Time Series Foundation Models for Energy Load Forecasting on Consumer Hardware: A Multi-Dimensional Zero-Shot Benchmark
作者: Luigi Simeone
分类: cs.LG, cs.AI
发布日期: 2026-02-11
备注: 27 pages, 13 figures
💡 一句话要点
提出能源负荷预测零样本基准,评估时间序列预训练模型在消费级硬件上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 预训练模型 零样本学习 电力负荷预测 基准测试 能源管理 分布偏移 概率预测
📋 核心要点
- 电力负荷预测对电网稳定至关重要,现有方法依赖大量特定任务数据,泛化能力受限。
- 论文提出多维度基准,评估时间序列预训练模型在零样本电力负荷预测中的性能,无需微调。
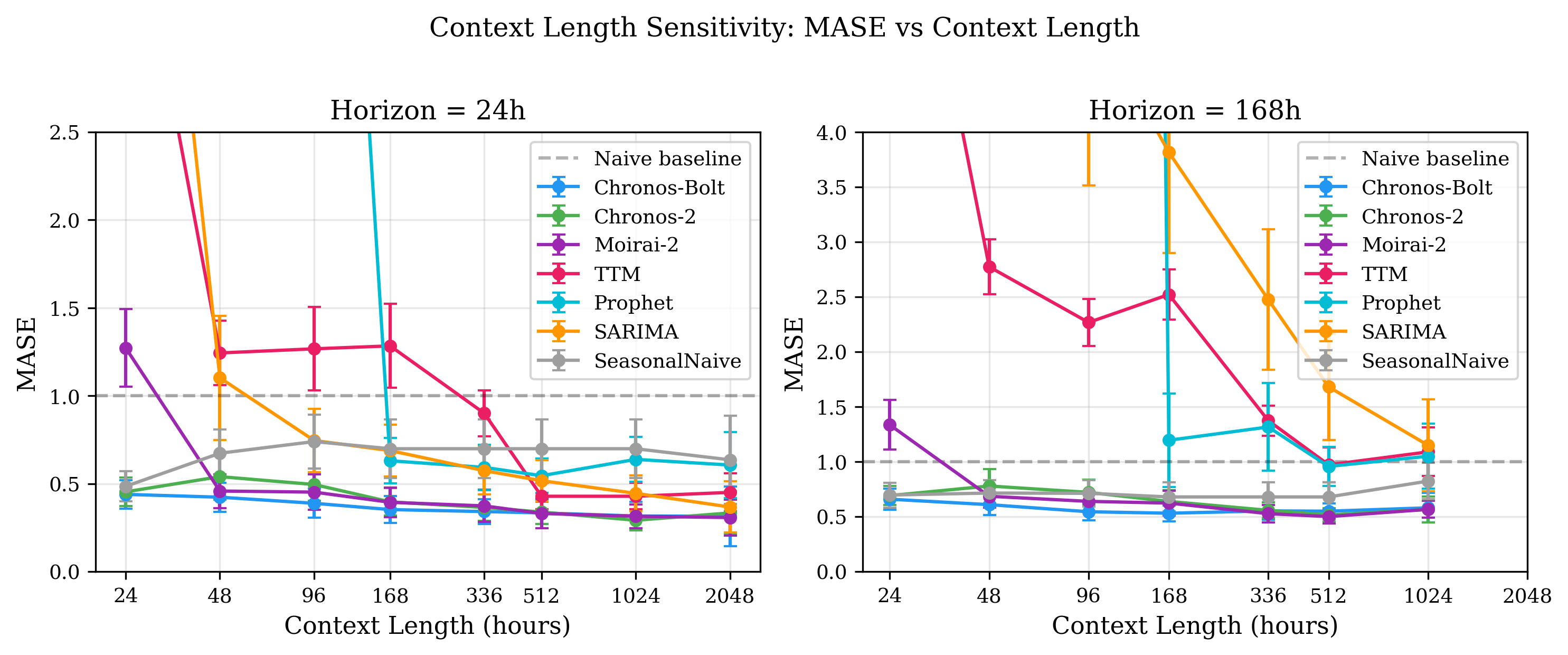
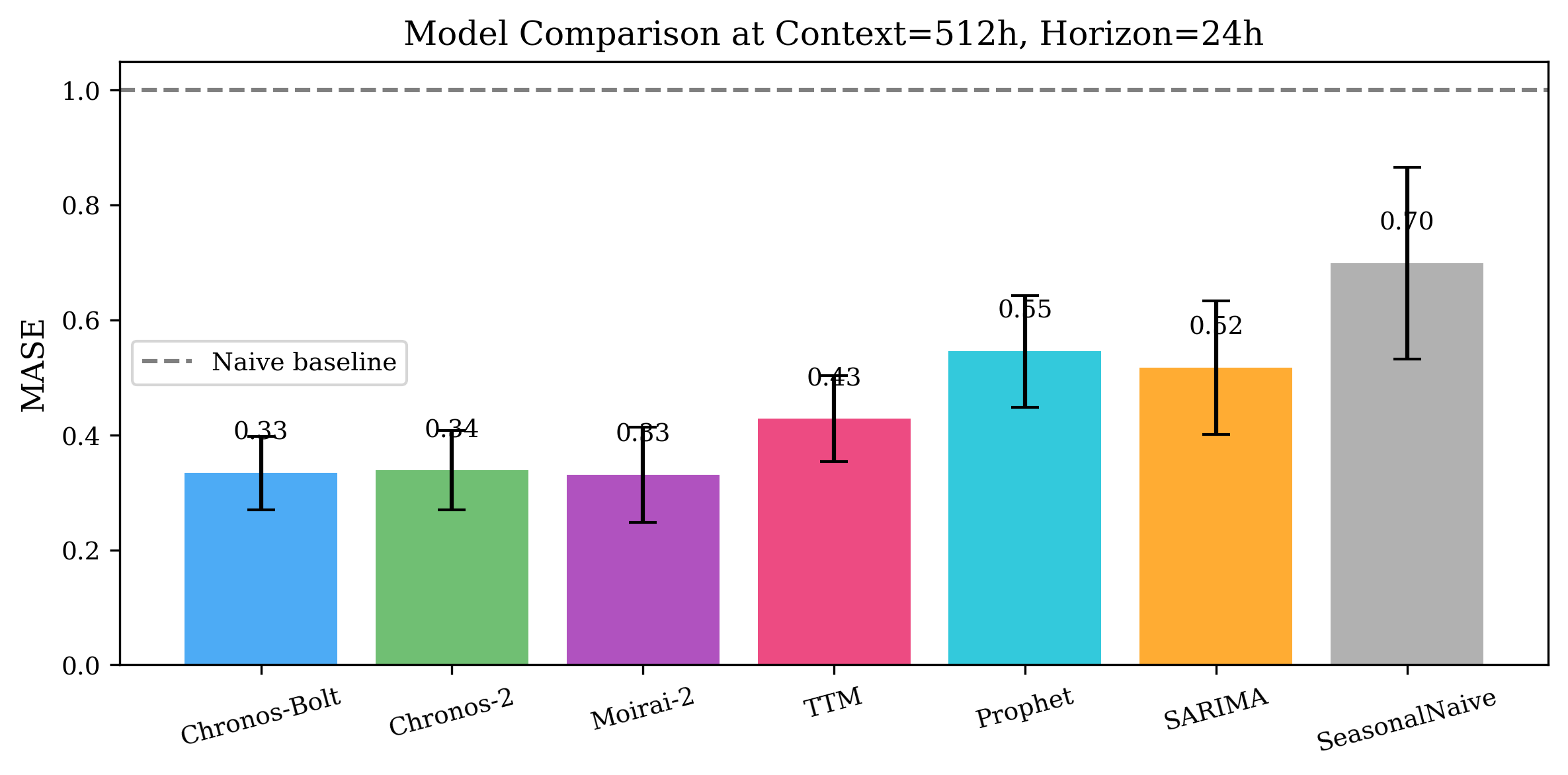
- 实验表明,预训练模型在长上下文下优于传统方法,且对分布偏移更鲁棒,但校准性差异大。
📝 摘要(中文)
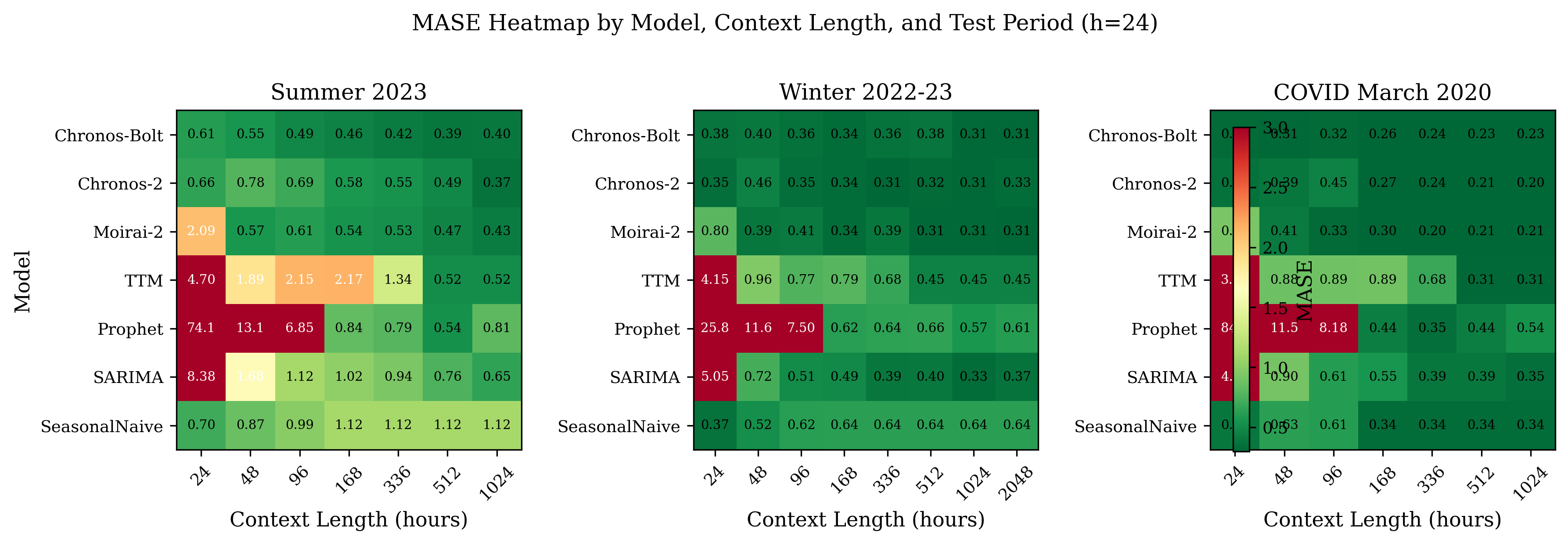
时间序列预训练模型(TSFMs)引入了零样本预测能力,无需针对特定任务进行训练。这些能力是否能应用于电力需求预测等关键任务,仍然是一个开放的问题,因为在这些任务中,准确性、校准性和鲁棒性直接影响电网运行。我们提出了一个多维度基准,使用2020年至2024年的ERCOT小时负荷数据,评估了四个TSFM(Chronos-Bolt、Chronos-2、Moirai-2和TinyTimeMixer),以及Prophet(行业标准基线)和两个统计参考模型(SARIMA和季节性朴素模型)。所有实验均在消费级硬件上运行(AMD Ryzen 7,16GB RAM,无GPU)。评估涵盖四个方面:(1)24到2048小时的上下文长度敏感性,(2)概率预测校准,(3)包括COVID-19封锁和冬季风暴Uri在内的分布偏移下的鲁棒性,以及(4)用于运营决策支持的规范分析。性能最佳的预训练模型在长上下文长度(C = 2048h,提前一天预测)下实现了接近0.31的MASE值,比季节性朴素基线降低了47%。Prophet的包含揭示了预训练模型的结构优势:当拟合窗口短于其季节性周期时,Prophet失效(24小时上下文下的MASE > 74),而TSFM即使在最小上下文下也能保持稳定的准确性,因为它们识别在预训练期间学习到的时间模式,而不是从头开始估计它们。