Motion Capture is Not the Target Domain: Scaling Synthetic Data for Learning Motion Representations
作者: Firas Darwish, George Nicholson, Aiden Doherty, Hang Yuan
分类: cs.LG
发布日期: 2026-02-11
💡 一句话要点
利用合成数据扩展运动表征学习,解决可穿戴设备人体活动识别问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体活动识别 可穿戴设备 合成数据 运动表征学习 预训练
📋 核心要点
- 可穿戴设备人体活动识别(HAR)依赖大规模数据,但真实数据收集困难,合成数据预训练存在领域迁移问题。
- 利用运动捕捉数据生成合成运动数据,预训练运动时间序列模型,探索合成数据在HAR任务中的迁移能力。
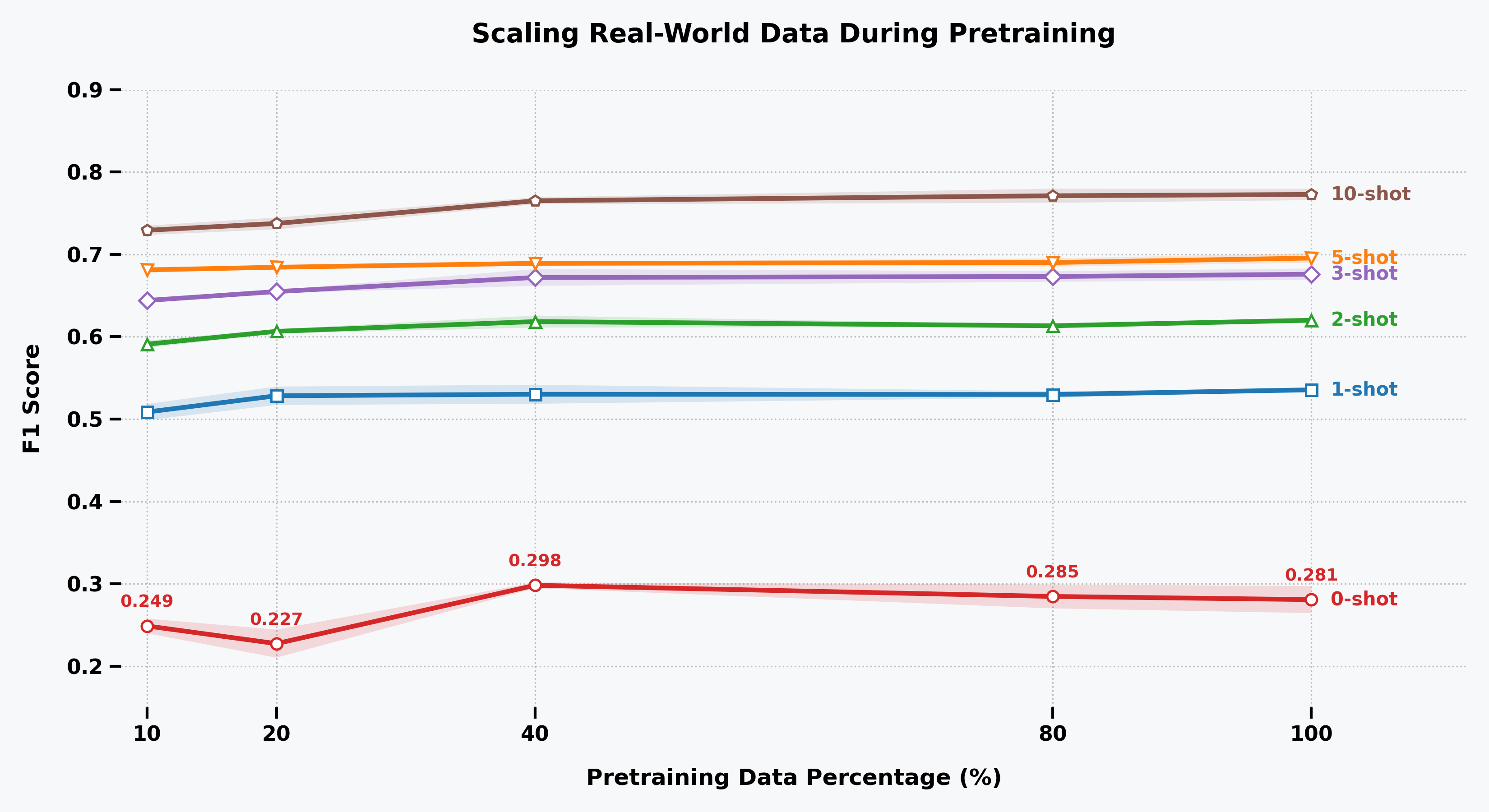
- 实验表明,混合真实数据或充分扩展合成数据可提升泛化性,大规模运动捕捉预训练收益有限,揭示了sim-to-real的挑战。
📝 摘要(中文)
当真实世界数据稀缺时,合成数据为可扩展的预训练提供了一条引人注目的路径,但使用合成数据预训练的模型通常无法可靠地迁移到部署环境中。本文研究了全身人体运动中的这个问题,在这种情况下,大规模数据收集是不可行的,但对于基于可穿戴设备的人体活动识别 (HAR) 至关重要,并且可以从运动捕捉导出的表示生成合成运动。本文使用此类合成数据预训练运动时间序列模型,并评估它们在各种下游 HAR 任务中的迁移能力。结果表明,当与真实数据混合或充分缩放时,合成预训练可以提高泛化能力。本文还证明,大规模运动捕捉预训练由于与可穿戴信号的领域不匹配而仅产生边际收益,从而阐明了关键的 sim-to-real 挑战以及合成运动数据在可迁移 HAR 表示方面的局限性和机会。
🔬 方法详解
问题定义:论文旨在解决可穿戴设备人体活动识别(HAR)中,真实数据难以获取,而直接使用运动捕捉数据进行预训练又存在领域差异的问题。现有方法要么依赖少量真实数据,要么在与可穿戴设备数据分布不同的运动捕捉数据上进行预训练,导致模型泛化能力不足。
