Resource-Efficient Model-Free Reinforcement Learning for Board Games
作者: Kazuki Ota, Takayuki Osa, Motoki Omura, Tatsuya Harada
分类: cs.LG, cs.AI
发布日期: 2026-02-11
💡 一句话要点
提出一种资源高效的免模型强化学习算法,用于解决棋盘游戏中的决策问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 免模型强化学习 棋盘游戏 资源高效 策略学习 价值评估
📋 核心要点
- 基于搜索的强化学习方法(如AlphaZero)在棋盘游戏中取得了显著成功,但其巨大的计算需求限制了其可复现性。
- 论文提出一种免模型强化学习算法,旨在通过更高效的学习方式,降低对计算资源的需求,适用于多种棋盘游戏。
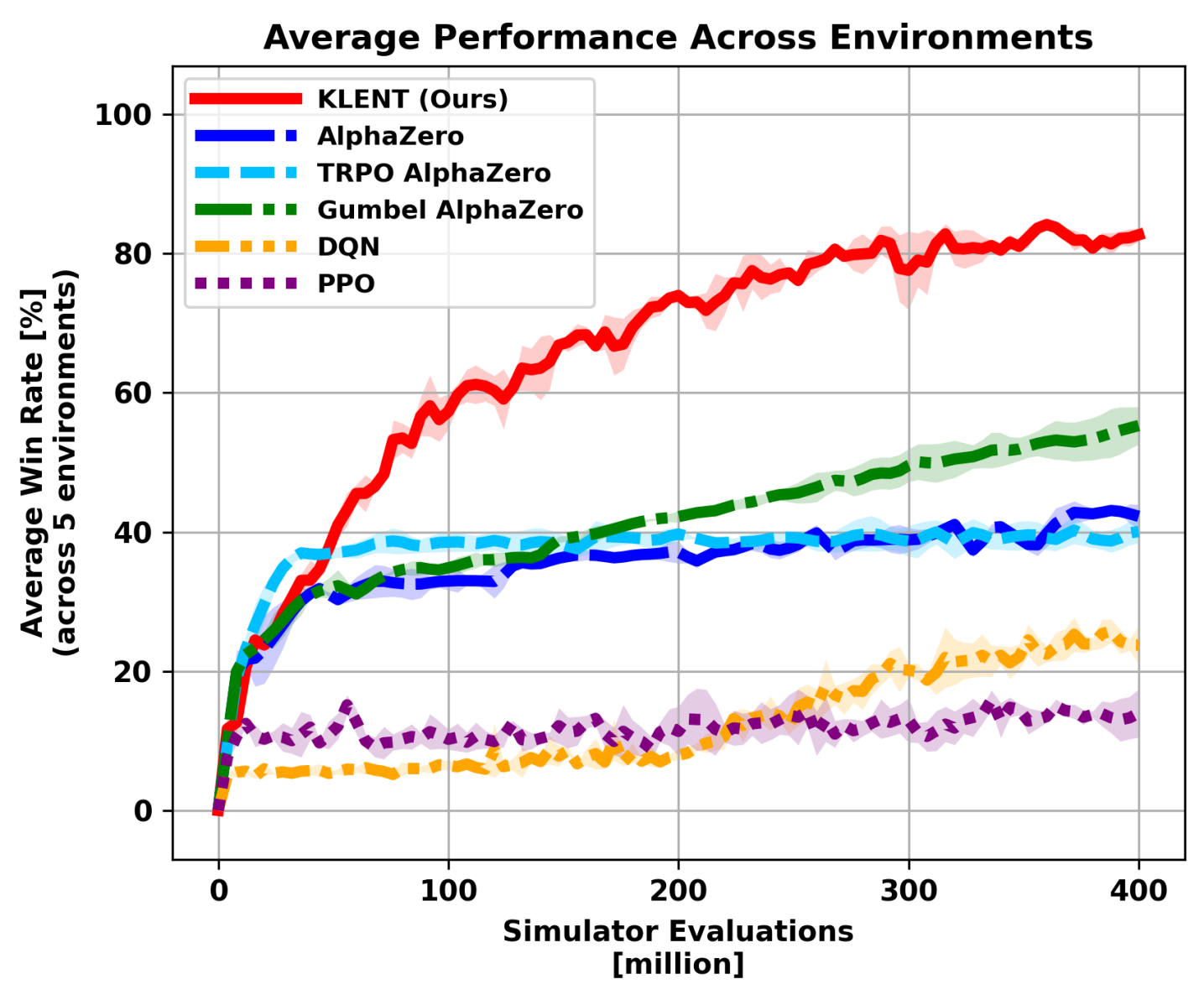
- 实验结果表明,该方法在多种棋盘游戏中比现有方法更有效,消融实验验证了核心技术的重要性。
📝 摘要(中文)
本文提出了一种专为棋盘游戏设计的免模型强化学习算法,旨在实现更高效的学习。在五种棋盘游戏(动物将棋、Gardner象棋、围棋、Hex和奥赛罗)上进行了全面的实验,验证了该方法的有效性。结果表明,与现有方法相比,该方法在这些环境中实现了更高效的学习。此外,深入的消融研究揭示了该方法中所用核心技术的重要性。我们相信,这种高效的算法展示了免模型强化学习在传统上由基于搜索的方法主导的领域中的潜力。
🔬 方法详解
问题定义:论文旨在解决棋盘游戏中使用强化学习时计算资源需求过大的问题。现有基于搜索的强化学习方法,如AlphaZero,虽然性能优异,但需要大量的计算资源进行训练和推理,这限制了其在资源受限环境下的应用和复现性。
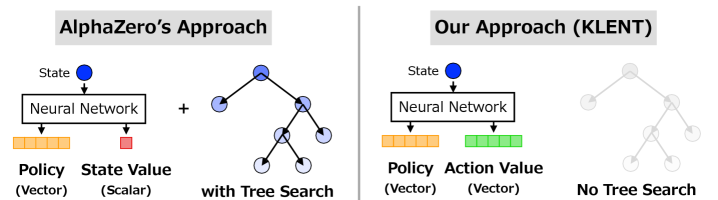
核心思路:论文的核心思路是利用免模型强化学习算法,避免显式地构建和维护游戏模型,从而降低计算复杂度。通过直接从经验中学习策略,减少对大量模拟和搜索的依赖。
技术框架:该方法采用免模型强化学习框架,主要包括以下几个阶段:1)与环境交互,收集经验数据;2)利用收集到的经验数据更新策略网络和价值网络;3)使用更新后的策略网络进行决策,选择下一步行动。整个过程循环进行,直到策略收敛。
关键创新:该方法的关键创新在于针对棋盘游戏的特点,设计了高效的策略学习和价值评估机制。具体来说,可能包括:1)使用更紧凑的网络结构,减少参数量;2)采用更有效的探索策略,加速学习过程;3)利用棋盘游戏的对称性等先验知识,提高样本利用率。与现有方法的本质区别在于,该方法不需要进行大量的蒙特卡洛树搜索等计算密集型操作。
