MoToRec: Sparse-Regularized Multimodal Tokenization for Cold-Start Recommendation
作者: Jialin Liu, Zhaorui Zhang, Ray C. C. Cheung
分类: cs.LG, cs.IR
发布日期: 2026-02-11
备注: Accepted to AAAI 2026 (Main Track)
💡 一句话要点
提出MoToRec,通过稀疏正则化多模态Tokenization解决冷启动推荐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 冷启动推荐 多模态学习 图神经网络 变分自编码器 离散表示 Tokenization 稀疏正则化 推荐系统
📋 核心要点
- 现有推荐系统在处理冷启动物品时,由于数据稀疏和多模态信息噪声,难以学习到有效的物品表示。
- MoToRec通过稀疏正则化的RQ-VAE将多模态信息转化为离散语义Token,学习解耦的物品表示,并采用自适应稀有性放大策略。
- 在三个大规模数据集上的实验表明,MoToRec在冷启动场景和整体性能上均优于现有方法,验证了离散Tokenization的有效性。
📝 摘要(中文)
图神经网络(GNNs)通过有效建模复杂的用户-物品交互,革新了推荐系统。然而,数据稀疏性和物品冷启动问题严重影响了性能,特别是对于交互历史有限或没有交互历史的新物品。虽然多模态内容提供了一个有希望的解决方案,但由于稀疏数据中的噪声和纠缠,现有方法导致新物品的表示次优。为了解决这个问题,我们将多模态推荐转化为离散语义Tokenization。我们提出了用于冷启动推荐的稀疏正则化多模态Tokenization (MoToRec),该框架以稀疏正则化的残差量化变分自编码器(RQ-VAE)为中心,生成离散的、可解释的Token的组合语义代码,从而促进解耦表示。MoToRec的架构通过三个协同组件得到增强:(1)一个促进解耦表示的稀疏正则化RQ-VAE,(2)一种新颖的自适应稀有性放大,促进冷启动物品的优先学习,以及(3)一个用于鲁棒信号融合的分层多源图编码器。在三个大规模数据集上的大量实验表明,MoToRec在整体和冷启动场景中都优于最先进的方法。我们的工作验证了离散Tokenization为缓解长期存在的冷启动挑战提供了一种有效且可扩展的替代方案。
🔬 方法详解
问题定义:论文旨在解决推荐系统中物品冷启动问题,即新物品缺乏交互数据,导致传统推荐算法效果不佳。现有方法在利用多模态信息时,容易受到噪声和信息纠缠的影响,无法有效提取新物品的特征表示。
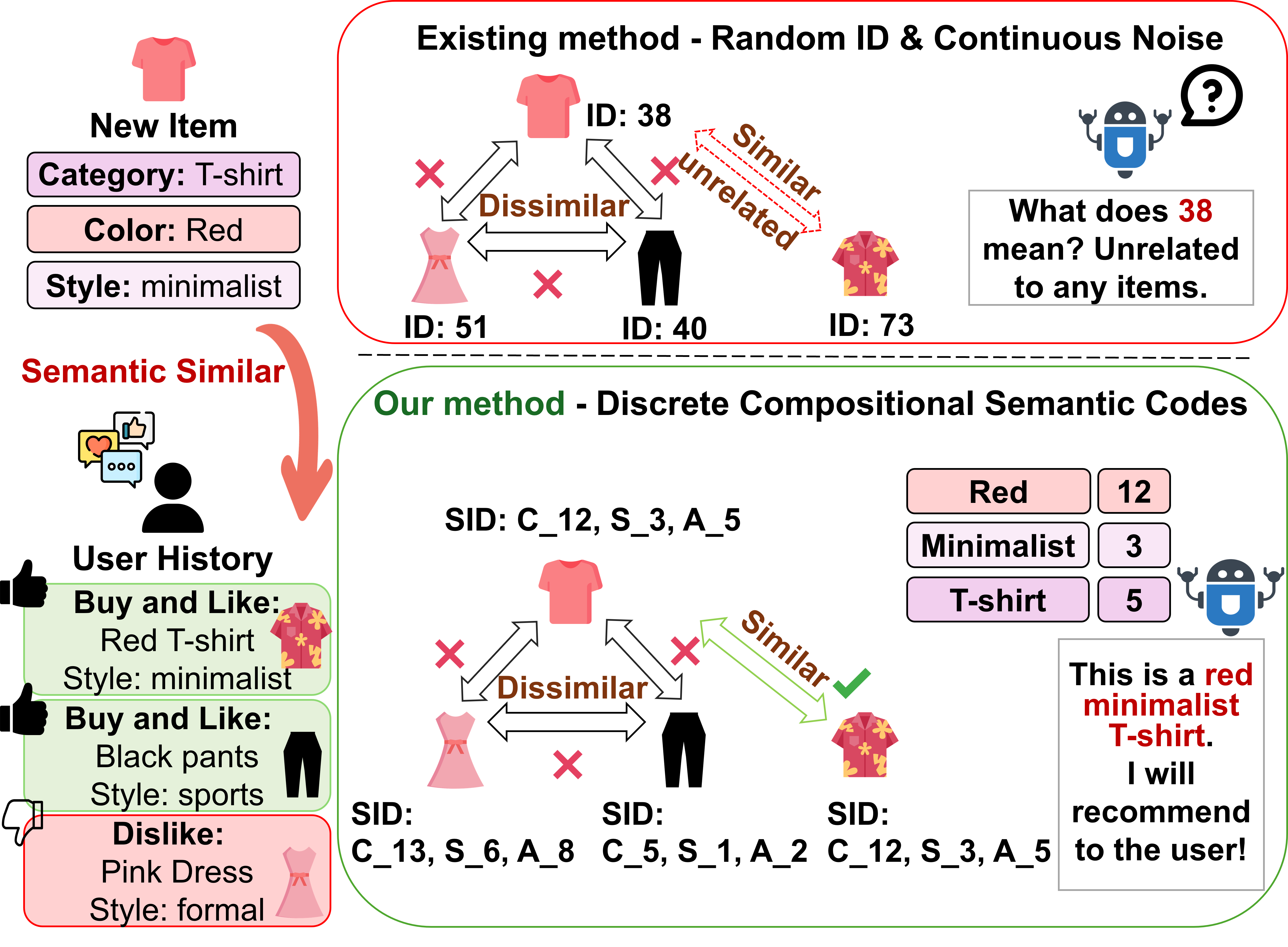