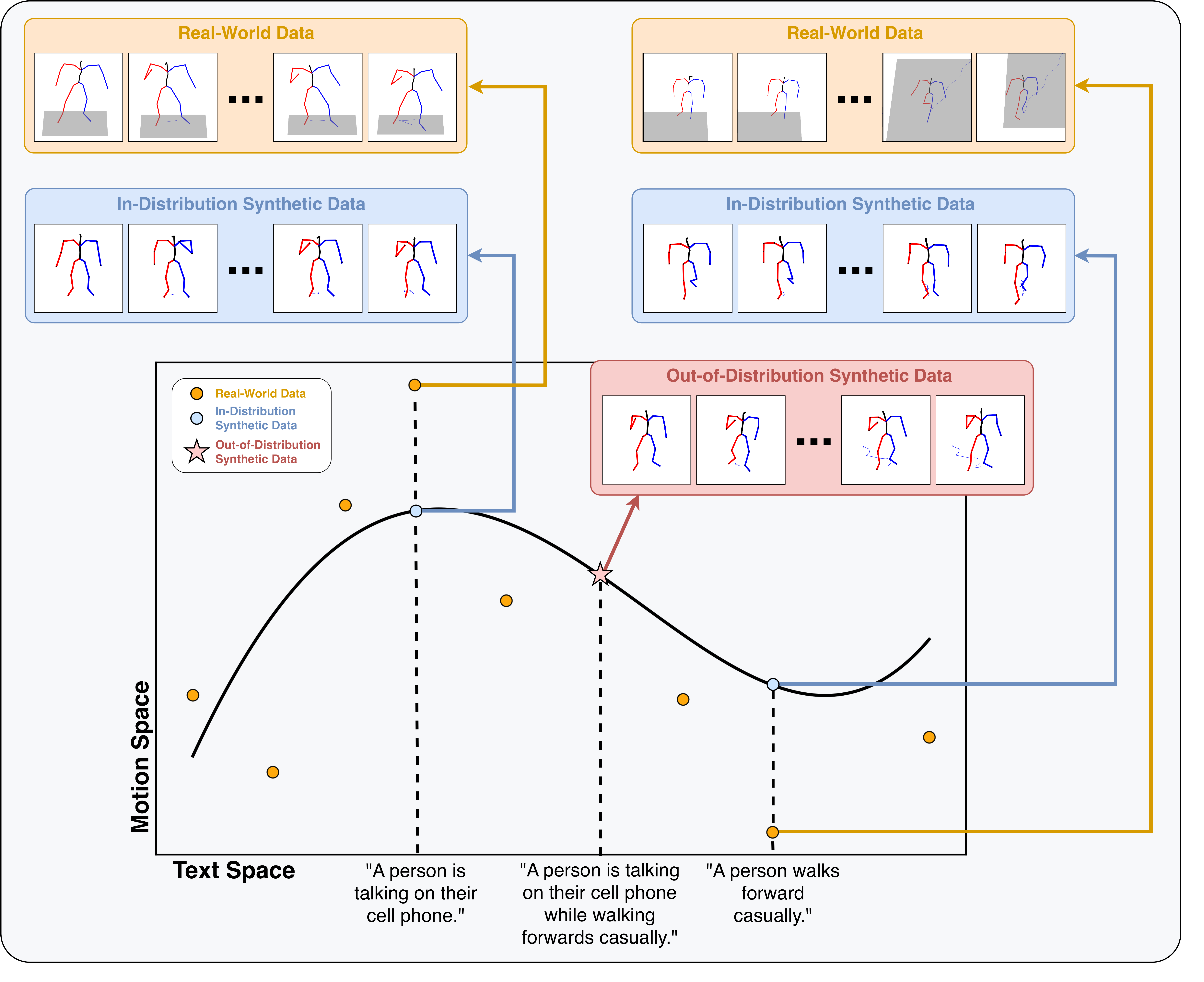
核心思路:论文的核心思路是利用运动捕捉数据生成大规模的合成运动数据,并在此基础上进行预训练。通过控制合成数据的生成过程,尽可能减小与真实可穿戴设备数据的领域差异,从而提高预训练模型在真实HAR任务上的迁移能力。同时,研究混合真实数据和合成数据进行训练的效果,以及大规模合成数据预训练的潜力。
技术框架:整体框架包含以下几个主要阶段:1) 运动捕捉数据获取:利用现有的运动捕捉数据集。2) 合成运动数据生成:基于运动捕捉数据,通过数据增强、参数调整等方式生成大规模的合成运动数据。3) 模型预训练:使用合成运动数据预训练运动时间序列模型。4) 模型微调:使用真实可穿戴设备数据在下游HAR任务上微调预训练模型。5) 评估:在不同的HAR数据集上评估模型的性能。
关键创新:论文的关键创新在于探索了利用合成运动数据进行预训练,以提高可穿戴设备HAR任务的性能。与直接使用运动捕捉数据预训练不同,论文关注如何生成更贴近真实可穿戴设备数据的合成数据,从而减小领域差异。此外,论文还研究了混合真实数据和合成数据进行训练的策略,以及大规模合成数据预训练的潜力。
关键设计:论文的关键设计包括:1) 合成数据生成策略:如何基于运动捕捉数据生成多样且真实的合成运动数据,例如,通过添加噪声、改变运动速度、组合不同的运动片段等方式。2) 预训练模型结构:选择合适的运动时间序列模型,例如,循环神经网络(RNN)、Transformer等。3) 损失函数设计:设计合适的损失函数,以鼓励模型学习到有用的运动表征。4) 混合训练策略:如何有效地混合真实数据和合成数据进行训练,例如,通过调整两种数据的比例、使用不同的学习率等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与仅使用真实数据训练的模型相比,使用合成数据预训练的模型在多个HAR数据集上取得了更好的性能。当与真实数据混合或充分扩展合成数据时,泛化能力得到显著提升。同时,实验也揭示了大规模运动捕捉预训练的局限性,表明领域差异是影响迁移性能的关键因素。
🎯 应用场景
该研究成果可应用于智能穿戴设备、健康监测、运动分析、康复训练等领域。通过利用合成数据进行预训练,可以降低对真实数据的依赖,加速模型开发,提高模型在各种场景下的泛化能力。未来,该方法有望推动可穿戴设备在更多领域的应用,例如,老年人跌倒检测、慢性病管理等。
📄 摘要(原文)
Synthetic data offers a compelling path to scalable pretraining when real-world data is scarce, but models pretrained on synthetic data often fail to transfer reliably to deployment settings. We study this problem in full-body human motion, where large-scale data collection is infeasible but essential for wearable-based Human Activity Recognition (HAR), and where synthetic motion can be generated from motion-capture-derived representations. We pretrain motion time-series models using such synthetic data and evaluate their transfer across diverse downstream HAR tasks. Our results show that synthetic pretraining improves generalisation when mixed with real data or scaled sufficiently. We also demonstrate that large-scale motion-capture pretraining yields only marginal gains due to domain mismatch with wearable signals, clarifying key sim-to-real challenges and the limits and opportunities of synthetic motion data for transferable HAR representations.