不同模型的校准差异很大——Chronos-2产生良好校准的预测区间(90%标称水平下95%的经验覆盖率),而Moirai-2和Prophet都表现出过度自信(~70%覆盖率)。我们提供了实用的模型选择指南,并发布了完整的基准框架以供重现。
🔬 方法详解
问题定义:论文旨在评估时间序列预训练模型(TSFMs)在电力负荷预测任务中的零样本泛化能力。现有方法,如Prophet和SARIMA,需要大量特定任务的数据进行训练或参数估计,并且在面对分布偏移(如COVID-19封锁或极端天气事件)时表现不佳。这些方法难以捕捉长期的时间依赖关系,且计算成本较高。
核心思路:论文的核心思路是利用TSFMs在大量时间序列数据上预训练获得的通用时间模式表示能力,直接应用于电力负荷预测任务,无需针对特定数据集进行微调。通过评估TSFMs在不同上下文长度、分布偏移和校准性方面的表现,分析其在实际应用中的潜力。这种方法旨在克服传统方法对特定数据的依赖,提高模型的泛化能力和鲁棒性。
技术框架:该研究构建了一个多维度基准测试框架,用于评估TSFMs在电力负荷预测中的性能。该框架包括以下主要组成部分:1) 数据集:使用ERCOT(德克萨斯州电力可靠性委员会)的2020年至2024年小时负荷数据。2) 模型:评估四个TSFM(Chronos-Bolt、Chronos-2、Moirai-2和TinyTimeMixer),以及Prophet、SARIMA和季节性朴素模型作为基线。3) 评估指标:使用MASE(平均绝对比例误差)评估预测准确性,使用经验覆盖率评估概率预测的校准性。4) 实验设置:在消费级硬件上运行所有实验,并评估模型在不同上下文长度(24到2048小时)和分布偏移下的表现。
关键创新:该研究的关键创新在于构建了一个全面的零样本电力负荷预测基准,并系统地评估了TSFMs的性能。与以往的研究相比,该研究不仅关注预测准确性,还关注模型的校准性和鲁棒性。此外,该研究还强调了在消费级硬件上运行实验的重要性,这使得该基准更具实用价值。
关键设计:在实验设计方面,论文考虑了以下关键因素:1) 上下文长度:评估模型在不同上下文长度下的预测性能,以了解模型对长期时间依赖关系的捕捉能力。2) 分布偏移:通过引入COVID-19封锁和冬季风暴Uri等事件,评估模型在面对分布偏移时的鲁棒性。3) 校准性:使用经验覆盖率评估模型预测区间的可靠性。