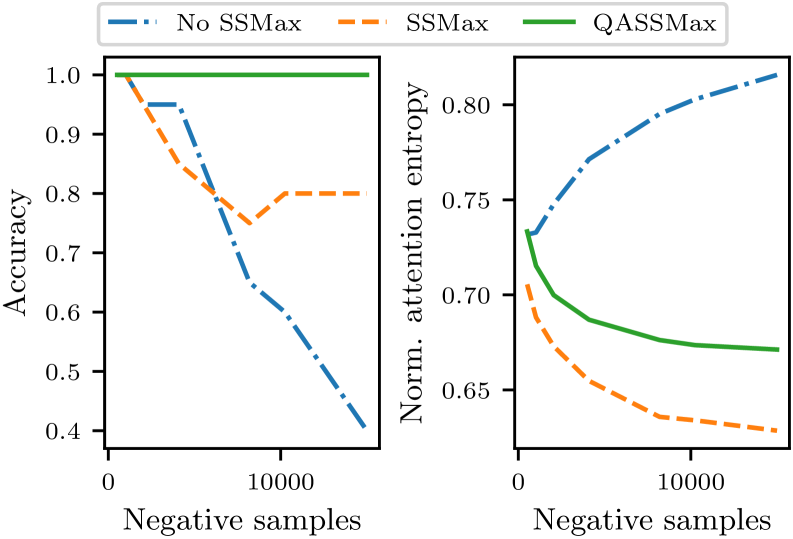
核心思路:TabICLv2的核心思路是通过改进合成数据生成、优化模型架构和预训练策略,提升表格数据基础模型的性能和效率。具体来说,通过生成更多样化的合成数据来增强模型的泛化能力,采用可扩展的softmax注意力机制来降低计算复杂度,并使用更高效的优化器来加速预训练过程。
技术框架:TabICLv2的整体框架包括三个主要组成部分:(1) 合成数据生成引擎,用于生成多样化的训练数据;(2) 基于Transformer的模型架构,采用可扩展的softmax注意力机制;(3) 优化的预训练协议,包括使用Muon优化器和特定的训练策略。模型首先在合成数据上进行预训练,然后可以应用于各种表格数据任务。
关键创新:TabICLv2的关键创新在于以下几个方面:(1) 新型合成数据生成引擎,能够生成更具多样性和挑战性的训练数据,从而提高模型的泛化能力;(2) 可扩展的softmax注意力机制,降低了计算复杂度,使得模型能够处理更大规模的数据集;(3) 使用Muon优化器替代AdamW,加速了预训练过程并提高了模型性能。
关键设计:在合成数据生成方面,论文设计了一种新的策略来生成具有不同特征和分布的数据。在模型架构方面,可扩展的softmax注意力机制通过某种近似或分解方法来降低计算复杂度,具体实现细节未知。在预训练方面,Muon优化器的具体参数设置和训练策略也未知,但其目标是加速收敛并提高模型性能。
🖼️ 关键图片

📊 实验亮点
TabICLv2在TabArena和TALENT基准测试中,无需任何调整即超越了当前最先进的RealTabPFN-2.5,后者经过了超参数调整、集成和真实数据微调。此外,TabICLv2在50GB GPU内存下,能够有效地泛化到百万级数据集,并且比RealTabPFN-2.5更快,展示了其优越的性能和效率。
🎯 应用场景
TabICLv2可广泛应用于金融、医疗、电商等领域,解决分类、回归等预测问题。其高效性和泛化能力使其能够处理大规模表格数据,为企业提供更准确的决策支持。未来,该模型有望成为表格数据分析的标准工具,推动相关领域的发展。
📄 摘要(原文)
Tabular foundation models, such as TabPFNv2 and TabICL, have recently dethroned gradient-boosted trees at the top of predictive benchmarks, demonstrating the value of in-context learning for tabular data. We introduce TabICLv2, a new state-of-the-art foundation model for regression and classification built on three pillars: (1) a novel synthetic data generation engine designed for high pretraining diversity; (2) various architectural innovations, including a new scalable softmax in attention improving generalization to larger datasets without prohibitive long-sequence pretraining; and (3) optimized pretraining protocols, notably replacing AdamW with the Muon optimizer. On the TabArena and TALENT benchmarks, TabICLv2 without any tuning surpasses the performance of the current state of the art, RealTabPFN-2.5 (hyperparameter-tuned, ensembled, and fine-tuned on real data). With only moderate pretraining compute, TabICLv2 generalizes effectively to million-scale datasets under 50GB GPU memory while being markedly faster than RealTabPFN-2.5. We provide extensive ablation studies to quantify these contributions and commit to open research by first releasing inference code and model weights at https://github.com/soda-inria/tabicl, with synthetic data engine and pretraining code to follow.