OSIL: Learning Offline Safe Imitation Policies with Safety Inferred from Non-preferred Trajectories
作者: Returaj Burnwal, Nirav Pravinbhai Bhatt, Balaraman Ravindran
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-11
备注: 21 pages, Accepted at AAMAS 2026
💡 一句话要点
提出OSIL算法,利用非优轨迹学习离线安全模仿策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 安全模仿学习 约束马尔可夫决策过程 非优轨迹 安全策略 机器人控制
📋 核心要点
- 现有安全模仿学习方法依赖于精确的安全代价标注,但在实际应用中,获取这些标注往往困难且成本高昂。
- OSIL算法通过利用非优轨迹来推断安全性,将安全策略学习建模为约束马尔可夫决策过程,并学习代价模型。
- 实验结果表明,OSIL算法能够在不降低奖励性能的前提下,学习到满足代价约束的更安全策略,性能优于现有基线。
📝 摘要(中文)
本文研究离线安全模仿学习(IL)问题,目标是从不包含每步安全代价或奖励信息的演示数据中学习安全且奖励最大化的策略。在许多实际领域中,在线环境学习具有风险,且难以指定准确的安全代价。然而,收集反映不良或不安全行为的轨迹通常是可行的,这些轨迹隐式地传达了智能体应该避免的内容,我们称之为非优轨迹。我们提出了一种新的离线安全IL算法OSIL,该算法从非优演示中推断安全性。我们将安全策略学习建模为约束马尔可夫决策过程(CMDP)。OSIL没有依赖显式的安全代价和奖励标注,而是通过推导奖励最大化目标的下界并学习估计非优行为可能性的代价模型来重新构建CMDP问题。我们的方法允许智能体完全从离线演示中学习安全且奖励最大化的行为。实验结果表明,我们的方法可以学习满足代价约束且不降低奖励性能的更安全策略,从而优于多个基线。
🔬 方法详解
问题定义:论文旨在解决离线安全模仿学习问题,即在没有每一步安全代价或奖励信息的情况下,如何从离线数据中学习既能最大化奖励又能保证安全的策略。现有方法的痛点在于需要显式的安全代价标注,而这些标注在实际应用中往往难以获取或不准确。
核心思路:论文的核心思路是利用非优轨迹(即智能体应该避免的行为轨迹)来隐式地学习安全约束。通过学习一个代价模型来估计非优行为的可能性,从而避免显式地指定安全代价。这种方法允许智能体仅从离线演示数据中学习安全策略。
技术框架:OSIL算法将安全策略学习建模为约束马尔可夫决策过程(CMDP)。算法主要包含以下几个阶段:1) 从非优轨迹中学习代价模型,该模型用于估计给定状态下采取某个动作导致非优行为的概率;2) 推导奖励最大化目标的下界,该下界考虑了安全约束;3) 使用离线数据训练策略,目标是最大化奖励下界,同时满足安全约束。
关键创新:最重要的技术创新点在于利用非优轨迹来推断安全性,从而避免了对显式安全代价标注的依赖。与现有方法相比,OSIL能够从更易于获取的非优数据中学习安全策略,降低了数据标注的成本。
关键设计:代价模型可以使用各种机器学习方法进行训练,例如分类器或回归器。奖励最大化目标的下界可以通过拉格朗日对偶方法进行优化,将约束优化问题转化为无约束优化问题。策略可以使用各种离线强化学习算法进行训练,例如行为克隆或策略约束策略优化。
🖼️ 关键图片
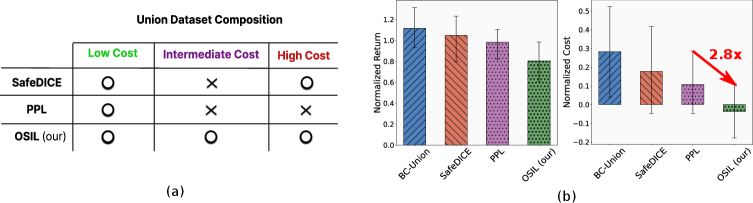
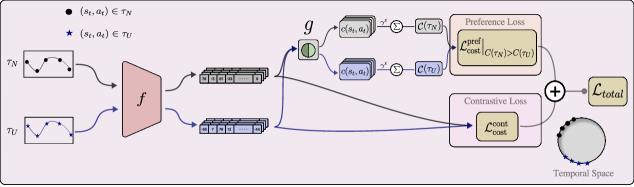
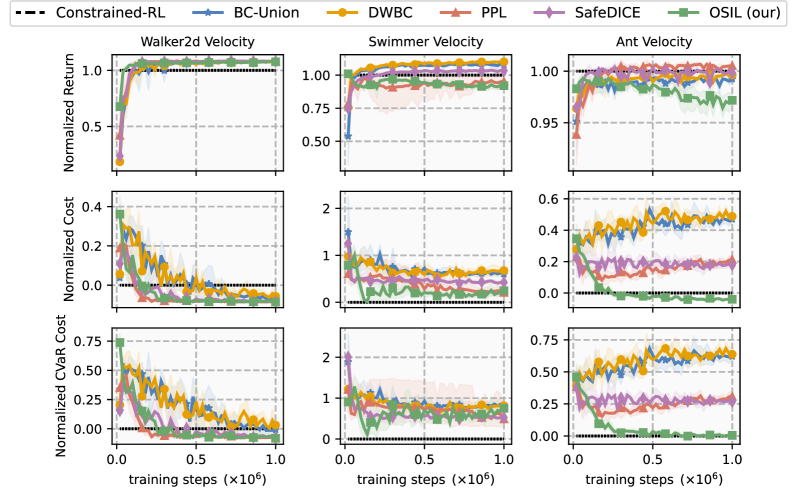
📊 实验亮点
实验结果表明,OSIL算法在多个模拟环境中能够学习到比现有基线更安全的策略,同时保持了较高的奖励性能。具体而言,OSIL算法能够在满足代价约束的前提下,达到与无安全约束的模仿学习算法相近的奖励水平,显著优于依赖显式安全代价标注的算法。
🎯 应用场景
OSIL算法可应用于各种需要安全保障的机器人控制任务,例如自动驾驶、医疗机器人、工业机器人等。在这些场景中,收集非优轨迹通常比标注精确的安全代价更容易。该算法能够帮助智能体在没有显式安全指导的情况下,学习安全可靠的行为策略,从而降低事故风险,提高系统安全性。
📄 摘要(原文)
This work addresses the problem of offline safe imitation learning (IL), where the goal is to learn safe and reward-maximizing policies from demonstrations that do not have per-timestep safety cost or reward information. In many real-world domains, online learning in the environment can be risky, and specifying accurate safety costs can be difficult. However, it is often feasible to collect trajectories that reflect undesirable or unsafe behavior, implicitly conveying what the agent should avoid. We refer to these as non-preferred trajectories. We propose a novel offline safe IL algorithm, OSIL, that infers safety from non-preferred demonstrations. We formulate safe policy learning as a Constrained Markov Decision Process (CMDP). Instead of relying on explicit safety cost and reward annotations, OSIL reformulates the CMDP problem by deriving a lower bound on reward maximizing objective and learning a cost model that estimates the likelihood of non-preferred behavior. Our approach allows agents to learn safe and reward-maximizing behavior entirely from offline demonstrations. We empirically demonstrate that our approach can learn safer policies that satisfy cost constraints without degrading the reward performance, thus outperforming several baselines.