Weight Decay Improves Language Model Plasticity
作者: Tessa Han, Sebastian Bordt, Hanlin Zhang, Sham Kakade
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-11
💡 一句话要点
通过调整权重衰减提升语言模型的可塑性,增强下游任务微调性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 权重衰减 模型可塑性 预训练 微调 超参数优化 泛化能力
📋 核心要点
- 现有LLM研究主要关注预训练阶段的验证损失,忽略了模型在下游任务中的适应能力,即模型的可塑性。
- 该研究的核心思想是通过调整预训练阶段的权重衰减,来提升基础模型的可塑性,使其更容易适应下游任务。
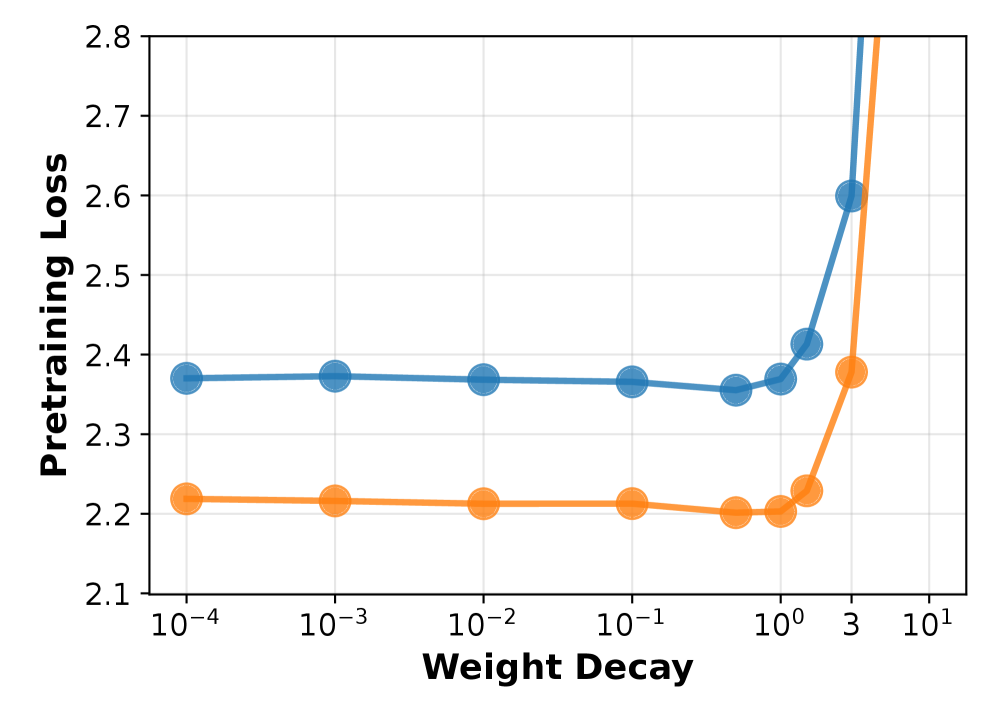
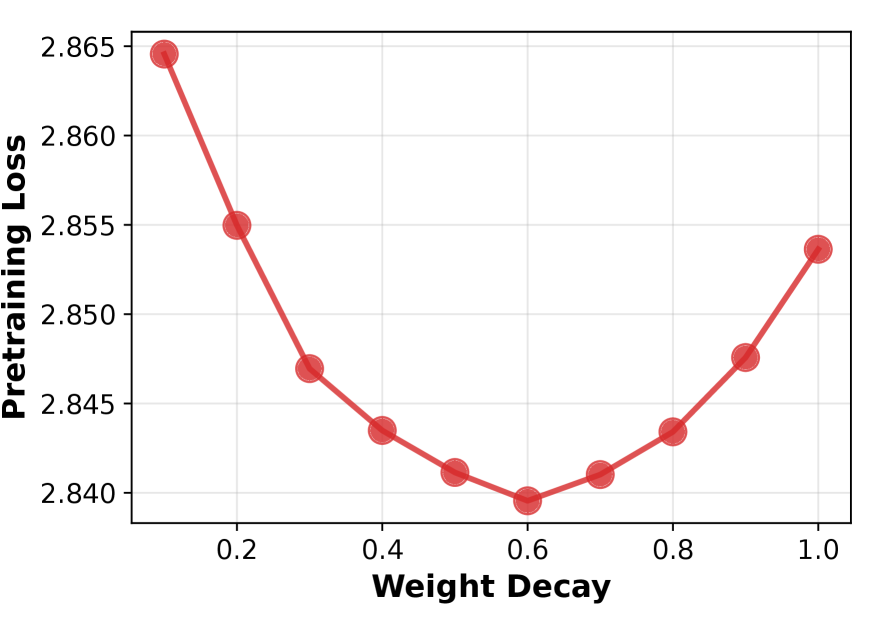
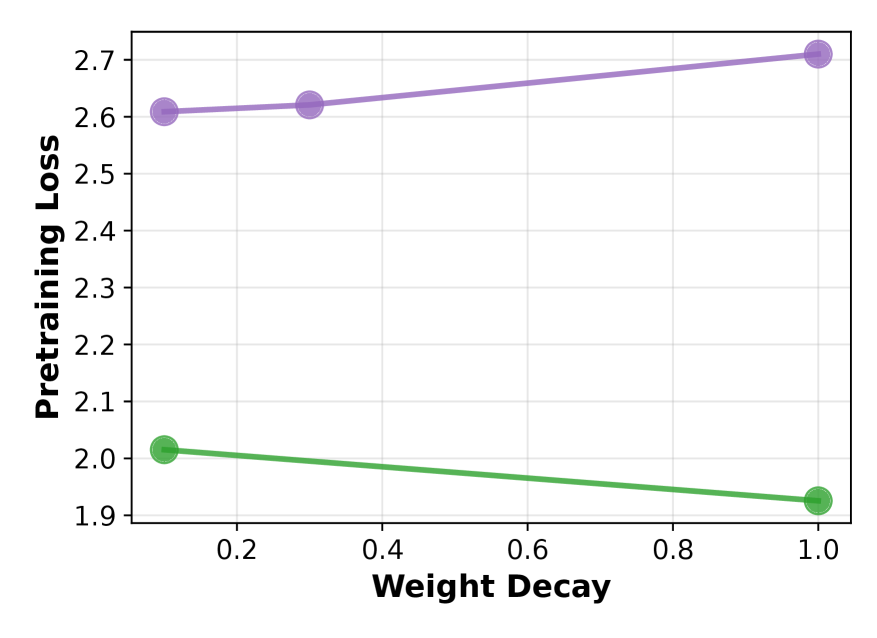
- 实验结果表明,使用较大权重衰减值训练的模型在下游任务微调后表现出更大的性能提升,验证了该方法的有效性。
📝 摘要(中文)
大型语言模型(LLM)开发的主流范式是预训练一个基础模型,然后进行进一步的训练以提高性能和模型行为。然而,超参数优化和缩放定律主要从基础模型的验证损失角度进行研究,忽略了下游适应性。本文从模型可塑性的角度研究预训练,即可塑性是指基础模型通过微调成功适应下游任务的能力。我们重点关注权重衰减的作用,权重衰减是预训练期间的关键正则化参数。通过系统的实验,我们表明,使用较大权重衰减值训练的模型更具可塑性,这意味着它们在下游任务上进行微调时表现出更大的性能提升。这种现象可能导致违反直觉的权衡,即预训练后表现较差的基础模型在微调后表现更好。对权重衰减对模型行为的机制影响的进一步研究表明,它鼓励线性可分的表示,正则化注意力矩阵,并减少对训练数据的过拟合。总之,这项工作证明了使用交叉熵损失之外的评估指标进行超参数优化的重要性,并阐明了单个优化超参数在塑造模型行为中的多方面作用。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的训练范式主要关注预训练阶段的验证损失,而忽略了模型在下游任务中的适应能力,即模型的可塑性。现有的超参数优化和缩放定律研究也主要集中在基础模型的验证损失上,缺乏对下游任务微调性能的考量。因此,如何提升基础模型的可塑性,使其更容易适应下游任务,是一个重要的研究问题。
核心思路:该论文的核心思路是通过调整预训练阶段的权重衰减(weight decay)来提升基础模型的可塑性。作者认为,适当的权重衰减可以鼓励模型学习到更具泛化能力的特征表示,从而更容易适应下游任务。具体来说,较大的权重衰减值可以防止模型过度拟合预训练数据,并鼓励模型学习到更线性可分的表示。
技术框架:该研究主要通过实验来验证权重衰减对模型可塑性的影响。具体来说,作者首先使用不同的权重衰减值预训练一系列基础语言模型,然后在不同的下游任务上对这些模型进行微调。通过比较不同权重衰减值下模型的微调性能,来评估权重衰减对模型可塑性的影响。此外,作者还对权重衰减对模型行为的机制影响进行了进一步研究,包括分析权重衰减对模型表示、注意力矩阵和过拟合程度的影响。
关键创新:该论文的关键创新在于提出了从模型可塑性的角度来研究预训练,并发现权重衰减是影响模型可塑性的一个关键因素。与以往主要关注预训练阶段验证损失的研究不同,该论文强调了模型在下游任务中的适应能力,并提供了一种通过调整权重衰减来提升模型可塑性的方法。
