RePO: Bridging On-Policy Learning and Off-Policy Knowledge through Rephrasing Policy Optimization
作者: Linxuan Xia, Xiaolong Yang, Yongyuan Chen, Enyue Zhao, Deng Cai, Yasheng Wang, Boxi Wu
分类: cs.LG
发布日期: 2026-02-11
💡 一句话要点
RePO:通过重述策略优化桥接在线学习与离线知识,提升LLM领域知识对齐效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 离线学习 在线学习 策略优化 领域知识对齐 提示学习
📋 核心要点
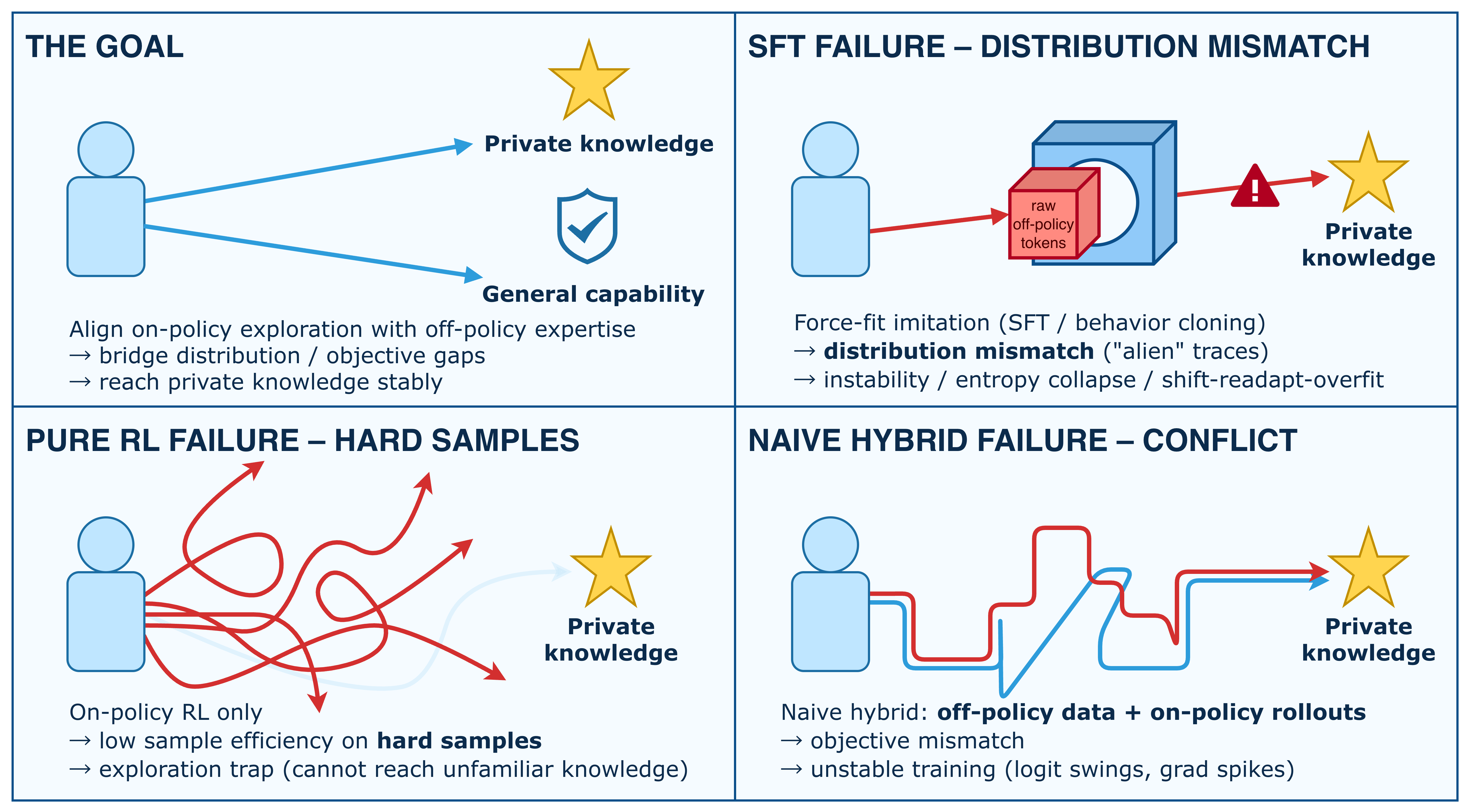
- 现有方法在领域知识对齐方面存在不足,监督微调降低泛化性,在线强化学习难以吸收困难样本。
- RePO的核心思想是让模型理解离线知识,并将其重述为符合自身分布的轨迹,从而稳定训练过程。
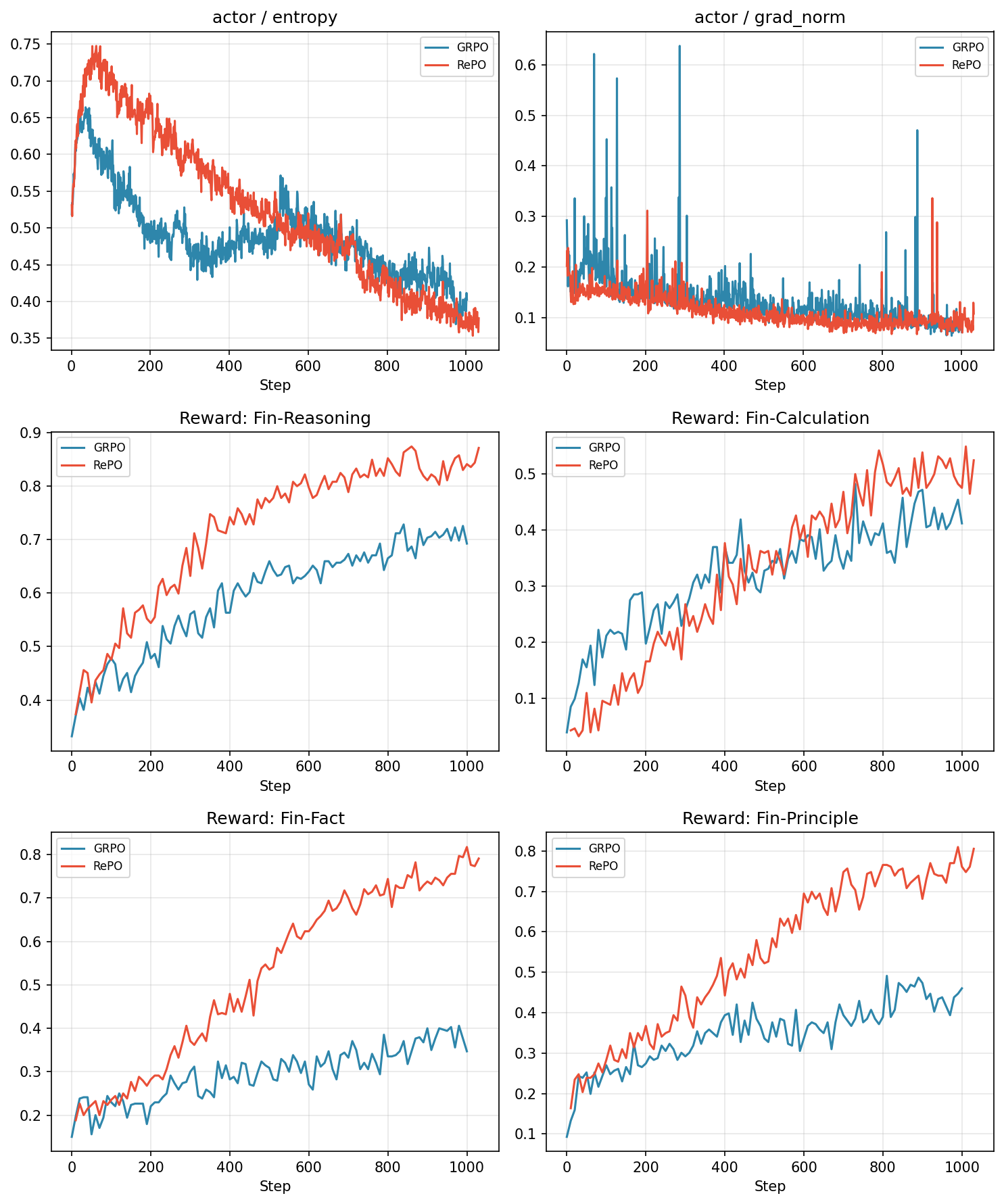
- 实验结果表明,RePO能有效利用困难样本,并在多个基准测试中超越现有方法,达到最佳性能。
📝 摘要(中文)
在特定领域数据上对齐大型语言模型(LLMs)仍然是一个根本性的挑战。监督微调(SFT)提供了一种直接注入领域知识的方法,但通常会降低模型的泛化能力。相比之下,在线强化学习(RL)保留了泛化能力,但无法有效吸收超出模型当前推理水平的困难样本。最近的离线RL尝试改进了困难样本的利用率,但由于强制将分布转移到离线知识,因此存在严重的训练不稳定性。为了协调有效的离线知识吸收与在线RL的稳定性,我们提出了重述策略优化(RePO)。在RePO中,策略模型首先被提示理解离线知识,然后将其重述为符合其自身风格和参数分布的轨迹。RePO动态地用这些重述的高质量轨迹替换低奖励的rollout。