4) 基线选择:选择Prophet、SARIMA和季节性朴素模型作为基线,以全面评估TSFMs的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在长上下文长度(2048小时)下,性能最佳的TSFM实现了接近0.31的MASE值,比季节性朴素基线降低了47%。Chronos-2产生了良好校准的预测区间(90%标称水平下95%的经验覆盖率),而Moirai-2和Prophet都表现出过度自信(~70%覆盖率)。Prophet在短上下文下表现不佳(MASE > 74),而TSFM保持了稳定的准确性。
🎯 应用场景
该研究成果可应用于智能电网的优化运行、能源市场的预测和风险管理、以及电力系统的规划和维护。通过利用预训练模型,可以降低对特定数据的依赖,提高预测的准确性和鲁棒性,从而提高电网的效率和可靠性,并为能源决策提供更可靠的依据。未来的研究可以探索如何进一步提高预训练模型的校准性和可解释性。
📄 摘要(原文)
Time Series Foundation Models (TSFMs) have introduced zero-shot prediction capabilities that bypass the need for task-specific training. Whether these capabilities translate to mission-critical applications such as electricity demand forecasting--where accuracy, calibration, and robustness directly affect grid operations--remains an open question. We present a multi-dimensional benchmark evaluating four TSFMs (Chronos-Bolt, Chronos-2, Moirai-2, and TinyTimeMixer) alongside Prophet as an industry-standard baseline and two statistical references (SARIMA and Seasonal Naive), using ERCOT hourly load data from 2020 to 2024. All experiments run on consumer-grade hardware (AMD Ryzen 7, 16GB RAM, no GPU). The evaluation spans four axes: (1) context length sensitivity from 24 to 2048 hours, (2) probabilistic forecast calibration, (3) robustness under distribution shifts including COVID-19 lockdowns and Winter Storm Uri, and (4) prescriptive analytics for operational decision support. The top-performing foundation models achieve MASE values near 0.31 at long context lengths (C = 2048h, day-ahead horizon), a 47% reduction over the Seasonal Naive baseline. The inclusion of Prophet exposes a structural advantage of pre-trained models: Prophet fails when the fitting window is shorter than its seasonality period (MASE > 74 at 24-hour context), while TSFMs maintain stable accuracy even with minimal context because they recognise temporal patterns learned during pre-training rather than estimating them from scratch. Calibration varies substantially across models--Chronos-2 produces well-calibrated prediction intervals (95% empirical coverage at 90% nominal level) while both Moirai-2 and Prophet exhibit overconfidence (~70% coverage). We provide practical model selection guidelines and release the complete benchmark framework for reproducibility.