关键设计:该研究的关键设计包括:1) 系统地实验了不同的权重衰减值,以评估其对模型可塑性的影响;2) 使用了多个不同的下游任务,以验证该方法的泛化能力;3) 对权重衰减对模型行为的机制影响进行了深入研究,包括分析权重衰减对模型表示、注意力矩阵和过拟合程度的影响。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用较大权重衰减值训练的模型在下游任务微调后表现出更大的性能提升。具体来说,某些预训练阶段验证损失较低的模型,在微调后的性能反而不如预训练阶段验证损失较高的模型,这表明权重衰减对模型可塑性有显著影响。具体性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于大型语言模型的预训练阶段,通过调整权重衰减值,提升模型在下游任务中的微调性能。这有助于降低模型在特定任务上的训练成本,并提高模型的泛化能力,从而在自然语言处理的各个领域,如文本生成、机器翻译、问答系统等,实现更高效、更可靠的应用。
📄 摘要(原文)
The prevailing paradigm in large language model (LLM) development is to pretrain a base model, then perform further training to improve performance and model behavior. However, hyperparameter optimization and scaling laws have been studied primarily from the perspective of the base model's validation loss, ignoring downstream adaptability. In this work, we study pretraining from the perspective of model plasticity, that is, the ability of the base model to successfully adapt to downstream tasks through fine-tuning. We focus on the role of weight decay, a key regularization parameter during pretraining. Through systematic experiments, we show that models trained with larger weight decay values are more plastic, meaning they show larger performance gains when fine-tuned on downstream tasks. This phenomenon can lead to counterintuitive trade-offs where base models that perform worse after pretraining can perform better after fine-tuning. Further investigation of weight decay's mechanistic effects on model behavior reveals that it encourages linearly separable representations, regularizes attention matrices, and reduces overfitting on the training data. In conclusion, this work demonstrates the importance of using evaluation metrics beyond cross-entropy loss for hyperparameter optimization and casts light on the multifaceted role of that a single optimization hyperparameter plays in shaping model behavior.