这种策略引导模型朝着正确的推理路径前进,同时严格保持在线训练动态。在多个基准测试上的实验表明,RePO提高了困难样本的利用率,并且优于现有的基线,实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在特定领域数据上对齐的问题。现有方法,如监督微调(SFT),虽然能快速注入领域知识,但会牺牲模型的泛化能力。而传统的在线强化学习(RL)方法虽然能保持泛化性,但难以有效利用那些超出模型当前推理能力的“困难样本”。离线强化学习虽然尝试利用这些困难样本,但容易导致训练不稳定,因为其策略分布与在线策略差异过大。
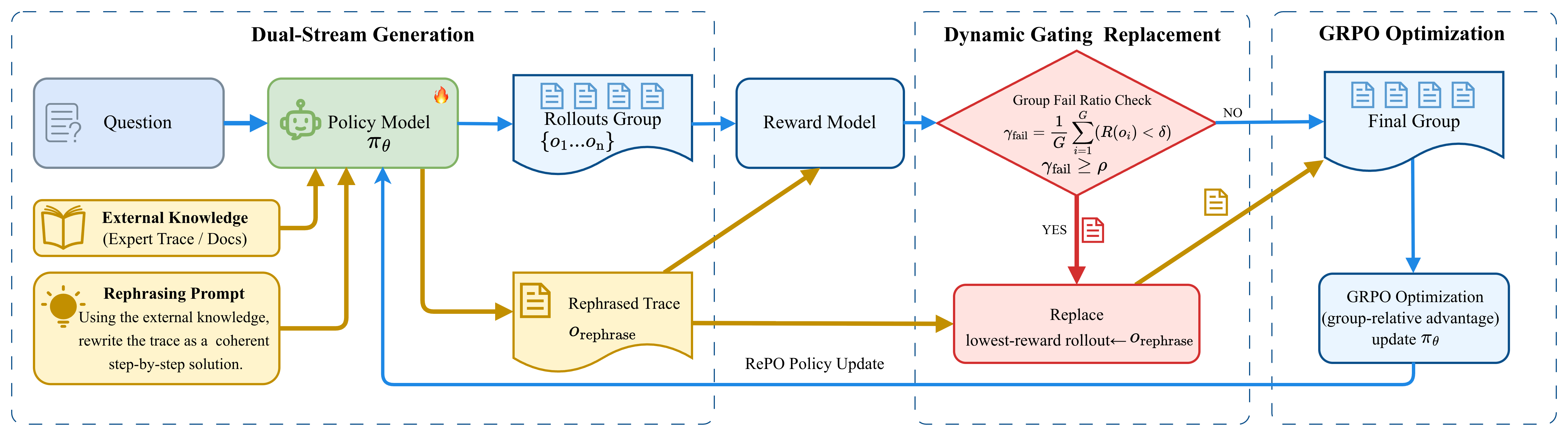
核心思路:RePO的核心思路是让策略模型首先“理解”离线知识,然后将这些知识“重述”成符合其自身风格和参数分布的轨迹。这样,模型就可以在吸收离线知识的同时,保持在线学习的稳定性。通过将离线知识转化为模型更容易理解和接受的形式,避免了直接强制改变策略分布带来的问题。
技术框架:RePO的整体框架包含以下几个关键步骤:1) 从离线数据集中采样困难样本;2) 使用提示工程(Prompt Engineering)引导策略模型理解这些困难样本,并生成相应的“重述”轨迹;3) 使用这些重述轨迹替换在线RL中低奖励的rollout;4) 使用标准的在线RL算法(如PPO)更新策略模型。这个过程动态地将高质量的离线知识融入到在线学习过程中。
关键创新:RePO最重要的创新在于其“重述”机制。它避免了直接使用离线数据训练策略模型,而是让模型主动学习如何将离线知识转化为自身可以理解和利用的形式。这种方法既能利用离线知识,又能保持在线学习的稳定性,从而避免了传统离线RL方法中常见的训练崩溃问题。与直接模仿离线数据不同,RePO鼓励模型进行创造性的“知识迁移”。