关键设计:具体的参数设置、损失函数和网络结构等技术细节在论文中应该有详细描述。例如,策略网络和价值网络的具体结构(如卷积层数、全连接层数等),损失函数的选择(如交叉熵损失、均方误差损失等),以及优化器的选择(如Adam、SGD等)。此外,探索策略(如ε-greedy、UCB等)的参数设置也会影响算法的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在动物将棋、Gardner象棋、围棋、Hex和奥赛罗五种棋盘游戏中均取得了比现有方法更高效的学习效果。具体的性能提升幅度需要在论文中查找,例如,可能在达到相同水平的性能时,所需的训练时间和计算资源显著减少。
🎯 应用场景
该研究成果可应用于各种棋盘游戏AI的开发,尤其适用于资源受限的平台,如移动设备或嵌入式系统。此外,该方法在降低计算复杂度的思路,可以推广到其他需要进行复杂决策的领域,例如机器人控制、自动驾驶和资源调度等。
📄 摘要(原文)
Board games have long served as complex decision-making benchmarks in artificial intelligence. In this field, search-based reinforcement learning methods such as AlphaZero have achieved remarkable success. However, their significant computational demands have been pointed out as barriers to their reproducibility. In this study, we propose a model-free reinforcement learning algorithm designed for board games to achieve more efficient learning. To validate the efficiency of the proposed method, we conducted comprehensive experiments on five board games: Animal Shogi, Gardner Chess, Go, Hex, and Othello. The results demonstrate that the proposed method achieves more efficient learning than existing methods across these environments. In addition, our extensive ablation study shows the importance of core techniques used in the proposed method. We believe that our efficient algorithm shows the potential of model-free reinforcement learning in domains traditionally dominated by search-based methods.