核心思路:论文的核心思路是将多模态推荐问题转化为离散语义Tokenization问题。通过学习物品的多模态内容到离散Token的映射,可以获得更鲁棒、可解释的物品表示,从而缓解冷启动问题。这种离散表示有助于解耦不同模态的信息,减少噪声干扰。
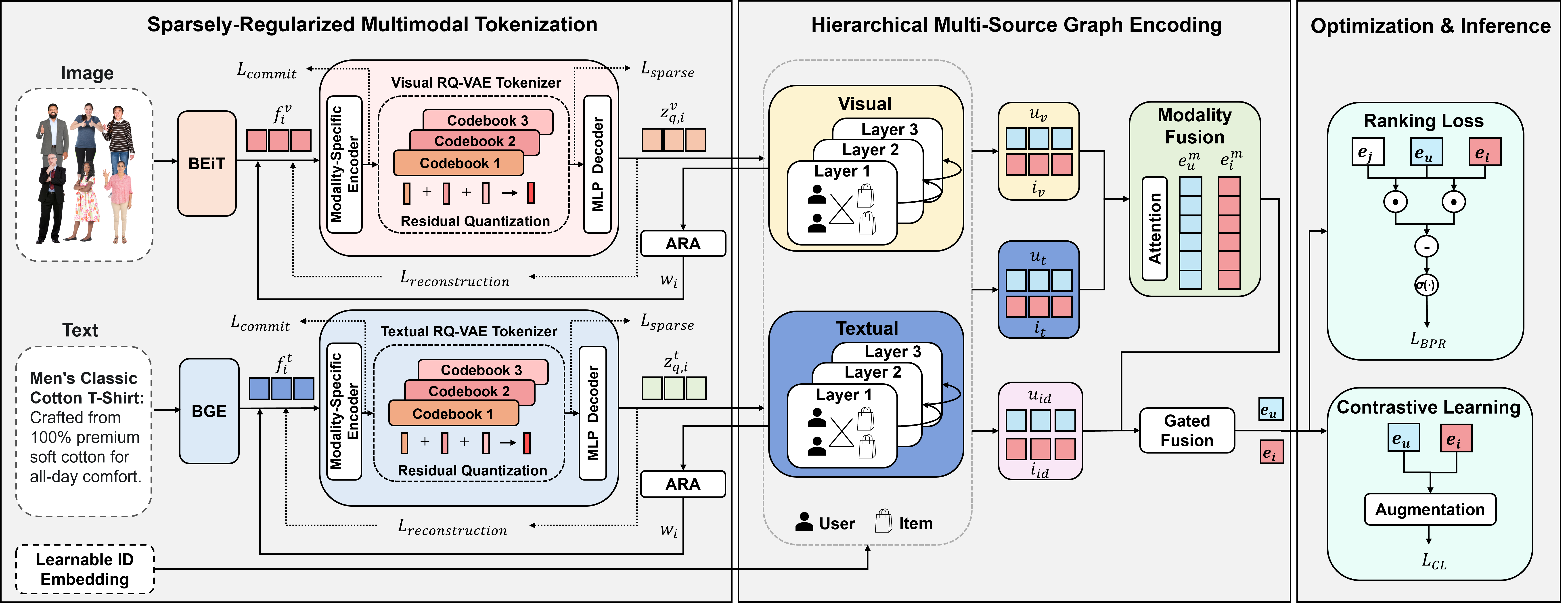
技术框架:MoToRec框架主要包含三个模块:(1) 稀疏正则化的残差量化变分自编码器(RQ-VAE),用于生成离散语义Token;(2) 自适应稀有性放大模块,用于提升冷启动物品的学习优先级;(3) 分层多源图编码器,用于融合协同信号和多模态信息。整体流程是先使用RQ-VAE将多模态内容编码为离散Token,然后结合协同信号进行图编码,最后进行推荐预测。
关键创新:论文的关键创新在于使用稀疏正则化的RQ-VAE进行多模态Tokenization。与传统的连续表示方法相比,离散Token表示更易于解耦和解释。稀疏正则化进一步约束了Token的选择,减少了冗余信息,提升了模型的泛化能力。自适应稀有性放大模块也是一个创新点,它能够根据物品的稀有程度动态调整学习权重,从而更好地处理冷启动物品。
关键设计:RQ-VAE使用残差量化技术,将连续特征向量量化为多个离散Token。稀疏正则化通过在损失函数中添加L1范数惩罚项来实现,鼓励模型选择更少的Token。自适应稀有性放大模块根据物品的交互次数计算权重,交互次数越少的物品权重越高。分层多源图编码器使用多层图卷积网络,分别处理协同图和多模态图,然后将两者的表示进行融合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MoToRec在三个大规模数据集上均取得了显著的性能提升。在冷启动场景下,MoToRec相比于最先进的方法,在Recall@20指标上平均提升了5%以上。此外,MoToRec在整体推荐性能上也优于现有方法,验证了其有效性和泛化能力。
🎯 应用场景
MoToRec可应用于各种推荐场景,尤其是在新物品或用户快速涌现的场景下,例如电商平台、新闻推荐、短视频推荐等。该方法能够有效缓解冷启动问题,提升推荐系统的整体性能和用户体验。未来,该方法可以进一步扩展到其他模态的数据,例如文本、音频等,以构建更全面的推荐系统。
📄 摘要(原文)
Graph neural networks (GNNs) have revolutionized recommender systems by effectively modeling complex user-item interactions, yet data sparsity and the item cold-start problem significantly impair performance, particularly for new items with limited or no interaction history. While multimodal content offers a promising solution, existing methods result in suboptimal representations for new items due to noise and entanglement in sparse data. To address this, we transform multimodal recommendation into discrete semantic tokenization. We present Sparse-Regularized Multimodal Tokenization for Cold-Start Recommendation (MoToRec), a framework centered on a sparsely-regularized Residual Quantized Variational Autoencoder (RQ-VAE) that generates a compositional semantic code of discrete, interpretable tokens, promoting disentangled representations. MoToRec's architecture is enhanced by three synergistic components: (1) a sparsely-regularized RQ-VAE that promotes disentangled representations, (2) a novel adaptive rarity amplification that promotes prioritized learning for cold-start items, and (3) a hierarchical multi-source graph encoder for robust signal fusion with collaborative signals. Extensive experiments on three large-scale datasets demonstrate MoToRec's superiority over state-of-the-art methods in both overall and cold-start scenarios. Our work validates that discrete tokenization provides an effective and scalable alternative for mitigating the long-standing cold-start challenge.