关键设计:RePO的关键设计包括:1) 如何设计有效的提示(Prompt)来引导模型理解离线知识;2) 如何选择需要替换的低奖励rollout;3) 如何平衡在线学习和离线知识的利用。论文中可能涉及一些超参数的设置,例如提示的长度、替换rollout的比例等。损失函数方面,RePO仍然使用标准的在线RL损失函数(如PPO的Clip Loss),但会根据重述轨迹的质量进行加权。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RePO在多个基准测试中均优于现有方法,实现了state-of-the-art的性能。具体而言,RePO在困难样本利用率方面有显著提升,并且在保持模型泛化能力的同时,有效吸收了离线知识。相较于传统的在线RL和离线RL方法,RePO在性能和稳定性方面都取得了更好的平衡。
🎯 应用场景
RePO具有广泛的应用前景,可用于各种需要将大型语言模型与特定领域知识对齐的场景,例如医疗诊断、金融分析、法律咨询等。通过有效利用领域内的专家知识和高质量数据,RePO可以显著提升LLM在这些领域的性能和可靠性,加速人工智能在专业领域的落地。
📄 摘要(原文)
Aligning large language models (LLMs) on domain-specific data remains a fundamental challenge. Supervised fine-tuning (SFT) offers a straightforward way to inject domain knowledge but often degrades the model's generality. In contrast, on-policy reinforcement learning (RL) preserves generality but fails to effectively assimilate hard samples that exceed the model's current reasoning level. Recent off-policy RL attempts improve hard sample utilization, yet they suffer from severe training instability due to the forced distribution shift toward off-policy knowledge. To reconcile effective off-policy knowledge absorption with the stability of on-policy RL, we propose Rephrasing Policy Optimization (RePO). In RePO, the policy model is prompted to first comprehend off-policy knowledge and then rephrase it into trajectories that conform to its own stylistic and parametric distribution. RePO dynamically replaces low-reward rollouts with these rephrased, high-quality trajectories. This strategy guides the model toward correct reasoning paths while strictly preserving on-policy training dynamics. Experiments on several benchmarks demonstrate that RePO improves hard-sample utilization and outperforms existing baselines, achieving state-of-the-art performance.